Ukrainska Pravda dataset
This post describes the Ukrainska Pravda dataset I created as part of my Master’s Thesis. The contents of this blog post will be edited (esp. for brevity) and become part of the thesis (230928-1745 Masterarbeit draft).
Ukrainska Pravda articles classification
A novel dataset created in the context of this Master’s Thesis is the Ukrainska Pravda multilingual dataset. The package written for this, UPCrawler, is released at (https://github.com/pchr8/up_crawler) under the MIT license.
The dataset is released on the HF Hub at https://huggingface.co/datasets/shamotskyi/ukr_pravda_2y / doi https://doi.org/10.57967/hf/1476 under the CC BY-NC 4.0 license.
Ukrainska Pravda
Ukrainska Pravda (lit. “Ukrainian Truth”; https://www.pravda.com.ua/) is a Ukrainian online newspaper for a general readership writing, mostly, about political and social topics.
In 2017, it was in the eighth most cited source of the Ukrainian Wikipedia1 and in 2020 it was the most visited online news website in Ukraine2(TODO - better source). The Institute of Mass Information listed Ukrainska Pravda listed it among the six online editions with the highest level of compliance with professional journalistic standards in 2021.3
Website structure
UP (Ukrainska Pravda) publishes articles predominantly in Ukrainian, with some being translated to Russian and English. Each article can belong to zero or more “topics” (tags) that are mostly preserved across translations.
Each article has an article ID that is constant across translations.
Crawling
The crawler interface
The CLI interface expects a date range (using natural language, e.g. “last year”) and a target folder, where the pages are saved.
Getting URLs of articles to crawl with Sitemaps
Initially, the package UPCrawler used the daily archive pages (e.g. https://www.pravda.com.ua/archives/date_27092023/) to get the URLs of articles published on a specific day, then for each article URL accessed the expected locations of the Russian and English translations to check if a translation exists. Later, I rewrote the code to use a much better solution: parsing the XML sitemaps (e.g. https://www.pravda.com.ua/sitemap/sitemap-2023-09.xml.gz) using the advertools Python package.
Sitemaps4 is a XML-based protocol used to inform search engines about the URLs available for web crawling, as well as provide additional information about it such as when was the page last updated, how often does the content change, etc.
The following regex (see https://regex101.com/r/dYlIiF/4 for an interactive analysis) is used to parse each URL to get the language of the article, the article ID, the section (news, podcasts, ..) etc.:
URI_REGEX_STR_EXT = r"(?P<uri>(?P<domain>.*\.com\.ua\/)(?P<lang>(eng)|(rus))?\/?(?P<kind>.*?)\/(?P<art_id>.*(?P<date_part>....\/..\/..?)\/(?P<id>.*)\/))"
Crawling the individual articles
Crawling the articles is done using the beautifulsoup4 library. I considered the alternative option of using the newspaper3k package which was able to detect the article, title and metadata from UP surprisingly well, but it incorrectly detected some fields (which would have required manual fixes anyway), so I decided to keep my from scratch implementation.
For transparency and in the spirit of ethical crawling5, there were timeouts between requests, and the unique useragent contained a short explanation of my project as well as my email. At no point was I ever contacted or the crawler blocked.
The most challenging part were the tags. The URL of each tag contained a unique identifier that was consistent between translations.
Processing steps
The article text inside <article> was taken from each page. The content of the tags <p> and <li> were used to extract the plaintext while avoiding advertisements, infoboxes etc.
Paragraphs matching some standard article endings like “follow us on Twitter” weren’t added to the plaintext, but not all such endings were filtered out.
The tags required special care because they presented two problems:
- There were pages with lists of tags in Ukrainian and Russian6 but not English
- Some tags had translations to other languages, some didn’t.
Since this was supposed to be a multilingual dataset I wanted to have a list of tags for each article independent on the translations. The solution at the end was to crawl Ukrainian and Russian tags pages to save the short unique ID and both translations, and add English translations to the short IDs when they were seen in the English translations of articles.
An example tag and three translations:
{"ukr":["флот","/tags/flot/"],"rus":["флот","/rus/tags/flot/"],"eng":["naval fleet","/eng/tags/flot/"]}
The UPravda multilingual dataset
Dataset description
The UPravda multilingual dataset contains in total XX individual translations of YY articles. X articles have a Ukrainian version, Y a Russian and Z an Engish one.
