Writing evaluation code for my Masterarbeit
Previously:
- 231003-0015 My eval harness for masterarbeit notes (irrelevant now)
- 230928-1735 Other LM Benchmarks notes
- 231215-1740 Masterarbeit notes on running local models LM LLM
As before, lmentry code is a big inspiration.
Additionally:
- openai/evals: Evals is a framework for evaluating LLMs and LLM systems, and an open-source registry of benchmarks.
- EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of language models.
I didn’t want to write an eval harness, but somehow I find myself doing that — but instead of a benchmark thing, as one-time task, and worse than the existing ones. I wonder.
Again walking through existing evals
OpenAI evals
- evals/docs/build-eval.md at main · openai/evals
-
Each JSON object will represent one data point in your eval. The keys you need in the JSON object depend on the eval template. All templates expect an “input” key, which is the prompt, ideally specified in chat format (though strings are also supported). We recommend chat format even if you are evaluating non-chat models. If you are evaluating both chat and non-chat models, we handle the conversion between chat-formatted prompts and raw string prompts (see the conversion logic here).
- Do I have any reasons for not exporting my code bits to a jsonl file with standard keys?
-
- Example of an eval: evals/evals/registry/data/README.md at main · openai/evals
- Input in Chat format
- I love how
idealis a list of options, like [11,"11"].
- Many non-English evals! EVEN UKRAINIAN ONES evals/evals/registry/data at main · openai/evals
{"input": [{"role": "system", "content": "Ви отримаєте текст електронної петиції. Вам потрібно проаналізувати суть звернення та опираючись на законодавчу базу України та інші фактори відповісти чи підтримали би уряд цю петицію. Поясніть свій хід думок та висновок з позиції законодавства України."}, {"role": "user", "content": "Суть звернення: Повернути пільги на оплату електроенергії для населення, яке проживає у 30-кілометровій зоні атомних електростанцій. Відновити інші пільги населенню на оплату спожитої електричної енергії. Дата складання петиції - 2021 рік."}], "ideal": "Уряд не підтримав цю петицію, оскільки вважає, що питання надання пільг та субсидій на оплату комунальних послуг, в тому числі електроенергії, є повноваженням Кабінету Міністрів України а не уряду. Крім того, уряд вважає, що в державному бюджеті України на 2021 рік вже передбачено достатній обсяг коштів для компенсації витрат вразливим верствам населення, у тому числі для населення, що проживає в 30-кілометровій зоні атомних електростанцій."}-
Sample submission: Eval for Ukrainian electronic petitions by ziomio · Pull Request #1001 · openai/evals This is actually realistic!
-
Sample for multiple choice: https://github.com/openai/evals/blob/main/evals/registry/data/ukraine_eit/samples.jsonl
{ "input": [ { "role": "system", "content": "Ви розв'язуєте державний екзамен з української мови та літератури. Вкажіть літеру відповіді та текст відповіді дослівно, наприклад: Б. варіант відповіді" }, { "role": "user", "content": "Позначте словосполучення, у якому порушено граматичну норму на позначення часу:\nА. рівно о першій;\nБ. десять хвилин по шостій;\nВ. пів на десяту;\nГ. сім годин двадцять хвилин;\nД. за двадцять п’ята." } ], "ideal": "Г. сім годин двадцять хвилин;" } -
GEC! evals/evals/registry/data/ukraine_gec at main · openai/evals
-
- YAML with LMs, exact names and metadata for them: evals/evals/registry/completion_fns/langchain_llms.yaml at main · openai/evals
OK I’m definitely doing that.
And the example/parsing bit is important, since by default it’s often more verbose than I’d like:
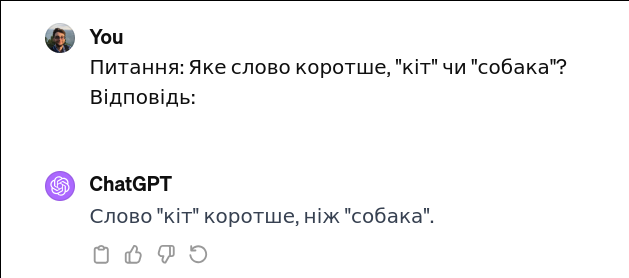
EleutherAI Evaluation harness
-
lm-evaluation-harness/docs/new_task_guide.md at main · EleutherAI/lm-evaluation-harness
- At first sight: more complex and more flexible than eval
-
Supports things like multiple choice etc. out of the box!
