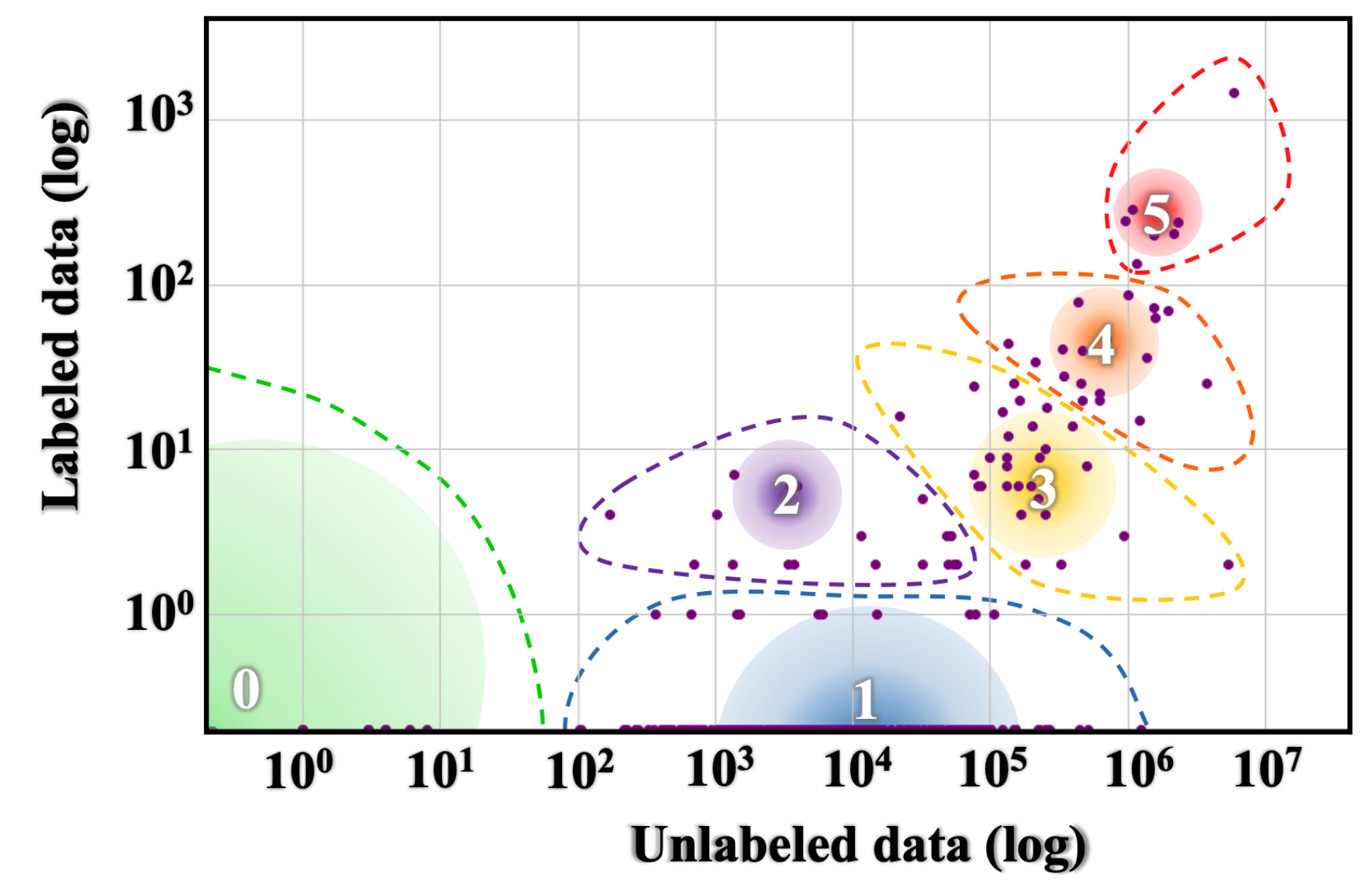
mindmap
root((Eval–UA–tion))
UA–CBT
x["`LMentry–static–UA (LMES)`"]
i{{LOW}}
i{{WIS}}
i[CATS–BIN]
i[CATS–MC]
i(WordAlpha)
i(WordLength)
UP–Titles
masked
unmasked
Eval-UA-tion
A Benchmark for the Evaluation of
Ukrainian Language Models



Serhii Hamotskyi*, Anna-Izabella Levbarg†, Christian Hänig*
* Anhalt University of Applied Sciences
† University of Greifswald
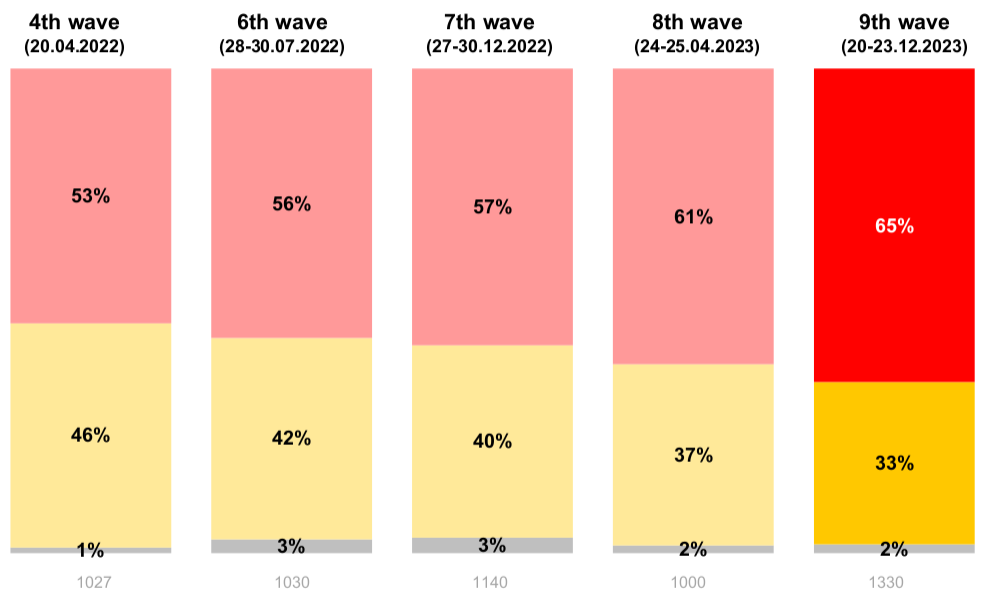
Ukrainian Use is Increasing
- Ukrainian use is increasing since 2014, with the changes after 24.02.2022 especially sharp and still ongoing (Fig. 1).
