My journey in PKM, Part 1: things I tried
Intro
Hi! Welcome to my take on Personal Knowledge Management (PKM).
I’ll describe the things I tried and lessons I learned trying to save stuff such as links, quotes, code snippets, ideas, book notes, meeting minutes and ideas from conversations I had with people, for the last 10 years. I won’t touch the related (but just as interesting to me) topics of productivity, time management, and task management.
I was planning to make this a short post, but it became unexpectedly large, and I split it into two parts.
Part 1 (this post) will be about things I tried in the past and why I stopped using them, along with what they taught me about my requirements for a PKM system.
Part 2 will be a description of the current iteration.
There may be a bias towards learning in public, text-based and self-hosted things, because I like those things and the post is about my experiences :)
TL;DR: Tried a lot of stuff, My criteria for a PKM system. Look at “Part 2” for my post about what worked at the end, spoiler: one long text file for randomness, Obsidian for notes, Hugo to convert part of it to my public blog.
Quick background and basics
Personal knowledge management (PKM)
Personal knowledge management is “a process of collecting information that a person uses to gather, classify, store, search, retrieve and share knowledge in their daily activities”. 1
Different ways to store different data
You’d likely do something different based on what you’re storing and why. Think of different example scenarios:
What kind of information you’re storing
- Simple info
- “London is the capital of Great Britain”
- “To run Tensorflow 1.2.3b on my Nvidia GPU x234 I needed CUDA v.10.3 and driver version 412.3”
- Info you might need later, but probably won’t need or be able to remember it specifically:
- “DVC is an open-source VCS for ML projects that would be cool to use sometime”
- This long-long paper I want to want to be interested in and will definitely read later
- Personal stuff
- “Doctor’s apt. 12.02.2022 at 10:00, don’t eat anything beforehand, drinking is fine. Dr. Max Mustermann, Whateverstr. 23 +4915255232148”
- Things I promised to do during the last meeting
- Lists of ideas of gifts for people, or debts
- .. Anything
- A quote or something funny:
“I, on the date: Are you, what do you think about Google Translation?
Date: I think he is an excellent tool for communicating with strangers! Now, no need to learn a foreign language!”2
- A quote or something funny:
How will you look for it
- You’ll want that specific fact (“When was my appointment?..”)
- “You need something for ML version control? I sometimes save cool links about open source stuff, there were definitely some projects for version control, one sec I’ll find it…”
- You won’t:
- … because it’s trivial to Google, not worth the effort to write it down (“London is …”)
- … because you’re only saving it to feel good and “not lose it”, you know you won’t ever read it or even remember it. 3
How will you access it?
- Is it okay if it exists only as a post-it on the fridge at home?
- “Honey, you at home today? Could you please take a picture of the paper near my…”
- You can’t Ctrl+F on a paper notebook
- You can’t Ctrl+F on a phone that drowned in a river
How often will you need it?
There’s an XXCD for everything4:

If it’s easily googleable and you’re not anticipating to need it often, it may not be worth the time to save. Generally, the more often you need this information, the fewer clicks and time should be required to access it.
Think of your target audience
“Personal” is not just about information, but also the process itself.
You are the person you care about, you are the only user, adapt it maximally to your own needs and the way your memory works.
There are people who just remember stuff.
There are people who don’t remember stuff but remember where to find it.
There are people who don’t remember stuff, where to find it, but remember what it was called and can search for it.
In my case, I don’t remember anything BUT I can create systems that allow to reconstruct the missing pieces.
There are people who are fine with carrying stuff on a USB stick and copying the latest version of the data to each device they touch, there are people who will spend 5 days automating this instead.
You get the idea.
My opinions here come from my own needs, and it took years for me to figure out my needs, and they keep changing too. It’s very likely you care about completely different stuff.
My journey
Paper, browser bookmarks, then I had a Chrome add-on which opened a small text field to paste notes there.
Then started the era of del.icio.us
1. “Social bookmarking” websites
You add your links there, probably through an addon or bookmarklet, optionally tag them, they are saved somewhere “in the cloud” and optionally public.
Del.icio.us
Delicious was awesome. You could save links, add any tags you like, browse them etc. You could also export your bookmarks in standard formats.
But the magic came from the “social” part of it: you could see which tags were popular for your link if it has been posted already, search other’s links, etc. It worked very well as a search engine, you’d get a much cleaner signal coming from real people, not SEO (especially for things like “Free hosting”).
Then after being sold multiple times and service quality degrading, it finally died. It’s death (and Google Reader’s) were the beginnings of my love for open source and self-hosted stuff, especially for things I depend on.
The current best replacement of it is “Pinboard — Social-bookmarking for introverts”. It’s paid, no-nonsense, has mostly similar features. But the last time I checked it was run completely by one single individual, raising exactly the same doubts for me.