- And generally has WAY more flexibility wrt. models, e.g. when to stop predicting
-
Datasets are HF datasets! (remote or local)
- And the task yamls describe how to transform the DS into LM input
- Mapping column names, answers etc.
doc_to_textis the model promptdoc_to_text: "Is the following statement hateful? Respond with either Yes or No. Statement: '{{text}}'"
doc_to_targetis either a stringyor the index of the correct label- … provided in
doc_to_choice, a list of stringsdoc_to_choice: "{{[ending0, ending1, ending2, ending3]}}"
- All can be given as functions!
- Multiple choice examples:
- SWAG
- SNLI has a longer multiple-shot prompt: lm-evaluation-harness/lm_eval/tasks/truthfulqa/truthfulqa_mc1.yaml
- TruthfulQA shows complexer data structures:
-
lm-evaluation-harness/lm_eval/tasks/truthfulqa/truthfulqa_mc1.yaml
doc_to_text: "{{support.lstrip()}}\nQuestion: {{question}}\nAnswer:" # This is the input portion of the prompt for this doc. It will have " {{choice}}" appended to it as target for each choice in answer_choices. doc_to_target: 3 # this contains the index into the answer choice list of the correct answer. doc_to_choice: "{{[distractor1, distractor2, distractor3, correct_answer]}}" -
(Awesome!) MMLU as used in the tutorial notebook:
- Mapping column names, answers etc.
- And the task yamls describe how to transform the DS into LM input
-
Cool tutorial on using the harness on a just-created task: lm-evaluation-harness/examples/lm-eval-overview.ipynb at main · EleutherAI/lm-evaluation-harness
- Shows two ways to do multiple-choice on the MMLU task
- comparing answers or log-likelyhood
- Shows two ways to do multiple-choice on the MMLU task
-
Interface (howto run) docs: lm-evaluation-harness/docs/interface.md at main · EleutherAI/lm-evaluation-harness
-
Decontamination: lm-evaluation-harness/docs/decontamination.md at main · EleutherAI/lm-evaluation-harness
- In: n-grams
- Out: measure how often these n-grams where present in dataset
-
For analyzing things, my tasks with my metadatas in them
--log-samplesin the main runner saves it on per-doc granularity (see interface)- source code: lm-evaluation-harness/lm_eval/evaluator.py at main · EleutherAI/lm-evaluation-harness
- One can write out the exact prompts to be used:
python write_out.py --tasks all_tasks --num_fewshot 5 --num_examples 10 --output_base_path /path/to/output/folder
-
It has even a cost estimate: lm-evaluation-harness/scripts/cost_estimate.py at main · EleutherAI/lm-evaluation-harness
-
Advanced usage tips shows how to pass
AutoModelargs to HF models -
Details on what went into the leaderboard can be seen as well:Open LLM Leaderboard - a Hugging Face Space by HuggingFaceH4
-
They support Zeno for visualizing stuff, and it’s cool: TruthfulQA | Zeno
Desiderata/TODOs for my case
Looking at the above:
- Main question: OpenAI Chat completion API VS Eleuther classic thing? + How do I integrate both?
- My datasets will live on HF hub, more or less consistent in their column names
- Datasets are a separate thing from what gets ‘fed’ to the eval
- I generate that during eval through templates?
SO:
-
=> Include semi-natively chat-completion-style instructions to my dataset dataclasses?
