serhii.net
In the middle of the desert you can say anything you want
-
Day 2750 (13 Jul 2026)
Exclude directories when building UV packages
My package was 156mb because my tests/ were 120mb.
Uv uses hatchling
- Building and publishing a package | uv
- Build configuration - Hatch
- Feature request: Add ability to exclude certain file/directory patterns from
uv buildoutput · Issue #7938 · astral-sh/uv
TL;DR add this to pyproject.toml
[tool.hatch.build.targets.sdist] exclude = [ "tests/" ]Before/after:
# before -rw-r--r-- 1 sh sh 156M Jul 13 13:20 pkg-9.2.0.tar.gz # after -rw-r--r-- 1 sh sh 8.3M Jul 13 13:15 pkg-9.3.0.tar.gz # yay!
Profiling startup import time of Python programs
How to speed up Python application startup time - DEV Community
This tells you the time for imports:
PYTHONPROFILEIMPORTTIME=True uv run my_program.py
-
Day 2725 (18 Jun 2026)
UI pattern click to copy name, shift-click to copy hex
Colors - Core concepts - Tailwind CSS
Click to copy the OKLCH value or shift+click to copy the nearest hex value.
Oh that’s cool I could use that. The only reason I found it was because https://quasar.dev/style/color-palette/#color-list didn’t give clean access to the hex values so I kept looking :)
-
Day 2717 (10 Jun 2026)
Huey is a simple queue for Python
- coleifer/huey: a little task queue for python
- Simplest example: huey/examples/mini/mini.py at master · coleifer/huey
- Reference: Huey’s API — huey 3.0.1 documentation
- Mini-Huey (Huey Extensions — huey 3.0.1 documentation) is a mini version that requires no separate consumer process or persistence
- Consuming Tasks — huey 3.0.1 documentation has info about the consumer
-
Day 2705 (29 May 2026)
Prefix my custom CLI commands with a comma and fish function descriptions
I think I’ve read about this years ago somewhere, just thought of it
For all my (fish) CLI aliases a
,is an OK prefix to use, it even supports completion.alias ,isodate='date +%F'No idea about any downsides yet, will play with this for a week or so.
function ,blist -d "search and show bitwarden credentials" command bw list items --search "$argv" | jq '.[].login | [.username, .password]' -c end function ,bcp -d "copy password of the first matching bitwarden item" command bw list items --search $argv | jq .[0].login.password -r | xc echo "copied password for '$argv'" end # etc, I see potential here!`` Also TIL: fish functions can have a description that will be shown when tab completing!
function functionname -d 'function description'Isn’t it beautiful?

Kubectl get info about resource with templates and yaml
I wanted the metadata.annotation pod-requests, viewable in node config -> YAML on the Rancher webgui.
Came up w/ this:
kubectl get node node-name -o template --template='{{ index .metadata.annotations "management.cattle.io/pod-requests" }}' # | jq '.["nvidia.com/gpu"]'It refused to allow me to use
-and/inside the name (k get node nodename -o template --template={{.metadata.annotations.management.cattle.io/pod-requests}}didn’t work), solution from Helm templating doesn’t let me use dash in names - Stack Overflow.Fun version w/ templates and json (there has to be a better way):
k get node nodename -o template --template='{"requests": {{ index .metadata.annotations "management.cattle.io/pod-requests" }}, "limits": {{ index .metadata.annotations "management.cattle.io/pod-requests" }}, "total": {"nvidia.com/gpu": {{ index .metadata.labels "nvidia.com/gpu.count" }} } }' | jq .Returns:
{ "requests": { "cpu": "19795m", "memory": "7450Mi", "nvidia.com/gpu": "1", "pods": "37" }, "limits": { "cpu": "19795m", "memory": "7450Mi", "nvidia.com/gpu": "1", "pods": "37" }, "total": { "nvidia.com/gpu": 1 } }Or even
k get node ki-srv03 -o template --template='{"requests": {{ index .metadata.annotations "management.cattle.io/pod-requests" }}, "limits": {{ index .metadata.annotations "management.cattle.io/pod-requests" }}, "total": {"nvidia.com/gpu": {{ index .metadata.labels "nvidia.com/gpu.count" }} } }' | jq '. | [.requests["nvidia.com/gpu"], .limits["nvidia.com/gpu"], .total["nvidia.com/gpu"] | tonumber]' -c # -> [2,1,4]
-
Day 2704 (28 May 2026)
bttf for CLI time parsing and interesting help pattern
BurntSushi/bttf: A command line tool for datetime arithmetic, parsing, formatting and more.
I use wolframalpha for most of my casual date ops etc. but the project is cool and I may need it.
But the most interesting bit is the documentation.
Quoting README:
I may ship arbitrary and capricious breaking changes at this point. You have been warned. […] And it doesn’t give a hoot about POSIX (other than the
TZenvironment variable).And THIS. I either love it or hate it, can’t decide:
-h/--help This flag prints the help output for bttf. Unlike most other flags, the behavior of the short flag, -h, and the long flag, --help, is different. The short flag will show a condensed help output while the long flag will show a verbose help output.It breaks my usual expectations but damn it’s a cool pattern that I really want to be a thing! You’re allowed to break conventions if your thing is really smarter and you’re explicit and intentional about it.