Lessons learned
This story taught me that I want to be in control of my data. It has to be easily exportable to common formats, ideally in an automatizable way (or live locally, or be self-hosted). 5
If I also want stability. Even if I can get my data out, I probably built a workflow based on a specific program/service and converting, re-importing, re-building all of this is painful. Not everything is under our control, but some companies have a better track record than others. Having clear monetization strategy helps here.
This is also relevant for open source stuff: if the project dies, I’m not going to support the codebase myself. I now try to do some basic research about the projects I use, and do monthly donations to projects that add a lot of value to my life.
2. “Link blog”
The link blog
That was the time when I created my first “real” personal website (shmt.pp.ua), at a certain point with a blog for random interesting stuff.
First I saved links as a long page, then through a Wordpress extension, at the end a separate WordPress installation whose only goal was to keep my links.
The “wordpress extension” phase looked like this:

This gave me much more flexibility. Text/categories/descriptions, links between the posts, or posts containing multiple links about the same things, etc etc etc.
Taxonomy blues
That’s when I learned that taxonomies are hard. I’m not thinking philosophy here, just about what will make sense when looking up stuff later on.
- What should become a tag, what should become a category?
- Does this belong in category “Tutorial” or “Tutorials”?
- Did I tag the other similar links “ML” or “Machine learning”? “Coding” or “Programming”?
- Does “ML” automatically imply “IT” or it’s better to add “IT” too, for good measure?
- Do things like “Wikipedia” merit their own category or tag?6

- Just how much should I add to each link, given that each entity can be described as belonging to basically an infinite number of categories?
How do I keep it dynamic but still consistent, so that I don’t have to look anything up when tagging, don’t end up with duplicate tags, can easily and reliably know which tags to use when looking up stuff, and will never have to manually re-tag a lot of pages?
Information vs data vs knowledge
There was and old metaphor about data being a pile of bricks, information being a house.
Saving/tagging/categorizing links is good, but at a certain point I noticed that I’m not stopping at that anymore. Having a blog meant I could add text to posts - I was adding short descriptions / summaries, conceptualizing it by adding links to other relevant places, creating pages that are actually lists of resources on a specific topic.
This made the info more valuable by itself, but then I realized that it actually helps to remember stuff.
It’s like writing by hand instead of copypasting - once you formulate it in your own words, remove the unneeded parts, distill it to what you care about you already interacted with the source material a bit more and probably memorized part of it already.
Lessons learned
- Thinking about categories/tags is hard to do but needs to be done, otherwise you’ll end up with an unusable mess with duplicate categories and tags
- Links alone are good, but to make the most out of it you should have a place for summaries, links to other pages, things not neatly fitting the “one page = one link” concept.
Unmet needs
I was using tags/categories for different things:
- topics (“Programming”, “Design”)
- how much I like it (“Good”, “Awesome”)
- sometimes - where does it come from (wikipedia etc)
- medium - is it a blog post, is it a website, is it an ebook?
And I had no easy way to use AND/OR in queries, so it was either looking for “IT stuff” OR for “stuff I really liked”.
I wanted a more flexible taxonomy and run advanced queries over it. Something like “search for all the links about ‘Psychology’ except wikipedia articles”.