- A 2020 survey placed Ukrainian among languages with a thriving online community benefitting from unlabeled data, but let down by insufficient labeled data [1]. More quality labeled datasets are a universal good, but especially so for underresourced languages.
Ukrainian is a Challenge for LLMs
- Our CBT-UA task involved manually correcting LLM-generated stories — every one of them had errors in the text. The before/after dataset1 is on the HF Hub.
- Many errors involved Russian-language interference (Russian words, gender agreement issues in words where Ukrainian and Russian genders differ…)
- GPT-4 and Gemini Pro had trouble with longer texts, but smaller LLMs fared even worse.
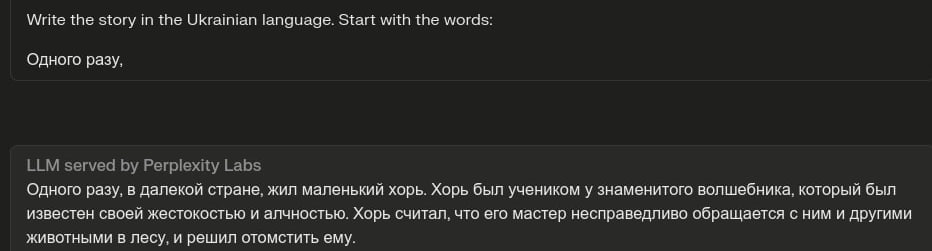
(llama2-70b-chat on https://labs.perplexity.ai)
Tasks
1. UA-CBT
(Ukrainian Children’s Book Test)
UA-CBT – Sample

- The Usurer (loan shark) hired the Hunter to kill the Snake.
- Was the Usurer angry about the death of the Snake or of his friend the Hunter?
UA-CBT – Stories Generation






All public domain.
UA-CBT – Templates

- a tricky mouse not learning anything
- a wise cat helping their mentor with a recurring problem