The dataset has X individual tags, of which the most common ones are shown in the table below: TODO
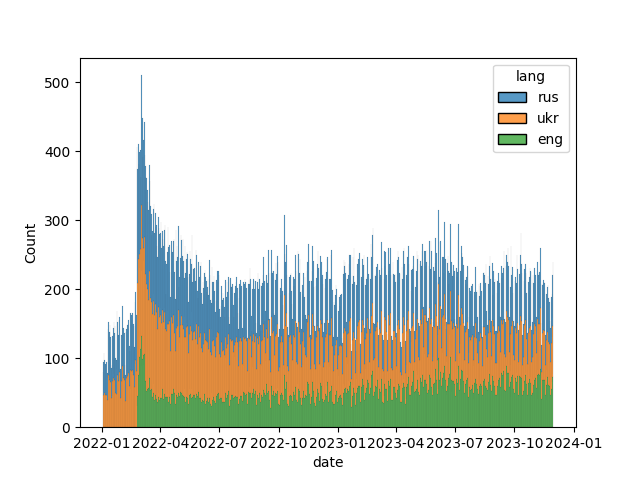
The dataset contains articles published from the 01.01.2022 to X, since UP drastically increased the amount of articles translated to English after the start of the full-scale invasion on the 24.02.2022 7 , (see picture below; TODO better x axis angle on plot).
Mitigations of issues found in multilingual datasets
A recent (2022) manual audit of available crawled multilingual datasets found surprisingly low amounts of in-language data and systematic issues in many of them. 8
Some issues raised in the paper in the context of this dataset:
- Using standard unambiguous ISO 639-3 language codes (ukr, rus, eng). ISO 639-3 was chosen instead of the more common ISO 639-1 (uk, ru, en) because of the possibly ambiguous ‘uk’ that can be associated with Great Britain as well. Interestingly, the more familiar ‘UA’ is a valid ISO code for the country, but not the language.
- The language identification was performed from the URL of the page (in turn labeled by UP), not through automated language identification processes (especially relevant in light of the ukr/rus disambiguation issues discussed in section XXX)
- The texts themselves were written by proficient language users, as opposed to automated translations.
- The dataset is digital-first(TODO word for this): no errors were introduced by OCR, incorrect layout parsing(TODO cite FinDE) or similar.
- I manually checked random articles from the dataset to make sure the different translations are indeed text, in the correct languages, and actually refer to the same article.
Licensing questions
According to Ukrainian law, newpaper-like articles aren’t subject to copyright. According to UP’s rules on the matter9, reprinting (..) in other online-newspapers is free but requires a link to the UP article not later than the second paragraph. Using the materials for commercial reasons is forbidden.
I believe releasing this dataset under the CC BY-NC 4.0 license (that allows sharing and adaptation only with attribution and for non-commercial use), with clear attribution to UP in the name and the description of the dataset, fulfills the applicable obligations both in letter and in spirit.
The dataset is released at https://huggingface.co/datasets/shamotskyi/ukr_pravda_2y
Similar datasets
- UA News classification - ua-datasets / fido-ai/ua-datasets: A collection of datasets for Ukrainian language
- Yehor/ukrainian-news-headlines · Datasets at Hugging Face
- zeusfsx/ukrainian-news · Datasets at Hugging Face
Appendix A: regexes for skipping paragraphs in UPravda dataset
Some UP articles have short paragraphs in the style of “follow us on Twitter” at the end. They have little to do with the actual article, so they were removed from the article text in the dataset.