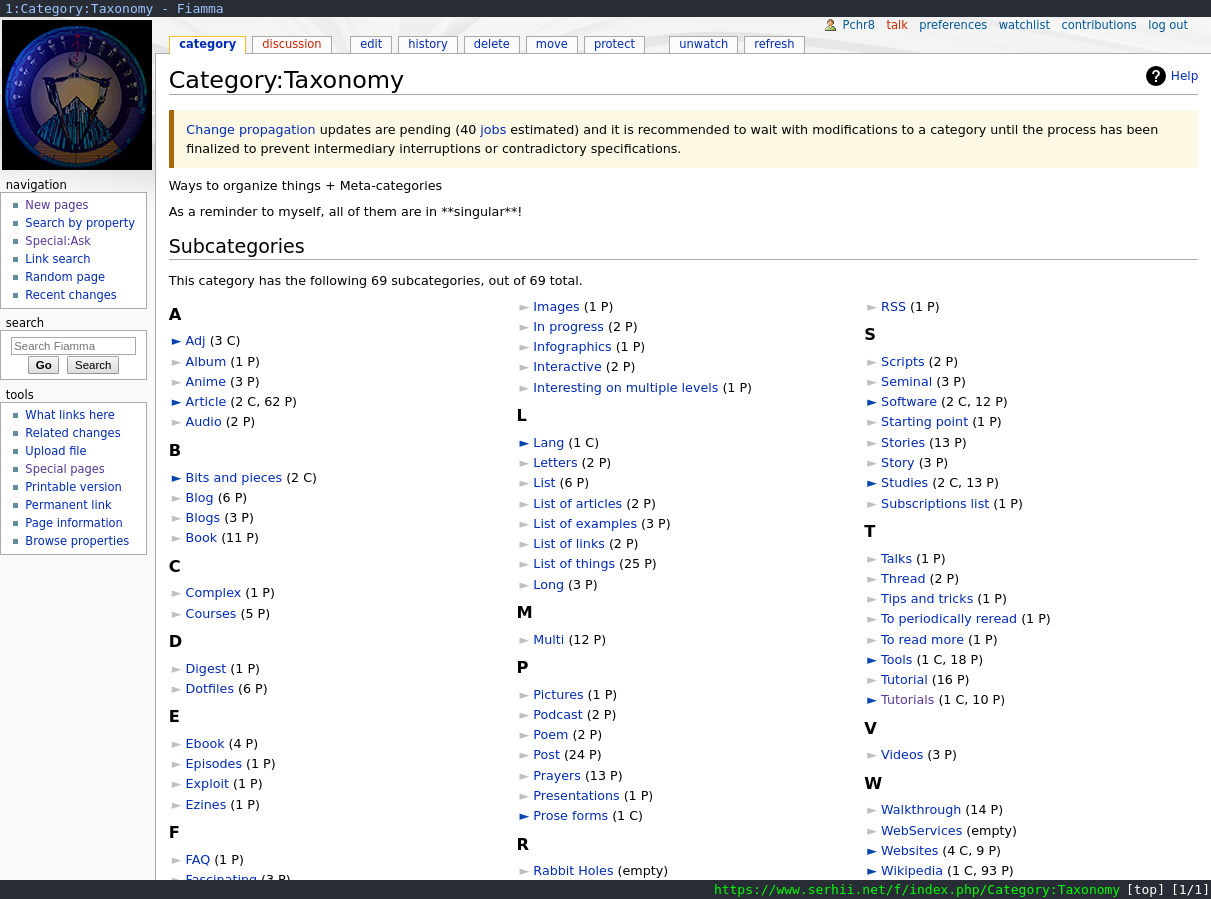
The next step was a personal wiki, then an overly-complex Semantic Mediawiki.
3. Personal wikis
Personal wikis are a thing, and there are infinite variations here too. I’d assume most aren’t open to the internet, but there are some public ones (for example YourcmcWiki, in Russian).7
There are a lot of engines, from the venerable MediaWiki to smaller/leaner things like dokuwiki [DokuWiki] etc.
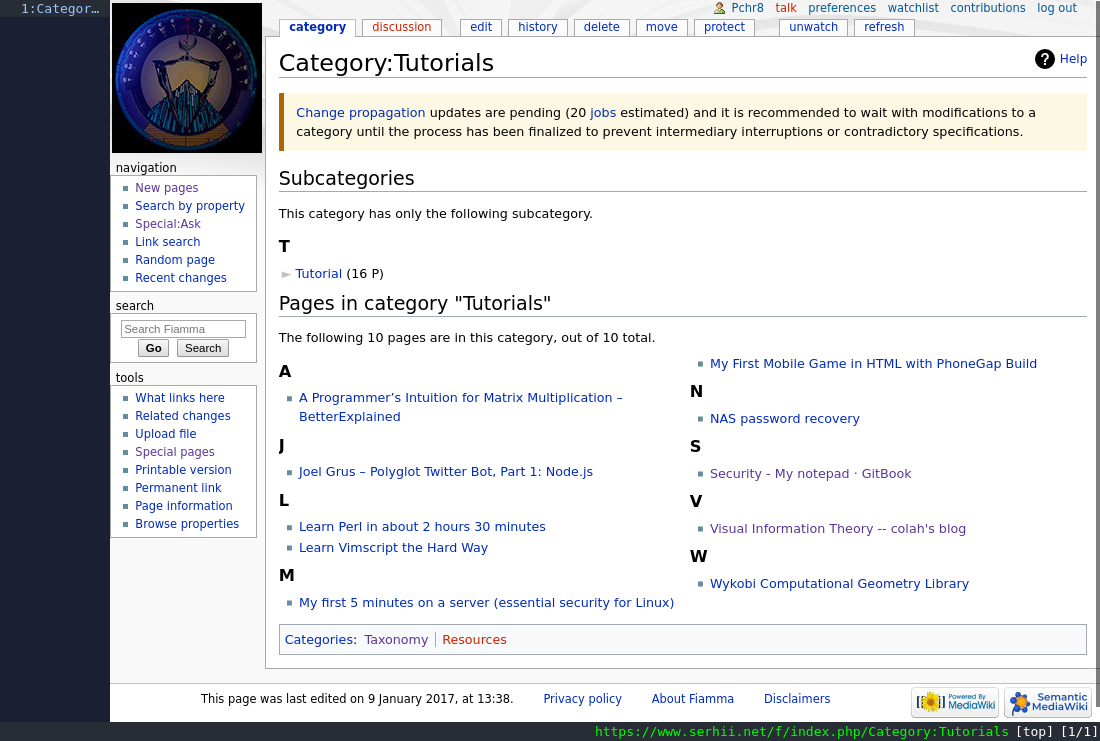
Using a wiki also means we can deal with complex information much better - longer pages, inter-links, upload pictures and bigger attachments (.pdf books for example!), etc. You can add descriptions to category pages, you can see stuff like “what links here”, etc.