- a rich camel resolving a dispute about lost food
- a lazy turtle proving they are a good tailor
UA-CBT – Stories Generation
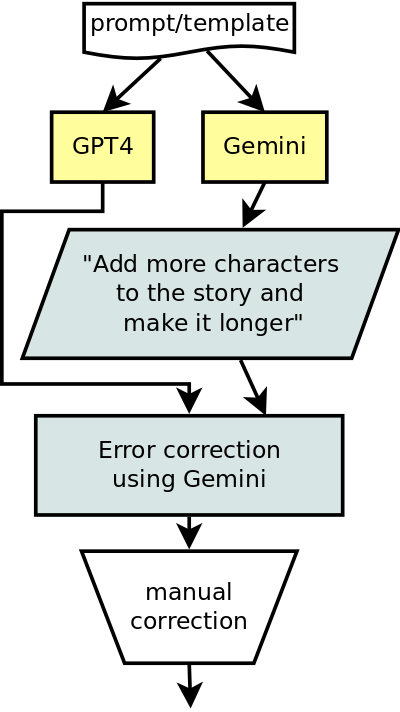
- Part of the stories were generated with GPT-4, part with Gemini Pro
- Gemini Pro wrote better Ukrainian, GPT-4 was better at following orders
- The system used the strength of both: Gemini had an additional prompt to make it longer, and all the stories were piped through it at the end for grammar and consistency
- English-language prompts were used (so no agreement issues harder than a/an animal)