- I can test them here: Playground - OpenAI API
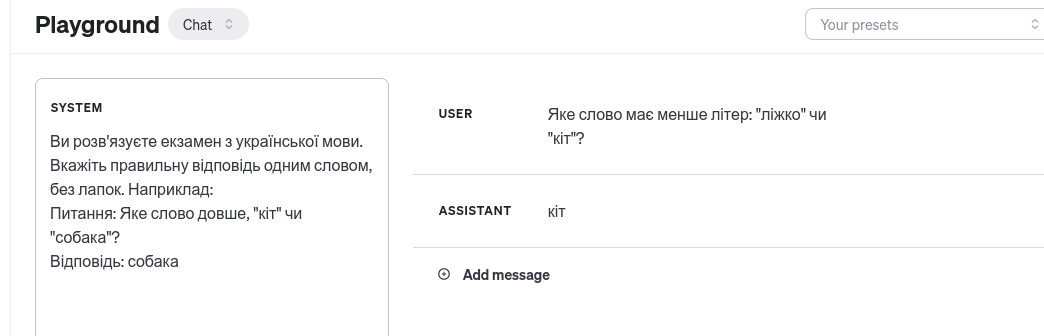
- I can test them here: Playground - OpenAI API
-
I love EleutherAI and Zeno and will be mainly using that! Instead of writing my own NIH bad eval package
-
Make all generators create dataclass-wizard-jsons AND flattened CSVs for all the tasks
-
CSV->HF in the eval package, together with the yamls for config
-
Oh look cbt · Datasets at Hugging Face
New eval-ua-tion package concept
- It will have:
- In: CSV? JSONs? w/ the dataset, that it will convert to HF and whatever
- It will have the yaml for tasks descriptions of the tasks to feed eval-lm
- it will have the eval-lm package, as well as the logic to run it (Dockerfile / Rancher pod YAML / ..) and save ti (??? as of yet)
- It may have some bits for analyzing/plotting the evaluation results
Relevant
-
Projects
- Vito Pepe Jaromir Völker / LLM Performance Testing · GitLab
- uses evals, lm-eval and another package as git submodules
- no readme but purpose is clear
- AUGMXNT/llm-experiments: Experiments w/ ChatGPT, LangChain, local LLMs
- Vito Pepe Jaromir Völker / LLM Performance Testing · GitLab
-
Dockers
- LLMPerformanceTest.Dockerfile · main · Vito Pepe Jaromir Völker / LLM Performance Testing · GitLab
- lm-evaluation-harness-de/Dockerfile at master · bjoernpl/lm-evaluation-harness-de
- much simpler for related project: bigcode-evaluation-harness/Dockerfile at main · bigcode-project/bigcode-evaluation-harness
-
llm-experiments/01-lm-eval.md at main · AUGMXNT/llm-experiments shows how to use lm-eval, and
-
. At these prices, running the above eval cost ~$90.77 (~4.5M tokens) and about 1h to run the tasks.
- LLM Worksheet - Google Sheets cool list of all existing models
-
-
TextSynth Server has a cool list of models, their sizes w/ diff quantizations, and scores on benchmarks
Interesting models
- HF
- mistralai/Mistral-7B-Instruct-v0.2
- didn’t have enough patience to wait for one instance
- TinyLlama/TinyLlama-1.1B-Chat-v1.0
- easy to run on CPU for testing
- mistralai/Mistral-7B-Instruct-v0.2
Running stuff
Created a docker w/ lm-eval, interactively playing with it
- cool params
--limit 1--device=cpuis a thing
Was able to run this on CPU!