My own (still existing) wiki
My own personal wiki lives here. It was the main place I organised my links and resources for the last 5 years (though it’s mostly abandoned the least year or so). Of course I wrote a post here about it (in Russian).
Looks/looked like this8:
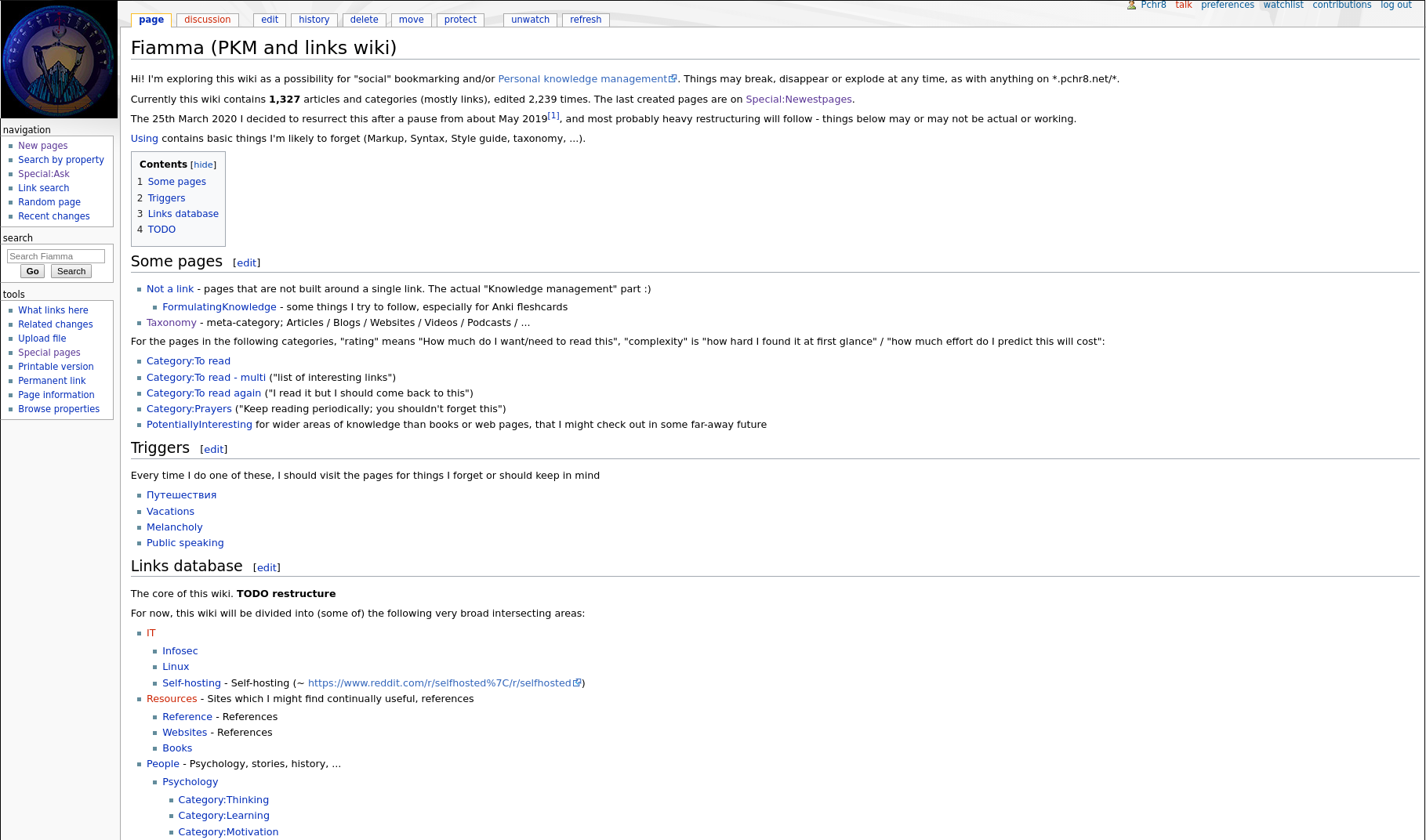
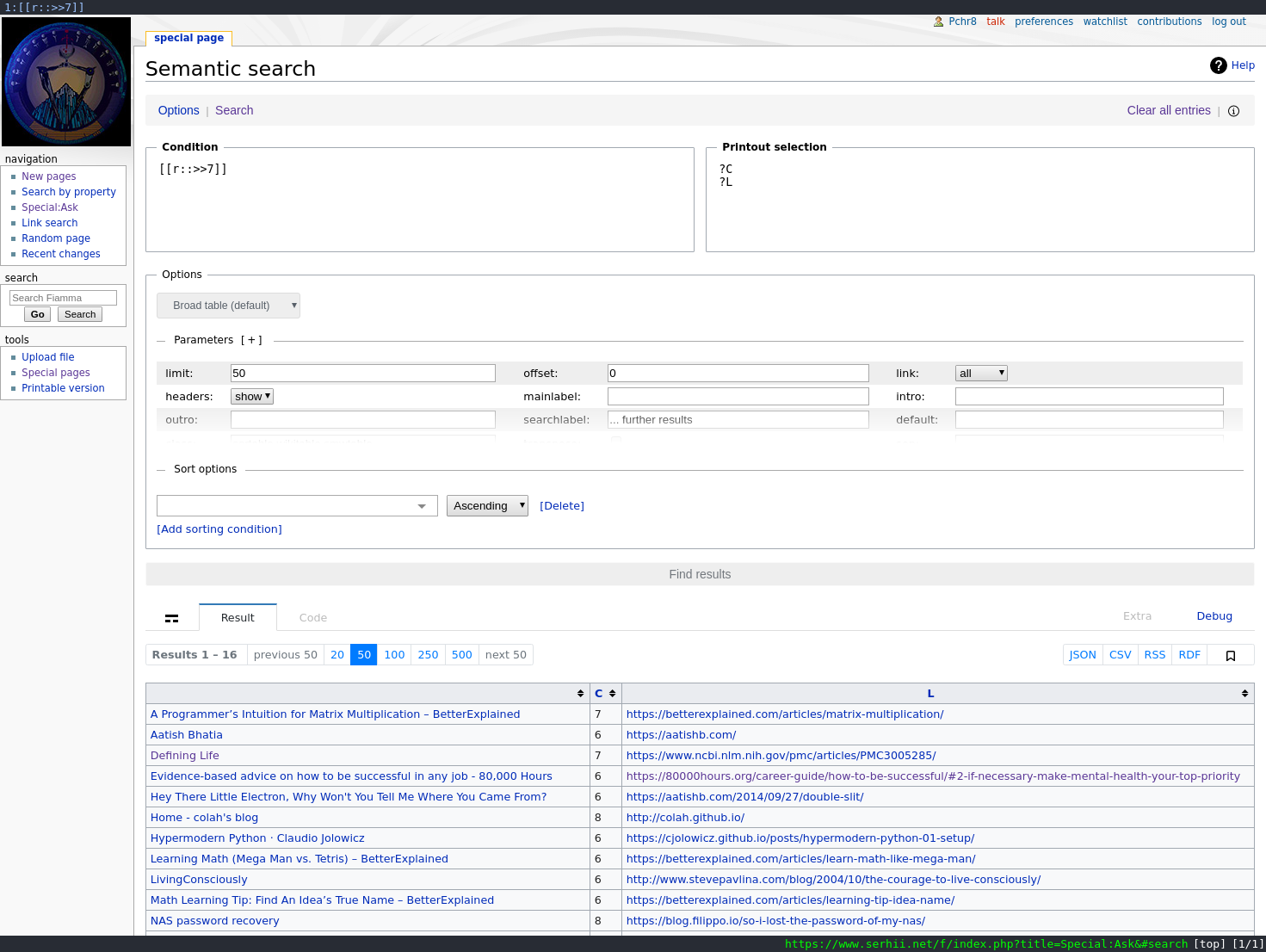
For the “define your own attributes and run complex searches” part I installed Semantic Mediawiki, which allows to define custom attributes and semantic connections between pages.
For example, you can set [London] HAS_POPULATION 400000 or [London] IS_A [City], then query for “Cities with population over 3000”. Just what I wanted.
Now that I could define my own attributes, nothing could stop me.
I used it as a standard PKM wiki with additional bits for the pages representing links.
Standard PKM was simple: I just added the text I want to save in the pages.