- Half of the prompts asked for unhappy endings: this seemed to result in more creative stories
2. LMentry-static-UA (LMES)
3. UP-Titles
(Ukrainska Pravda–Titles)
Baselines and Human Evaluation
Annotation and Human Evaluation
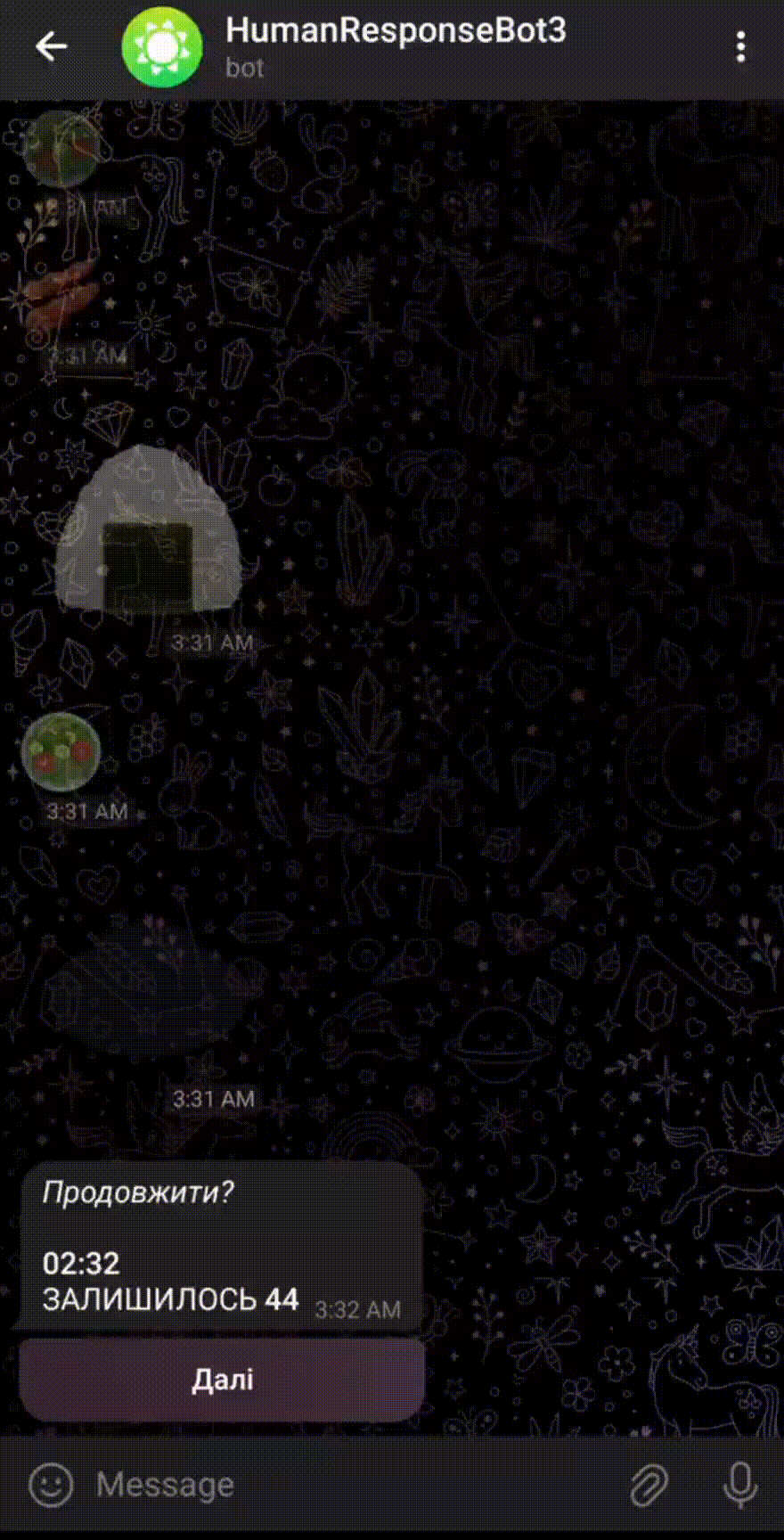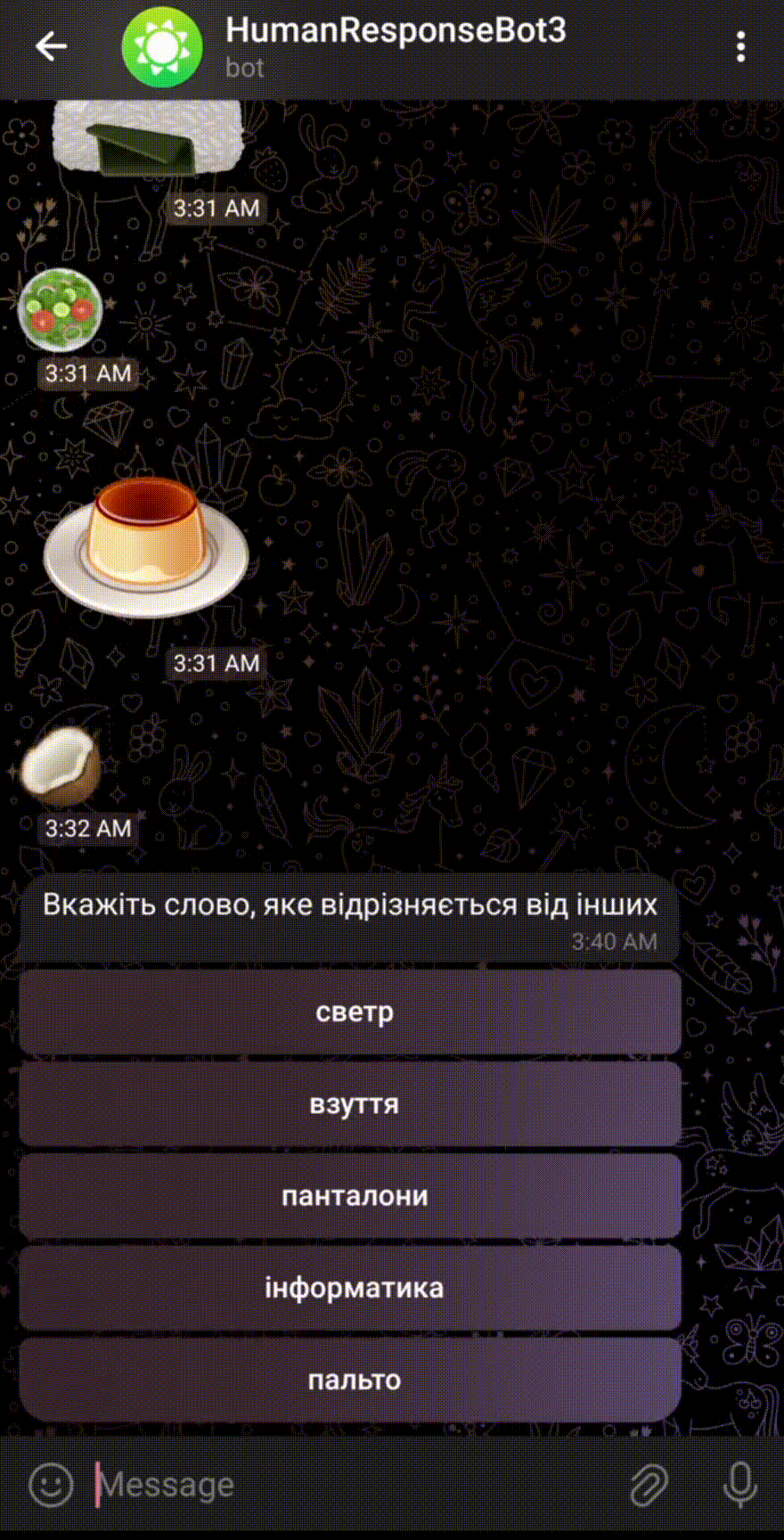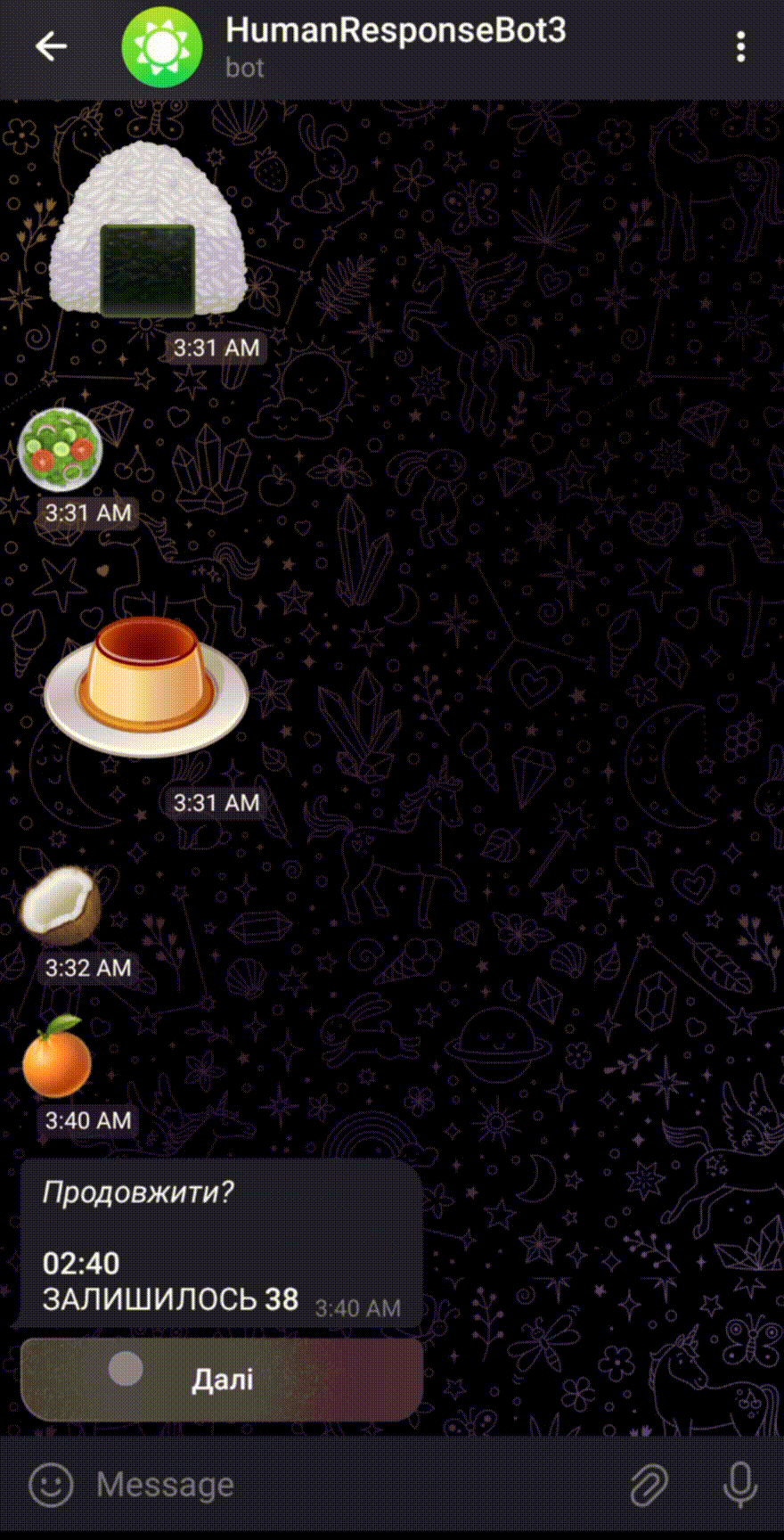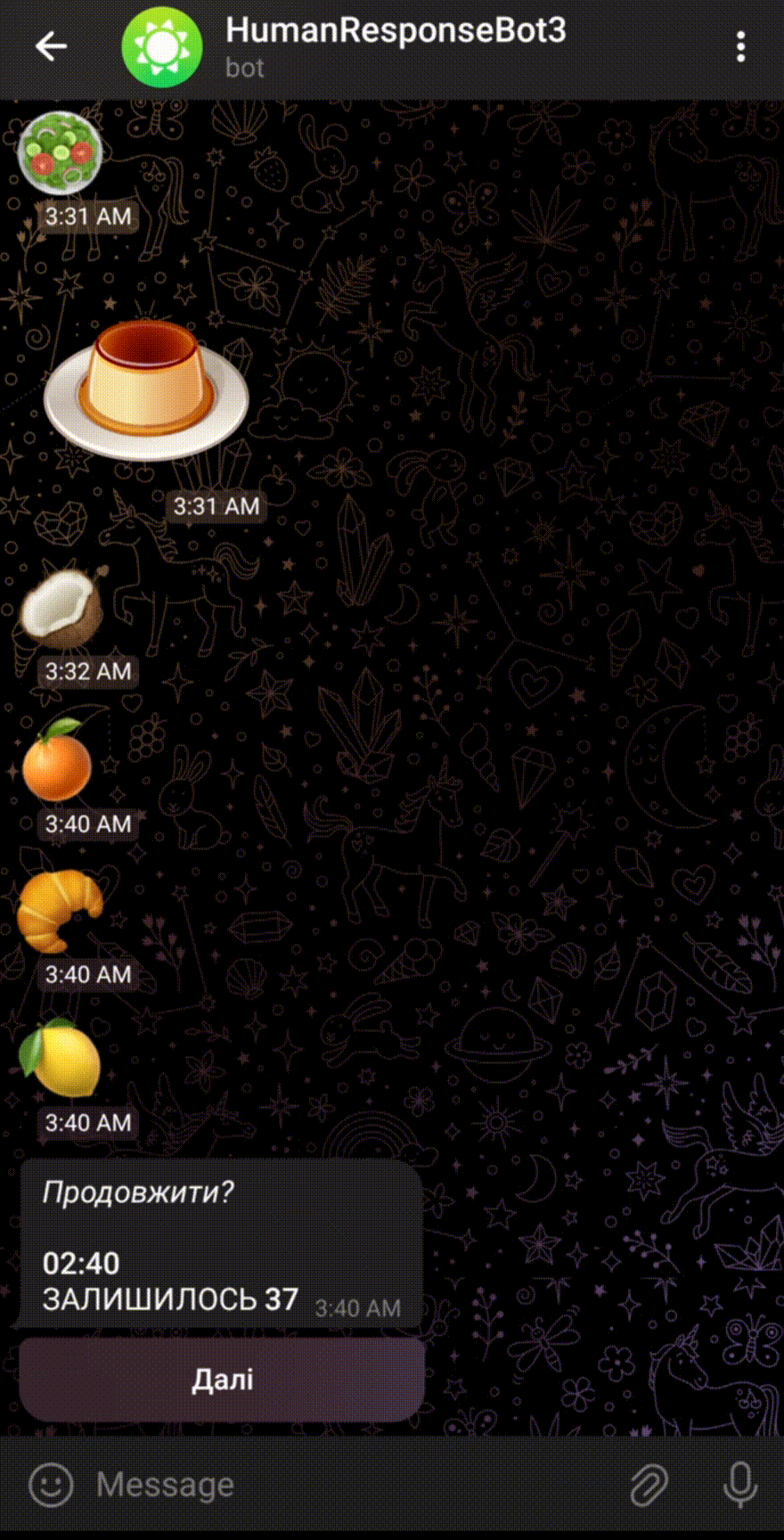
- UA-CBT story correction and instance filtration was done in Label Studio
- All human baselines were done with a Telegram bot
- On the left is the human baseline of LMES CATS-MC (which word doesn’t belong…)
- Gamification approaches with e.g.