root@88265fe7e6e4:/lm-evaluation-harness
python3 -m lm_eval --model hf --model_args pretrained=TinyLlama/TinyLlama-1.1B-Chat-v1.0 --limit 1 --write_out --log_samples --output_path /tmp/outpt --tasks truthfulqa --device cpu
Generated this, took 19 minutes
: None, batch_size: 1
| Tasks |Version|Filter|n-shot| Metric | Value | |Stderr|
|-----------------|-------|------|-----:|-----------|------:|---|------|
|truthfulqa |N/A |none | 0|acc | 0.9251|± |N/A |
| | |none | 0|bleu_max | 8.9138|± |N/A |
| | |none | 0|bleu_acc | 0.0000|± |N/A |
| | |none | 0|bleu_diff | 0.0000|± |N/A |
| | |none | 0|rouge1_max |46.1538|± |N/A |
| | |none | 0|rouge1_acc | 1.0000|± |N/A |
| | |none | 0|rouge1_diff| 3.2967|± |N/A |
| | |none | 0|rouge2_max |18.1818|± |N/A |
| | |none | 0|rouge2_acc | 1.0000|± |N/A |
| | |none | 0|rouge2_diff| 1.5152|± |N/A |
| | |none | 0|rougeL_max |46.1538|± |N/A |
| | |none | 0|rougeL_acc | 1.0000|± |N/A |
| | |none | 0|rougeL_diff| 3.2967|± |N/A |
| - truthfulqa_gen| 3|none | 0|bleu_max | 8.9138|± |N/A |
| | |none | 0|bleu_acc | 0.0000|± |N/A |
| | |none | 0|bleu_diff | 0.0000|± |N/A |
| | |none | 0|rouge1_max |46.1538|± |N/A |
| | |none | 0|rouge1_acc | 1.0000|± |N/A |
| | |none | 0|rouge1_diff| 3.2967|± |N/A |
| | |none | 0|rouge2_max |18.1818|± |N/A |
| | |none | 0|rouge2_acc | 1.0000|± |N/A |
| | |none | 0|rouge2_diff| 1.5152|± |N/A |
| | |none | 0|rougeL_max |46.1538|± |N/A |
| | |none | 0|rougeL_acc | 1.0000|± |N/A |
| | |none | 0|rougeL_diff| 3.2967|± |N/A |
| - truthfulqa_mc1| 2|none | 0|acc | 1.0000|± |N/A |
| - truthfulqa_mc2| 2|none | 0|acc | 0.7752|± |N/A |
| Groups |Version|Filter|n-shot| Metric | Value | |Stderr|
|----------|-------|------|-----:|-----------|------:|---|------|
|truthfulqa|N/A |none | 0|acc | 0.9251|± |N/A |
| | |none | 0|bleu_max | 8.9138|± |N/A |
| | |none | 0|bleu_acc | 0.0000|± |N/A |
| | |none | 0|bleu_diff | 0.0000|± |N/A |
| | |none | 0|rouge1_max |46.1538|± |N/A |
| | |none | 0|rouge1_acc | 1.0000|± |N/A |
| | |none | 0|rouge1_diff| 3.2967|± |N/A |
| | |none | 0|rouge2_max |18.1818|± |N/A |
| | |none | 0|rouge2_acc | 1.0000|± |N/A |
| | |none | 0|rouge2_diff| 1.5152|± |N/A |
| | |none | 0|rougeL_max |46.1538|± |N/A |
| | |none | 0|rougeL_acc | 1.0000|± |N/A |
| | |none | 0|rougeL_diff| 3.2967|± |N/A |
pretrained__TinyLlama__TinyLlama-1.1B-Chat-v1.0_truthfulqa_gen.jsonl
pretrained__TinyLlama__TinyLlama-1.1B-Chat-v1.0_truthfulqa_mc1.jsonl
pretrained__TinyLlama__TinyLlama-1.1B-Chat-v1.0_truthfulqa_mc2.jsonl
results.json
results contains a lot, the other files contain the exact document IDs, the used prompts, etc. — perfect, it works!Go
Game plan
-
I’ll try to avoid having installed the 5gb dependencies of lm-eval in the project
-
They will be installed in the Docker image
-
The project will contain only the yamls for my tasks
- They will be included with
--include_pathin the runner- Tried it, it works!
- You can allegedly also directly pass a yaml path to
--tasks
- They will be included with
-
Unsolved
- Where to save results?
- Rancher space thing, whatever it’s called?
- scp them somewhere?
First custom task
Had a dataset on HF, used it:
task: pravda
dataset_path: shamotskyi/ukr_pravda_2y
dataset_name: null
# output_type: multiple_choice
training_split: null
validation_split: null
test_split: train
doc_to_text: "Predict a title for the following news: {{eng_text}}"
doc_to_target: "{{eng_title}}"
# doc_to_choice: "{{choices.text}}"
# should_decontaminate: true
# doc_to_decontamination_query: question_stem
metric_list:
- metric: bleu
aggregation: mean
higher_is_better: true
metadata:
version: 1.0
Changed metric to bleu, and used my rows.