- Page about using SMW: Using - Fiamma
- How to formulate knowedge in flashcards: FormulatingKnowledge - Fiamma
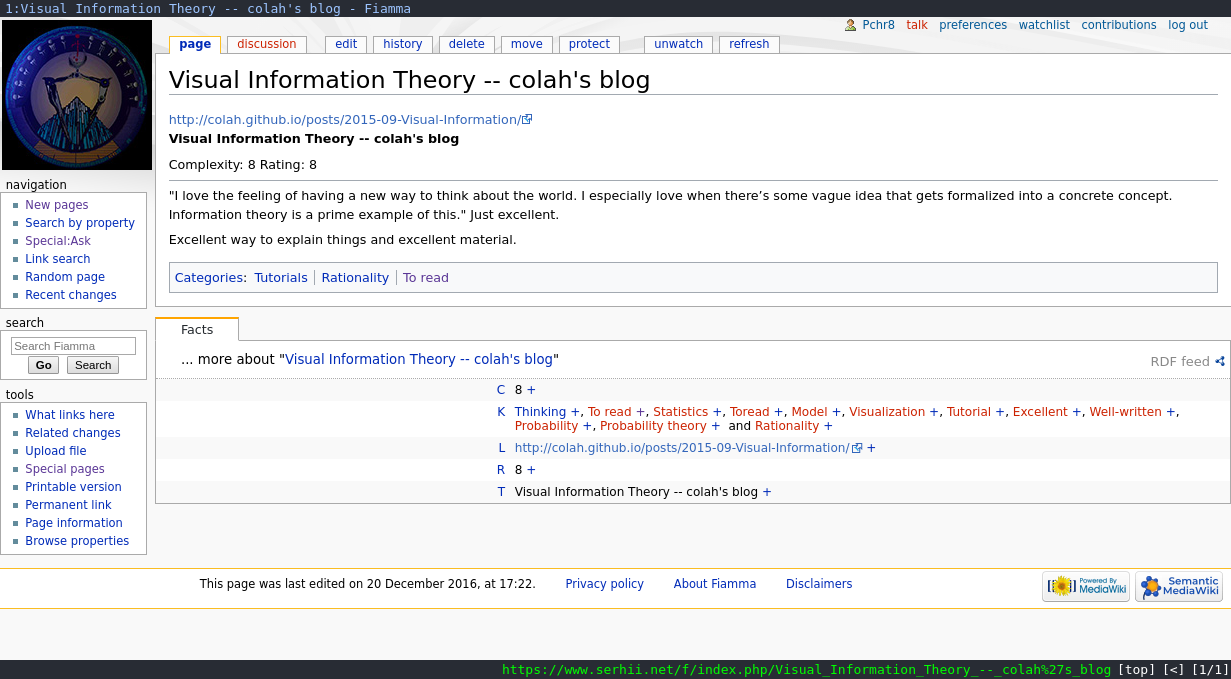
Pages representing links were more involved. Each link-page had the following attributes:
- URI (
l) - title/name (
n) - rating (how much I liked it or expect to like it) (
r) - complexity (how much mental effort does it require) (
c) - tags (
t)
Then since it’s still a normal wiki page, it could belong to categories and it had place for free-form text that I used for summaries (for example, see this page: https://www.serhii.net/f/index.php/Quantifying_Productivity).
Now I finally had built a system exactly the way I wanted it.