- random food emoji after each answer
- showing the number of remaining instances
- The bot available on GitHub1
- Thanks to: Oleksii K., Viacheslav Kravchenko, Daria Kravets, Lina Mykhailenko, R., Mariia Tkachenko, @arturius453
Picture from the GitHub repository of the bot.
Experiments
Results
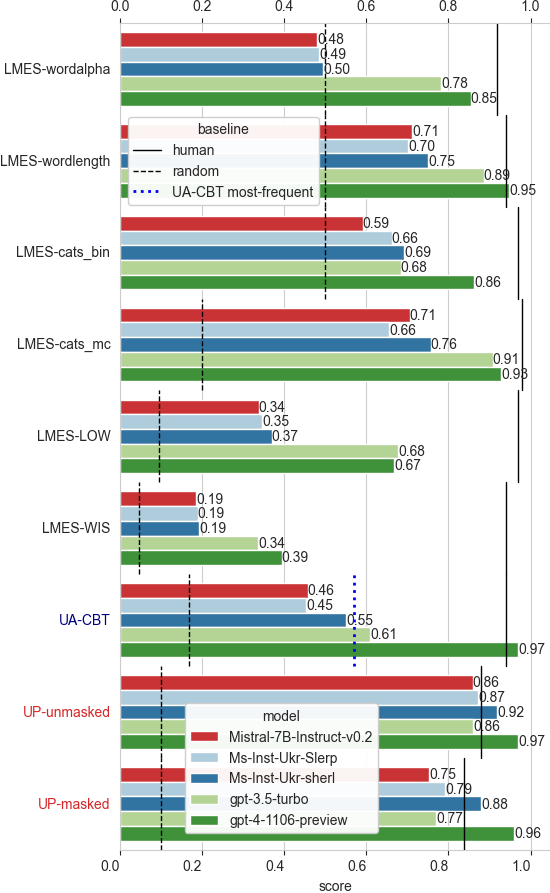
- GPT-4 is the clear winner, followed by GPT-3
- Sherlock is the best of the 7B models tested (especially vanilla Mistral); beats GPT-3 in 3 cases — shows that finetuned smaller models can compete with large LLMs
- LMES: LOW/WIS are the hardest (instances with long words/sentences overrepresented); WordAlpha: 7B models no better than chance.
- UA-CBT: GPT-4 spectacular (on Gemini Pro instances as well).