All paragraphs containing text matching any of the lines/regexes below were filtered out:
"Follow (us|Ukrainska Pravda) on Twitter",
"Support UP",
"become our patron",
"(читайте|слухайте|слушайте) (також|также)", # "read/listen also to", in Russian and Ukrainian
Ways to make a downstream task out of this
- Tags
- News title|text -> tag
- cons: the tags UP uses seem chaotic and inconsistent?…
- Title
- Match title to news text
- Match title to rephrased/summarized news text
ChatGPT prompts for rephrasing the news
It suggested (https://chat.openai.com/share/2f6cf1f3-caf5-4e55-9c1b-3dbd6b73ba29) to me this prompt:
Будь ласка, перефразуйте цей текст, змінюючи порядок інформації та структуру повідомлення, уникаючи збігів слів та фразових конструкцій з оригіналом. Фокусуйтеся лише на ключових фактах, уникаючи зайвих деталей:
An improved version that seems to work ~better(https://chat.openai.com/share/14f12f87-50a8-438c-9d01-a0b076c3be12) :
Будь ласка, перефразуйте цей текст, змінюючи порядок інформації та структуру повідомлення, максимально уникаючи збігів слів та фразових конструкцій з оригіналом. Довжина статті має бути приблизно такою ж, як довжина оригіналу.
GPT3.5 works just as well if not better than GPT4 (and is much faster): https://chat.openai.com/share/78927782-25fa-4047-b2a4-fd01ee9a7a54
Can I also use this to generate tasks for the UA-CBT (231024-1704 Master thesis task CBT) task?
Here GPT4 is much better than GPT3. Can’t share either link because “disabled by moderation”(???).
Interestingly, GPT3.5 used definitely Russian chiches that I document in 231214-1251 Masterarbeit benchmark task for Russian-Ukrainian interference.
Eval downstream task decision
[[231010-1003 Masterarbeit Tagebuch#2023-12-15]]
- Solution: article text -> title, out of X options
- give ~10 options with
- ~3 random from the dataset
- ~7 from similar articles from the dataset, e.g. all of the same topic ‘war’
- give ~10 options with
-
<_(@inbook) “Analysis of references across wikipedia languages” (2017) / Włodzimierz Lewoniewski, Krzysztof Węcel, Witold Abramowicz: z / / 10.1007/978-3-319-67642-5_47 _> ↩︎
-
Рейтинг топсайтів України | Інститут масової інформації, linked on Українська правда — Вікіпедія ↩︎
-
Compliance with professional standards in online media. The fourth wave of monitoring in 2021 | Institute of Mass Information ↩︎
-
<_(@Schonfeld2009) “Sitemaps: Above and beyond the crawl of duty” (2009) / Uri Schonfeld, Narayanan Shivakumar: z / https://dl.acm.org/doi/10.1145/1526709.1526842 / 10.1145/1526709.1526842 _> ↩︎
-
Ethics in Web Scraping. We all scrape web data. Well, those of… | by James Densmore | Towards Data Science ↩︎
-
https://www.pravda.com.ua/tags/; https://www.pravda.com.ua/rus/tags/ ↩︎
-
<_(@10.1162/tacl_a_00447) “Quality at a glance: An audit of web-crawled multilingual datasets” (2022) / Julia Kreutzer, Isaac Caswell, Lisa Wang, Ahsan Wahab, Daan van Esch, Nasanbayar Ulzii-Orshikh, Allahsera Tapo, Nishant Subramani, Artem Sokolov, Claytone Sikasote, Monang Setyawan, Supheakmungkol Sarin, Sokhar Samb, Benoît Sagot, Clara Rivera, Annette Rios, Isabel Papadimitriou, Salomey Osei, Pedro Ortiz Suarez, Iroro Orife, Kelechi Ogueji, Andre Niyongabo Rubungo, Toan Q. Nguyen, Mathias Müller, André Müller, Shamsuddeen Hassan Muhammad, Nanda Muhammad, Ayanda Mnyakeni, Jamshidbek Mirzakhalov, Tapiwanashe Matangira, Colin Leong, Nze Lawson, Sneha Kudugunta, Yacine Jernite, Mathias Jenny, Orhan Firat, Bonaventure F. P. Dossou, Sakhile Dlamini, Nisansa de Silva, Sakine Çabuk Ballı, Stella Biderman, Alessia Battisti, Ahmed Baruwa, Ankur Bapna, Pallavi Baljekar, Israel Abebe Azime, Ayodele Awokoya, Duygu Ataman, Orevaoghene Ahia, Oghenefego Ahia, Sweta Agrawal, Mofetoluwa Adeyemi: z / https://doi.org/10.1162/tacl_a_00447 / 10.1162/tacl_a_00447 _> ↩︎
-
Правила використання матеріалів сайтів Інтернет-холдингу ‘‘Українська правда’’ (Оновлено) | Українська правда ↩︎