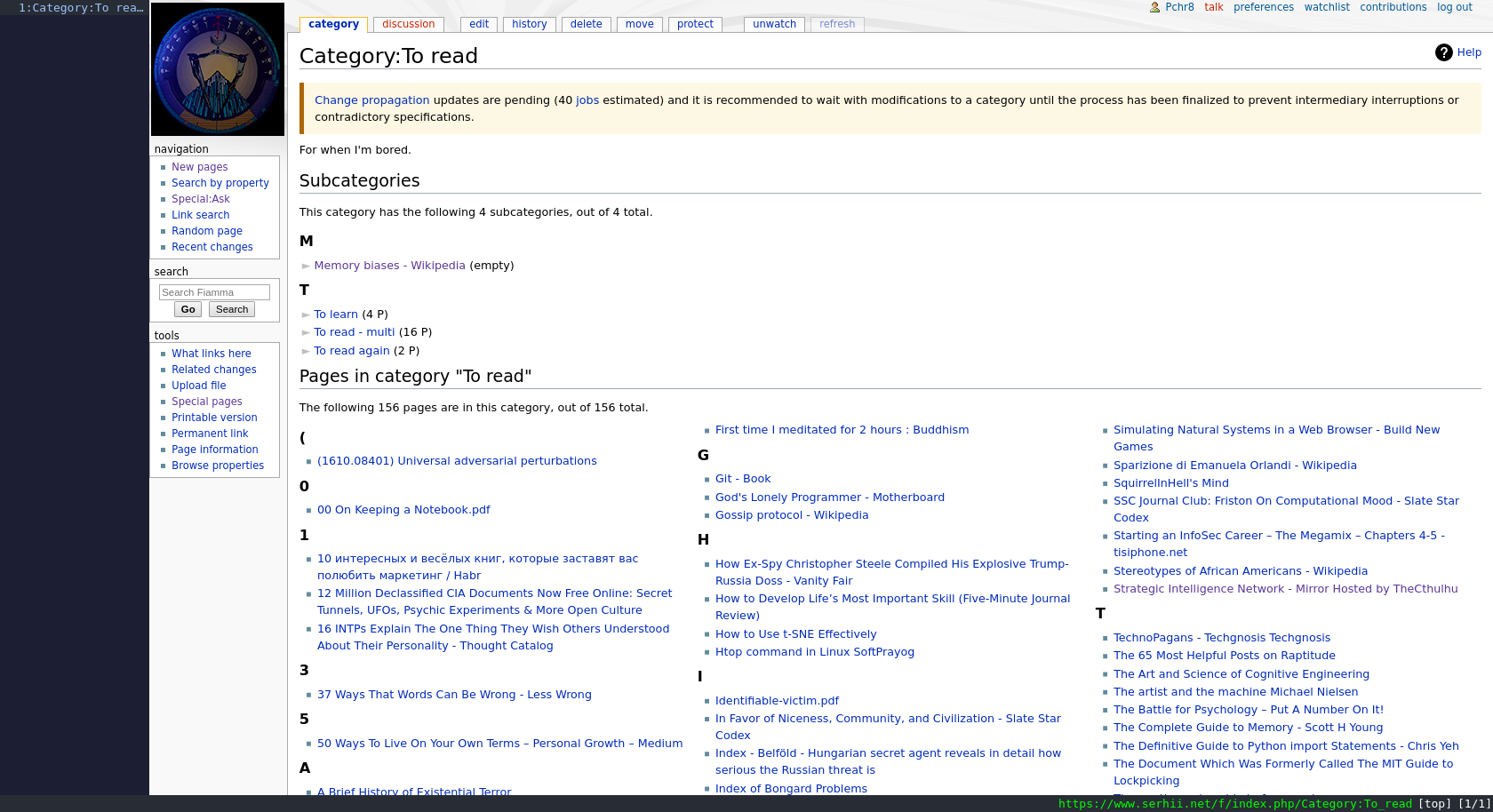
Hi link wiki, I’m bored, give me some easy articles about programming I wanted to read.
I go to Special:Ask, then: Query:
[[Category:To read]]
[[Category:IT]]
[[c::<<7]]
Printout (show columns “complexity” and “link”):
?C
?L
Results:

Search results could be returned in various formats (like RSS/JSON/…). The RSS feed of the latest links I liked (rating 8+) was shown on my home page. 9 I once used it to write a simple website where you click on a big red button and it took you to a random link from the wiki.
Good times.
Unmet needs
Then what went wrong?
Friction
A lot of things were stopping me, different ones, but all made the thing not fun to use.
Adding stuff to it took either many steps, or many scripts, I of course chose the second option.
My original post about it goes into painful detail about the process.
Short version: setting the page attributes look like this and is painful to type:
[[Link::http://what.ever]]
[[Name::Link title]]
I wrote a number of scripts that (when run on a page I want to save) open the browser window (through a mediawiki template), pre-fill the URI and title, I add the rest:
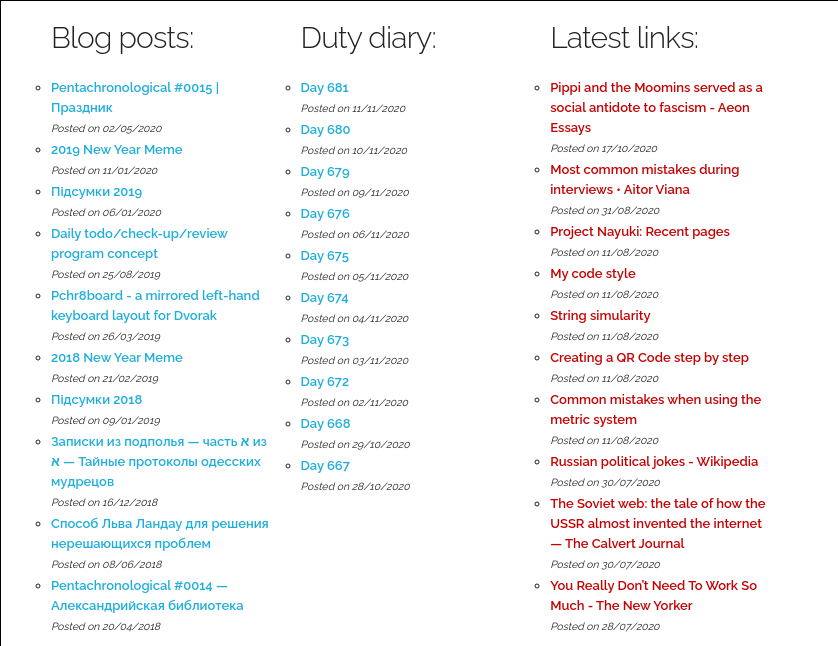
https://www.pchr8.net/d/dtb/
Diensttagebuch - A purely technical blog about things I did on particular days, for future reference and search.