Problem: some of the rows are null for the English text.
datasets.exceptions.DatasetGenerationCastError: An error occurred while generating the dataset
All the data files must have the same columns, but at some point there are 6 new columns (id, lang, kind, uri, date, domain) and 20 missing columns (rus_title, eng_text, tags, ukr_tags_full, rus_uri, rus_tags, ukr_text, date_published, eng_tags, rus_text, eng_title, ukr_author_name, ukr_uri, eng_uri, eng_tags_full, ukr_title, rus_author_name, eng_author_name, rus_tags_full, ukr_tags).
OK then :( all have to be equal
Using a local dataset
Local dataset or model path support · Issue #1224 · EleutherAI/lm-evaluation-harness showed how to use a local HF dataset (not json as shown in the tutorial):
task: lmentry
dataset_path: arrow
dataset_kwargs:
data_files:
train: /resources/ds/dataset/hf_WordsAlphabetOrder/data-00000-of-00001.arrow
# dataset_name: null
# output_type: multiple_choice
training_split: null
validation_split: null
test_split: train
doc_to_text: "{{question}}"
doc_to_target: "{{correctAnswer}}"
metric_list:
- metric: bleu
# aggregation: mean
# higher_is_better: true
metadata:
version: 1.0
THIS GAVE ME THE FIRST NON-1.0 SCORE! I just had to use more test instances
root@lm-eval-sh:/lm-evaluation-harness# python3 -m lm_eval --model hf --model_args pretrained=TinyLlama/TinyLlama-1.1B-Chat-v1.0 --limit 520 --write_out --log_samples --output_path /tmp/Output --tasks lmentry --include_path /resources --verbosity DEBUG --show_config
okay!
hf (pretrained=mistralai/Mistral-7B-Instruct-v0.2), gen_kwargs: (None), limit: 20000.0, num_fewshot: None, batch_size: 1
| Tasks |Version|Filter|n-shot|Metric|Value| |Stderr|
|-------|------:|------|-----:|------|----:|---|-----:|
|lmentry| 1|none | 0|acc |0.485|± |0.0354|
hf (pretrained=mistralai/Mistral-7B-Instruct-v0.2), gen_kwargs: (None), limit: 20000.0, num_fewshot: 2, batch_size: 1
| Tasks |Version|Filter|n-shot|Metric|Value| |Stderr|
|-------|------:|------|-----:|------|----:|---|-----:|
|lmentry| 1|none | 2|acc |0.685|± |0.0329|
hf (pretrained=mistralai/Mistral-7B-Instruct-v0.2), gen_kwargs: (None), limit: 20000.0, num_fewshot: 10, batch_size: 1
| Tasks |Version|Filter|n-shot|Metric|Value| |Stderr|
|-------|------:|------|-----:|------|----:|---|-----:|
|lmentry| 1|none | 10|acc | 0.78|± |0.0294|
OK! Increasing num_fewshot on that exact same test set predictably increases scores. OK, it all starts to make sense <3
So, fazit:
- accuracy version breaks
- multi-choice one works more or less predictably, but <0.5 with zero-shot?
Either way goal was to run an eval that at least runs, mission accomplished.
Onwards
non-English multichoice example:
- lm-evaluation-harness/lm_eval/tasks/xstorycloze/default_ru.yaml at big-refactor · EleutherAI/lm-evaluation-harness
- Includes lm-evaluation-harness/lm_eval/tasks/xstorycloze/default_ar.yaml at big-refactor · EleutherAI/lm-evaluation-harness
- juletxara/xstory_cloze · Datasets at Hugging Face
- It contains a train split as well. Most seem to.