- UP-Titles: masked dataset harder; Sherlock’s (not finetuned on Ukrainian news) second best (2022-2023 articles; cutoffs: 2021 for GPT-3, mid-2023 for GPT-4).
Conclusions
Thank you!

Sample tasks: UA-CBT
Partial translated UA-CBT instance with the 6 options
{kind=link}
Disambiguation

Screenshot: https://www.google.com/search?q=light%20synonyms
Label Studio
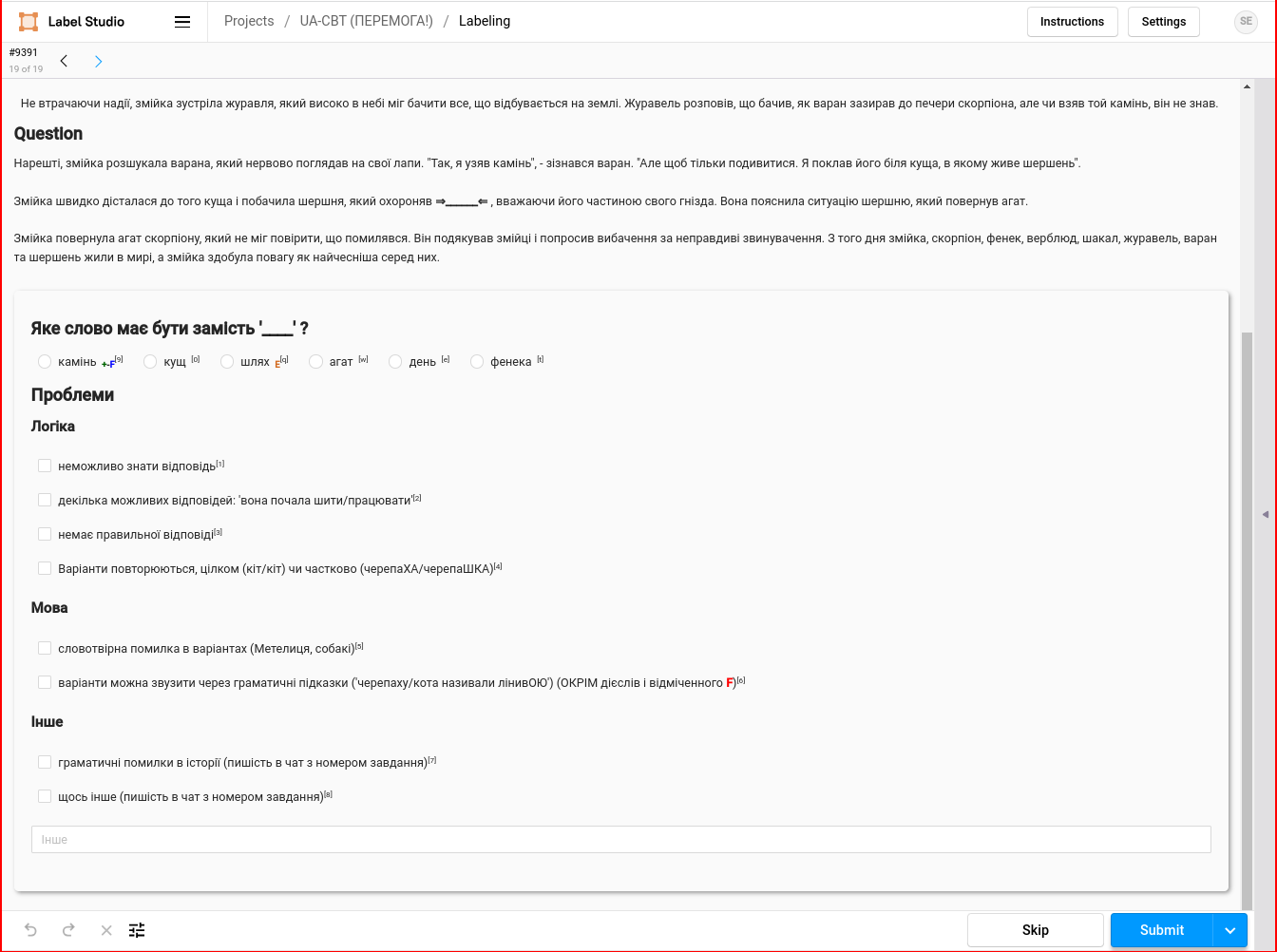
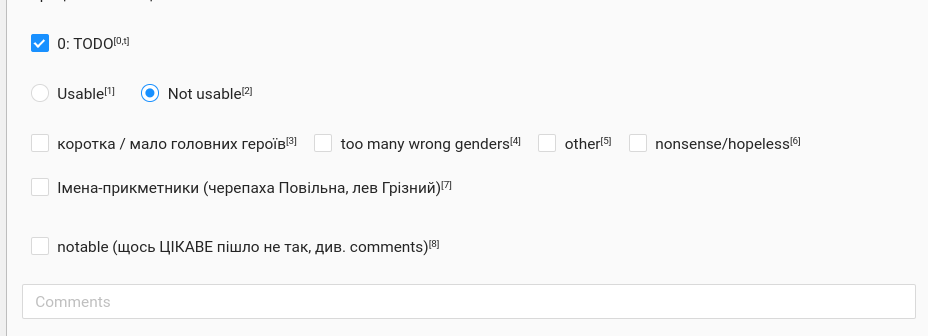
UA-CBT task filtration
UA-CBT – Templates

- Iteratively improved but no formal testing was done
- (for d see prev. slide)
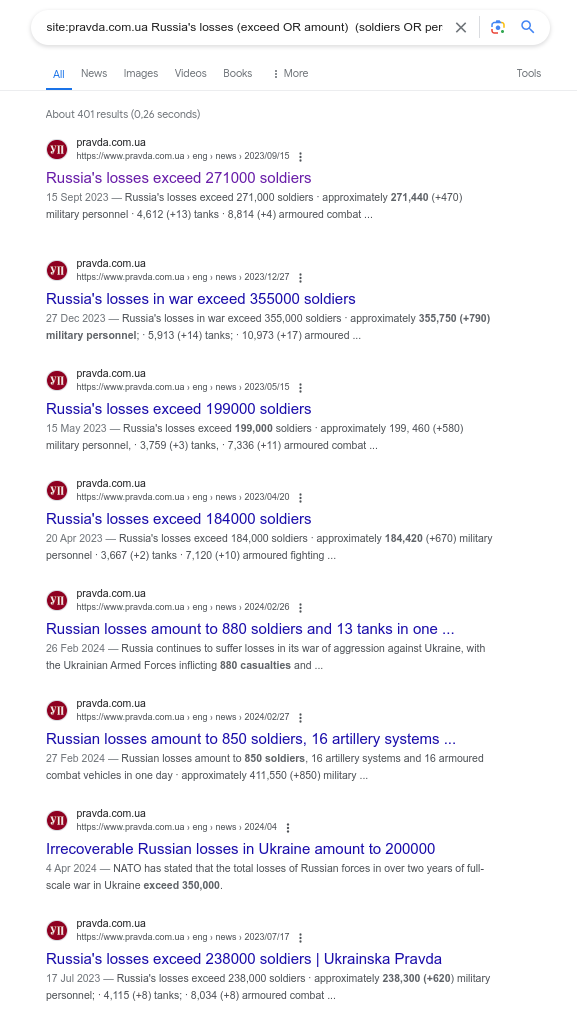
UP-Titles
- Article similarity is based on cosine distance between binary vectors from article tags
- Drawback: many articles with identical tags
- But too similar articles would have been counterproductive — many too similar articles were published in the last 2 years.