5
tag1, tag tag2, tag3
Cat1
Cat2
And a category with space
Then a VIM macro transforms it into this, which becomes the final content of the page:
{{B|https://www.pchr8.net/d/dtb/
|Diensttagebuch - A purely technical blog about things I did on particular days, for future reference and search.
|5
|6
}}
{{#set:
k=tag1, tag tag2, tag3
|+sep=, }}
[[Category: Cat1]]
[[Category: Cat2]]
[[Category: And a category with space]]
B is another mediawiki template I wrote (source here). It sets the SMW parameters (or uses the defaults) + makes the rendered page look nice.
I had keybindings for all this and it was fast, and the rating and complexity were optional and defaulted to 5, but I still had to enter the tags and categories and then wait for it to save to see if it worked.
Slow feedback loops
Tags and category names had to be typed manually and you’d get no feedback until you publish/preview. So:
- you had to remember them (or look them up)
- If you made an error, it’d quietly create that tag/category. That’s why I had “Tutorial” and “Tutorials”, for example. 10 My convention of “Categories are plural, tags singular” helped but not too much.
- Only syntax errors were loud but also only at the very end.
When running, it was slower that I’d have wanted. Of course, it’s a webapp running on a cheap server, but even moving it locally wouldn’t have helped much. This added to the frustration.
Mantaining it
Even when not used, it created problems. Upgrading it, backing it up, moving it was painful and involved SQL databases, read/write permissions in PHP scripts, etc. Migration scripts were often broken, you’d have to re-import and rebuild the database, then find out that some extensions didn’t work etc. Not-upgrading it is a bad idea security-wise11 and if it gets too old your provider stops supporting the PHP/MariaDB versions of everything.
Availability
Corollary of the above, but: If something goes wrong, I can’t easily access that information. If my host goes down, I may have backups locally, but I won’t be able to access the info until I set up an entire LAMP stack and restore it there.
Without noticing or planning to, I moved to a simpler system.
Lessons learned
- Adding information has to be fast and require few steps
- The thing has to require very little maintenance to keep it alive
- The thing has to be future-proof: info should be readable on some level even without the thing that created them being available
My criteria for a PKM system
The tales above point to a nice list of criteria that are important for me:
- Data storage:
- The data’s main location shouldn’t be a webservice. Ideally I should control both the data and the tools needed.
- The data should live in a future-proof format, readable even without the tools
- It has to require little upkeep/maintenance
- Should be flexible and the data it gets and support:
- Not just links, but also pictures/files etc
- free-form text for manual summaries of the items saved
- Taxonomy:
- Ideally as flexible as possible, ability to add own attributes
- Ability to use complex queries when searching
- Quick feedback for errors or autocomplete for tags/categories
- Usability:
- Adding stuff it should be really fast and friction-free. If it takes time and effort to add new info to it you won’t do it often.
- Both loading times and number of steps should be very very small
My next post will be about the next step and the system I’m using now, that I’m very happy with. Thanks for reading!
-
this is the story of 70% of my saved links. I don’t want to read it now, I don’t want to lose it by closing the tab, so either it’s in limbo with the other 100+ open tabs, or it goes to a category like “read later” with a single tag “interesting”. ↩︎
-
Exporting stuff though manual steps is tedious and easily forgettable. And the webservice can randomly stop allowing that, like Goodreads did, or you can lose access to your account. ↩︎
-
(At the end I decided that yes, because when looking for it I remember it was on Wikipedia and this helps to narrow it down.) ↩︎
-
I had a lot of them saved in my links, but all except the above are down now. Link rot is another threat and steps can be taken to mitigate it: Archiving URLs · Gwern.net ↩︎
-
Made some more screenshots just for fun, the link wiki is going down pretty soon, as soon as get to moving it to something static.
 ↩︎
↩︎ -
Looked like this:
 ↩︎
↩︎ -
(this is why I got rid of Wordpress) ↩︎