Very first notes on my Master thesis - Evaluation benchmark for DE-UA text
Officially - I’m doing this!
This post will be about dumping ideas and stuff.
Related posts for my first paper on this topic:
- 221120-1419 Benchmark tasks for evaluation of language models
- 221205-0009 Metrics for LM evaluation like perplexity, BPC, BPB
- 221119-2306 LM paper garden My first paper on the topic:
Procedural:
- I’ll be using Zotero
- I’ll be writing it in Markdown
- TODO: Zotero+markdown+obsidian?..
General questions:
Write my own code or use any of the other cool benchmark frameworks that exist?If I’ll write the code: in which way will it be better than, e.g., eleuther-ai’s lm-evaluation-harness?- I will be using an existing harness
- Task types/formats support - a la card types in Anki - how will I make it
- extensible (code-wise)
- easy to provide tasks as examples? YAML or what?
Do I do German or Ukrainian first? OK to do both in the same Master-arbeit?- I do Ukrainian first
- Using existing literature/websites/scrapes (=contamination) VS making up my own examples?
- Both OK
Actual questions
- What’s the meaningful difference between a benchmark and a set of datastes? A leaderboard? Getting-them-together?..
- Number of sentences/task-tasks I’d have to create to create a unique valid usable benchmark task?
- 1000+ for it to be meaningful
Is it alright if I follow my own interests and create more hard/interesting tasks as opposed to using standard e.g. NER etc. datasets as benchmarks?- OK to translate existing tasks, OK to copy the idea of the task - both with citations ofc
My goal
- Build an Ukrainian benchmark (=set of tasks)
- Of which at least a couple are my own
- The datasets uploaded to HF
- Optionally added/accepted to BIG-bench etc.
- Optional experiments:
- Compare whether google translating benchmarks is better/worse than getting a human to do it?
- Evaluate the correctness of Ukrainian language VS Russian-language interference!
- Really optionasl experiments
- Something about UA-specific bits, e.g. does it answer better about Ukrainian Aberglauben in UA or in EN?
- since chatGPT fails so hard at Ukrainian grammar(https://chat.openai.com/share/426c0d1c-10d0-41d4-b287-cc52a7790c4f) see if I can quantify that, and use an example of why morphologically complex langs are hard
Decisions
- Will write in English
- I’ll upload the tasks’ datasets to HF hub, since all the cool people are doing it
- Will be on Github and open to contributions/extensions
If I end up writing code do it as general as possible, so that both it’ll be trivial to adapt to DE when needed AND to other eval harnesses- EDIT 2023-10-10:
- I will be using an existing evaluation harness
Resources
-
Github
- asivokon/awesome-ukrainian-nlp: Curated list of Ukrainian natural language processing (NLP) resources (corpora, pretrained models, libriaries, etc.)
- see their links to other resources!
- Helsinki-NLP/UkrainianLT: A collection of links to Ukrainian language tools
- UA grammatical error correction competition! Damn! CodaLab - Competition
- see their links to other resources!
- Ukrainian nlp projects on github, as well as
#nlp #benchmarks Repository search results - ukrainian-language · GitHub Topics
- asivokon/awesome-ukrainian-nlp: Curated list of Ukrainian natural language processing (NLP) resources (corpora, pretrained models, libriaries, etc.)
-
- The UNLP 2023 Shared Task on Grammatical Error Correction for Ukrainian - ACL Anthology really cool paper with cool links/citations.
-
Cool model with links to datasets etc.! robinhad/kruk: Ukrainian instruction-tuned language models and datasets
-
Datasets UA, almost exclusively
- Lists
- A lot of them here: ukrainian-language · GitHub Topics
- zeusfsx/ukrainian-stackexchange · Datasets at Hugging Face
- hard to read but: Hugging Face – The AI community building the future. - starting from page 2-3-4 the non-multilingual ones start
- grammarly/ua-gec: UA-GEC: Grammatical Error Correction and Fluency Corpus for the Ukrainian Language!
- LARGE news with titles and uris: zeusfsx/ukrainian-news · Datasets at Hugging Face
- Machine Learning Datasets | Papers With Code
- Multiple choice comprehension, multilang: Belebele Dataset | Papers With Code
- FactCompletion
- reviews from rozetka/tripadv/.. vkovenko/cross_domain_uk_reviews · Datasets at Hugging Face
- 300k IS-A relations, some quite funny: lang-uk/hypernymy_pairs · Datasets at Hugging Face
- Lists
-
Benchmarks UA
- Contextual Embeddings for Ukrainian: A Large Language Model Approach to Word Sense Disambiguation - ACL Anthology
- fido-ai/ua-datasets: A collection of datasets for Ukrainian language
-
ua_datasets is a collection of Ukrainian language datasets. Our aim is to build a benchmark for research related to natural language processing in Ukrainian.