-
Day 2695 (19 May 2026)
Merge and rearrange pages from multiple PDF
Tiny neat app that shows pages from all PDFs and allows you to rearrange the order, does one thing and does it wonderfully!
-
Day 2692 (16 May 2026)
FNP-2026 at LREC paper notes
- FNP – FNP 2026
- FNP 2026 proceedings PDF.
When Tables Go Crazy: Evaluating Multimodal Models on French Financial Documents
- Links
- [2602.10384] When Tables Go Crazy: Evaluating Multimodal Models on French Financial Documents
- Github contains both dataset and scripts!
- Benchmark French visual finance docs, includes evaluation on multiple VLMs
- Chart checkboxes graphs and weird edge cases specifically present
- Bits
- LLMs when asked to generate questions usually generate only questions they have answers to
CFQA: A Chinese Financial Question Answering Benchmark from Corporate Annual Reports
- Links:
- ZackZhu00/CFQA_Chinese_Finance_Question_Answering · Datasets at Hugging Face
- zhutianning/Hallucination-detection-for-RAG: This project aims to design and implement a hallucination detection and evaluation pipeline for Retrieval- Augmented Generation (RAG) systems processing multi-modal financial reports (text, tables, images/charts).
- Unclear relation:
- Takeaway
- RAG decreases hallucinations and improves fact extraction scores but not clear for other tasks involving reasoning, and decrease scores w/ some model[s
(!) Verifiable Financial Enterprise Question Answering via Inference-Time Grounding and Traceability
- LLMs grounding verifiable citations
- Framework, modular, real-time
- Verify citations and fix citation drift by looking at ovelaps/presence w/ source documents.
- Sentence-level citations allegedly lead to better groundedness
- TODO Many many interesting citations to parse
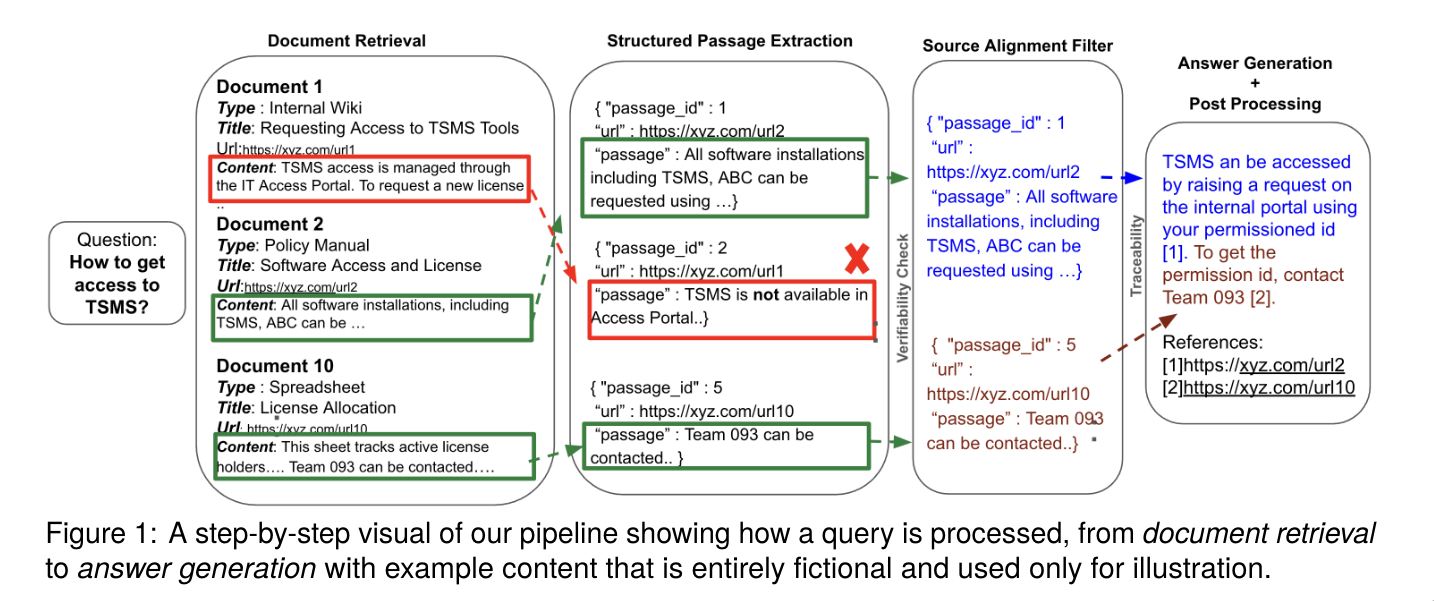
- Related paper I just found: [2604.23588] FinGround: Detecting and Grounding Financial Hallucinations via Atomic Claim Verification
-
Day 2690 (14 May 2026)
Prodigy NLP annotation tool
Prodigy · An annotation tool for AI, Machine Learning & NLP
First seen in Anshu Kiran Sharma - PhD Student Computer Science, Natural Language Processing’s “Once upon a kernel” @ LREC 2026