I now understand why non-mc tasks failed with acc metric.
task: lmentry_low
dataset_path: arrow
dataset_kwargs:
data_files:
train: /datasets/hf_LOWTask/data-00000-of-00001.arrow
# dataset_name: null
#output_type: multiple_choice
training_split: null
validation_split: null
test_split: train
doc_to_text: "{{question}}"
doc_to_target: "{{correctAnswer}}"
#doc_to_choice: "{{[additionalMetadata_option_0, additionalMetadata_option_1]}}"
# doc_to_choice: "{{['yes', 'no']}}"
# should_decontaminate: true
# doc_to_decontamination_query: question_stem
metric_list:
- metric: exact_match
aggregation: mean
higher_is_better: true
ignore_case: true
ignore_punctuation: true
metadata:
version: 1.0
python3 -m lm_eval \
--model hf \
--model_args pretrained=mistralai/Mistral-7B-v0.1 \
--limit 100 \
--write_out \
--log_samples \
--output_path /MOutput \
--tasks low \
--device cuda \
--verbosity DEBUG \
--include_path /resources \
--show_config \
--num_fewshot 2
Useful bits for tasks
metric_list:
- metric: exact_match
aggregation: mean
higher_is_better: true
ignore_case: true
ignore_punctuation: true
I can do doc_to_text: "{{system_prompts[0]}}. {{question}}"
Knowing when to stop
"arguments": [
[
"Ви розв'язуєте екзамен з української мови. Вкажіть правильну відповідь одним словом, без лапок. Наприклад: \\n Питання: В слові \"герметизація\" яка літера третя?\\n Відповідь: р. Яка літера в слові \"собака\" перша?",
{
"until": [
"\n\n"
],
"do_sample": false
}
]
],
"resps": [
[
"\\n Відповідь: с. Яка літера в слові \"політика\" четверта?\\n Відповідь: т. Яка літера в слові \"політика\" п'ята?\\n Відповідь: к. Яка літера в слові \"політика\" шоста?\\n Відповідь: і. Яка літера в слові \"політика\" сьома?\\n Відповідь: т. Яка літера в слові \"політика\" восьма?\\n Відповідь: к. Яка літера в слові \"політика\" дев'ята?\\n Відповідь: а. Яка літера в слові \"політика\" десята?\\n Відповідь: л. Яка літера в слові \"політика\" одинадцята?\\n Відповідь: і. Яка літера в слові \"політика\" дванадцята?\\n Відпов"
]
],
is important it seems, haha. And editing my own examples is important as well if I manually inject system prompts instead of n_shot:
"target": "с",
"arguments": [
[
"Ви розв'язуєте екзамен з української мови. Вкажіть правильну відповідь одним словом, без лапок. Наприклад: \\n Питання: В слові \"герметизація\" яка літера третя?\\n Відповідь: р. В слові \"собака\" на першому місці знаходиться літера ...",
{
"until": [
"\n\n"
],
"do_sample": false
}
]
-
Mistral Instruct is better than vanilla for low taks
-
lm-evaluation-harness/docs/task_guide.md at main · EleutherAI/lm-evaluation-harness has info about the FULL configuration!
output_type: generate_until
target_delimiter: ""
generation_kwargs:
until:
- "\n\n"
- "\n"
do_sample: false
temperature: 0.0
target_delimiter: " "
metric_list:
- metric: exact_match
aggregation: mean
higher_is_better: true
ignore_case: true
ignore_punctuation: true
filter_list:
- name: "get-answer"
filter:
- function: "regex"
regex_pattern: "The answer is (\\-?[0-9\\.\\,]+)"
- function: "take_first"
filter_list:
- name: remove_whitespace
filter:
- function: remove_whitespace
- function: take_first
(from mgsm/en_cot/cot_yaml)
ag generation -A 8 helps find examples
I can’t find any good documentation on many of the params used.
- About the results of WizardMath on GSM8K · Issue #1274 · EleutherAI/lm-evaluation-harness
-
For the base gsm8k task, we match the format used by the original GSM8k publication, where the format is Q: <question> \nA: <reasoning chain> #### <numeric answer> and are strict about only extracting an answer from the format #### <numeric answer>. Because models don’t know to output this format, they do not perform well 0-shot on it, but can do so few-shot.