- Cool example of API usage: ua-datasets/ua_datasets/src/question_answering at main · fido-ai/ua-datasets
-
-
UA grammar/resources/…
- Linguistic Resources for the Ukrainian language on-line - Universität Regensburg
- лабораторія української
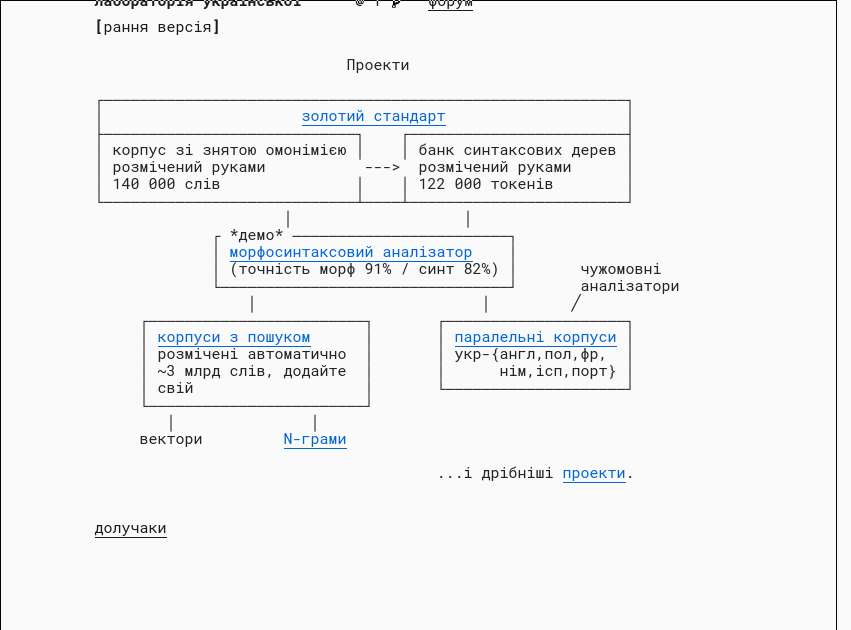
- I need to know more theory to understand but feels EXTREMELY useful
- has an API:
> curl -F json=false -F data='привіт мене звати Сірьожа' -F tokenizer= -F tagger= -F parser= https://api.mova.institute/udpipe/process
- лабораторія української
- Генеральний регіонально анотований корпус української мови (ГРАК): ГРАК - site.name
- Українська морфеміка — Вікіпедія
- Corpora UA
- brown-uk/corpus: Браунський корпус української мови
- золотий стандарт / UniversalDependencies/UD_Ukrainian-IU at dev
- Інші корпуси української мови та слов’янських мов - site.name, with info about whether it can be downloaded
- saganoren/ukr-twi-corpus: A corpus of Ukrainian Twitter texts + instructions for downloading and filtering texts.
- Linguistic Resources for the Ukrainian language on-line - Universität Regensburg
-
General evaluation bits:
-
Random UA:
- GRAC, can’t download but can use it for research
Benchmarks - generic
- Here:230928-1735 Other LM Benchmarks notes
- “literature”:
- Criterias of established benchmarks: BIG-bench/docs/doc.md at main · google/BIG-bench
- Related work of <
@ruisLargeLanguageModels2022(2022) z/d/>
Cool places with potential
- Ask Про сайт | Горох — українські словники if they can make dumps available, I could do something like “find the closest synonym to this word” etc.
- OH NICE: Home · LinguisticAndInformationSystems/mphdict Wiki
- These seem to be the DBs of the dictionaries: mphdict/src/data at master · LinguisticAndInformationSystems/mphdict
- OH NICE: Home · LinguisticAndInformationSystems/mphdict Wiki
- Cited in WSD task3:
- Open data places:
Plan, more or less
- Methodically look through and understand existing benchmarks and tasks
- Kinds of tasks
- How is the code for them actually written, wrt API and extensibility
- Do this for English, russian, Ukrainian
- At the same time:
- Start creating small interesting tasks 230928-1630 Ideas for Ukrainian LM eval tasks
- Start writing the needed code
- Write the actual Masterarbeit along the way, while it’s still easy
Changelog
- 2023-10-03 00:22: EvalUAtion is a really cool name! Ungoogleable though
-
Reproducing ARC Evals’ recent report on language model agents — LessWrong ↩︎
-
<
@labaContextualEmbeddingsUkrainian2023Contextual Embeddings for Ukrainian (2023) z/d/> / Contextual Embeddings for Ukrainian: A Large Language Model Approach to Word Sense Disambiguation - ACL Anthology ↩︎