- And in the masked version they could have been indistinguishable
- And in the masked version they could have been indistinguishable
- On the right: Google search for “site:pravda.com.ua Russia’s losses (exceed OR amount) (soldiers OR personnel)”1
Looking for Volunteers


“On the left is my thesis without your help; on the right is my thesis with your help.”
Looking for Volunteers

- Created a group for the human annotators, the first 4 were invited personally
- Then I posted a message (left) to my Telegram channel with 40 subscribers, after ~600 views and 15 shares it brought 6 more people
- 8/11 in total ended up annotating (me included)
- Annotation meant:
- Processing UA-CBT stories
- Filtering UA-CBT task instances
- Human baselines for all of the tasks
- I owe my gratitude to all of them
Label Studio
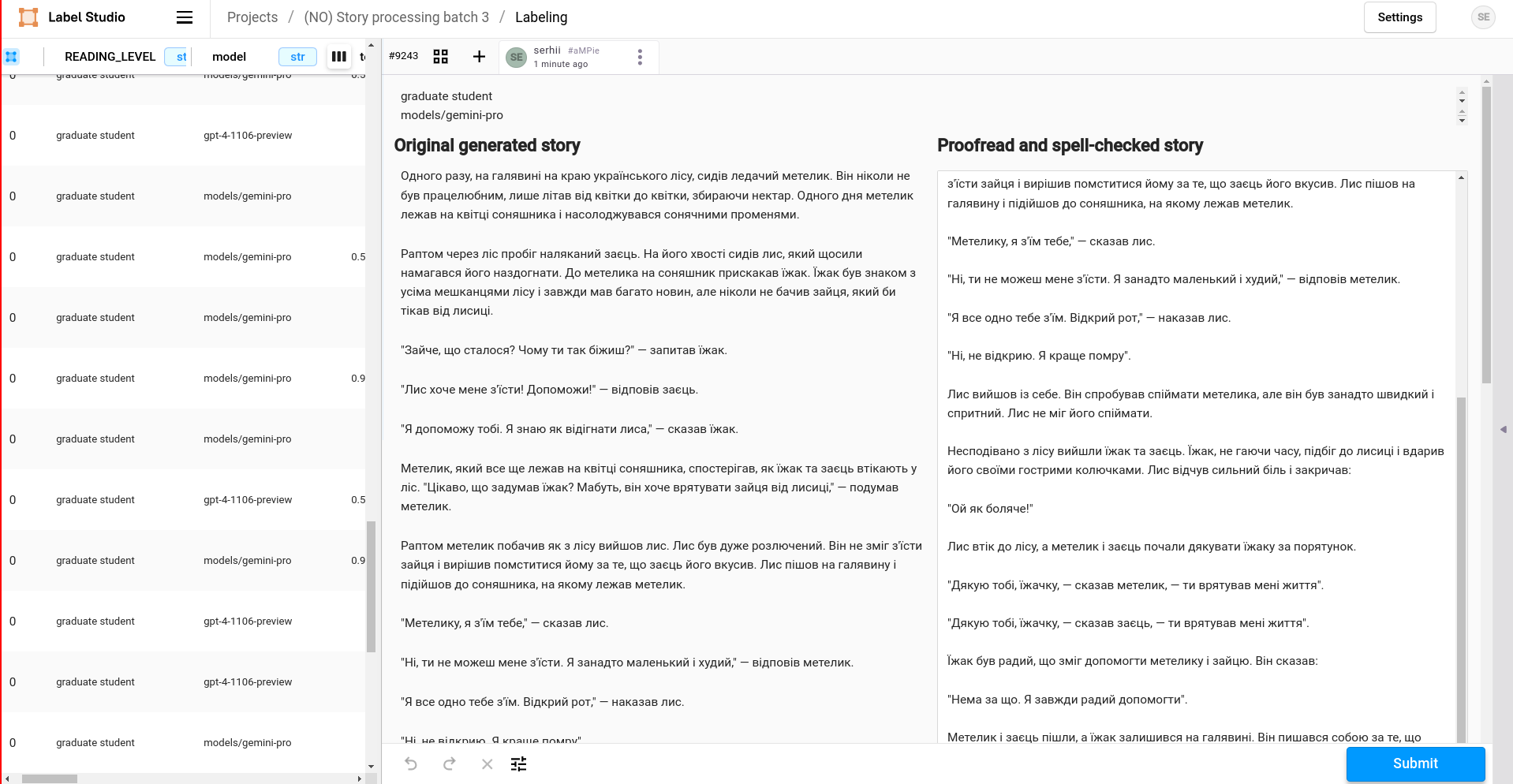
Story correction interface (Label Studio: https://labelstud.io)
Label Studio {.smaller visibility=“uncounted” }![Story correction interface (Label Studio: https://labelstud.io)]()
Test slide
But I wasn’t angry for long: after all, he’s just a dog, I can’t expect him to be moral. I think the →_light_← from the Moon makes him a bit of a werewolf.