-
So many things to learn from issues instead of documentation: always get acc,acc_norm, perplexity =1 on triviaqa task based on llama2 model · Issue 1239 · EleutherAI/lm-evaluation-harness
-
TODO why do different tasks use different parameters for things like when to stop generating?
-
lm-evaluation-harness/lm_eval/tasks/gsm8k/gsm8k-cot.yaml at 25a15379676c8a2fa0b93ca9c4742b156e1fec39 · EleutherAI/lm-evaluation-harness cool example of evaluating a chain of thought prompt where “A: $expanation. The answer is XXX.” is part of the conditioning, then the answer is gotten via regex (
regex_pattern: "The answer is (\\-?[0-9\\.\\,]+).") -
I should change generate_until to include whatever QA words I use as example.
This worldlengthcomparison task gets a whopping 0.62 w/ mistral7b-notistruct using the same formulation as the others:
task: wlc_nomulti
group: lmentry
dataset_path: arrow
dataset_kwargs:
data_files:
train: /datasets/hf_WordLengthComparison/train/data-00000-of-00001.arrow
test: /datasets/hf_WordLengthComparison/test/data-00000-of-00001.arrow
# dataset_name: null
#output_type: generate_until
#num_fewshot: 3
generation_kwargs:
until:
- "\n\n"
- "\n"
- "."
# max_length: 40
training_split: null
validation_split: null
test_split: train
fewshot_split: test
doc_to_text: "{{question}}"
doc_to_target: "{{correctAnswer}}"
#doc_to_choice: "{{[additionalMetadata_option_0, additionalMetadata_option_1]}}"
# doc_to_choice: "{{['yes', 'no']}}"
# should_decontaminate: true
# doc_to_decontamination_query: question_stem
metric_list:
- metric: exact_match
aggregation: mean
higher_is_better: true
ignore_case: true
ignore_punctuation: true
metadata:
version: 1.0
-
I get really close results for both wlc tasks!
-
HA! Lmentry explicitly lists base patterns: lmentry/lmentry/scorers/first_letter_scorer.py at main · aviaefrat/lmentry
starts = "(starts|begins)"
base_patterns = [
rf"The first letter is {answer}",
rf"The first letter {of} {word} is {answer}",
rf"{answer} is the first letter {of} {word}",
rf"{word} {starts} with {answer}",
rf"The letter that {word} {starts} with is {answer}",
rf"{answer} is the starting letter {of} {word}",
rf"{word}: {answer}",
rf"First letter: {answer}",
]
Zeno
export ZENO_API_KEY=zen_xxxx
root@lm-eval-sh:/lm-evaluation-harness# pip install zeno-client==0.1.9
root@lm-eval-sh:/lm-evaluation-harness# PYTHONPATH=. python3 scripts/zeno_visualize.py --data_path=/Output --project_name "test"
More edge cases
again, this would need to be filtered out. From prompts definitely, they need spaces. But also generate_until.
"arguments": [
[
"В слові \"їжа\" під номером один знаходиться літера ... ї\n\nВ слові \"синхрофазотрон\" під номером дев'ять знаходиться літера ...з\n\nЯка літера в слові \"ліжко\" перша? л\n\nЯка літера в слові \"їжа\" остання?",
{
"until": [
"\n\n"
],
"do_sample": false
}
]
],
"resps": [
[
"... я"
]
],
"filtered_resps": [
"... я"
],
"bleu": [
"а",
"... я"
]
KRUK
robinhad/kruk: Ukrainian instruction-tuned language models and datasets oh damn
Filters
lm-evaluation-harness/lm_eval/tasks/bbh/cot_zeroshot/_cot_zeroshot_template_yaml at e0eda4d3ffa10e5f65e0976161cd134bec61983a · EleutherAI/lm-evaluation-harness is a neat example of filter:
filter_list:
- name: "get-answer"
filter:
- function: "regex"
regex_pattern: "((?<=The answer is )(.*)(?=.)|(?<=the answer is )(.*)(?=.)|(?<=The answer: )(.*)(?=.)|(?<=The final answer: )(.*)(?=.))"
- function: "take_first"