Huggingface dataset build configs
Goal: create multiple dataset configs for 231203-1745 Masterarbeit LMentry-static-UA task.
- Example: datasets/templates/new_dataset_script.py at main · huggingface/datasets
- Tutorial: Builder classes
- One example they give: https://huggingface.co/datasets/frgfm/imagenette/blob/main/imagenette.py
Developing:
- One can in
_URLSprovide paths to local files as well, to speed up development!
It’s not magic dictionaries, it’s basically syntax known to me (with Features etc.) which is neat!
elif self.config.name == "WhichWordWrongCatTask":
yield key, {
"question": data["question"],
"correctAnswer": data["correctAnswer"],
"options": data["additionalMetadata_all_options"]
# "second_domain_answer": "" if split == "test" else data["second_domain_answer"],
}
Ah, dataset viewer not available :( But apparently one can use manual configs and then it works: https://huggingface.co/docs/hub/datasets-manual-configuration
I can use https://huggingface.co/datasets/scene_parse_150/edit/main/README.md as an example here.
dataset_info:
- config_name: scene_parsing
features:
- name: image
dtype: image
- name: annotation
dtype: image
- name: scene_category
dtype:
class_label:
names:
'0': airport_terminal
'1': art_gallery
'2': badlands
- config_name: instance_segmentation
features:
- name: image
dtype: image
- name: annotation
dtype: image
…
This shows WISTask in the viewer, but not LOWTask (because 'str' object has no attribute 'items' )
configs:
- config_name: LOWTask
data_files: "data/tt_nim/LOWTask.jsonl"
features:
- name: question
dtype: string
- name: correctAnswer
dtype: string
default: true
- config_name: WISTask
data_files: "data/tt_nim/WISTask.jsonl"
And I can’t download either with python because
Traceback (most recent call last):
File "/home/sh/.local/lib/python3.8/site-packages/datasets/builder.py", line 1873, in _prepare_split_single
writer.write_table(table)
File "/home/sh/.local/lib/python3.8/site-packages/datasets/arrow_writer.py", line 568, in write_table
pa_table = table_cast(pa_table, self._schema)
File "/home/sh/.local/lib/python3.8/site-packages/datasets/table.py", line 2290, in table_cast
return cast_table_to_schema(table, schema)
File "/home/sh/.local/lib/python3.8/site-packages/datasets/table.py", line 2248, in cast_table_to_schema
raise ValueError(f"Couldn't cast\n{table.schema}\nto\n{features}\nbecause column names don't match")
ValueError: Couldn't cast
question: string
correctAnswer: string
templateUuid: string
taskInstanceUuid: string
additionalMetadata_kind: string
additionalMetadata_template_n: int64
additionalMetadata_option_0: string
additionalMetadata_option_1: string
additionalMetadata_label: int64
additionalMetadata_t1_meta_pos: string
additionalMetadata_t1_meta_freq: int64
additionalMetadata_t1_meta_index: int64
additionalMetadata_t1_meta_freq_quantile: int64
additionalMetadata_t1_meta_len: int64
additionalMetadata_t1_meta_len_quantile: string
additionalMetadata_t1_meta_word_raw: string
additionalMetadata_t2_meta_pos: string
additionalMetadata_t2_meta_freq: int64
additionalMetadata_t2_meta_index: int64
additionalMetadata_t2_meta_freq_quantile: int64
additionalMetadata_t2_meta_len: int64
additionalMetadata_t2_meta_len_quantile: string
additionalMetadata_t2_meta_word_raw: string
additionalMetadata_reversed: bool
additionalMetadata_id: int64
system_prompts: list<item: string>
child 0, item: string
to
{'question': Value(dtype='string', id=None), 'correctAnswer': Value(dtype='string', id=None), 'templateUuid': Value(dtype='string', id=None), 'taskInstanceUuid': Value(dtype='string', id=None), 'additionalMetadata_kind': Value(dtype='string', id=None), 'additionalMetadata_template_n': Value(dtype='int64', id=None), 'additionalMetadata_all_options': Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), 'additionalMetadata_label': Value(dtype='int64', id=None), 'additionalMetadata_main_cat_words': Sequence(feature=Value(dtype='string', id=None), length=-1, id=None), 'additionalMetadata_other_word': Value(dtype='string', id=None), 'additionalMetadata_cat_name_main': Value(dtype='string', id=None), 'additionalMetadata_cat_name_other': Value(dtype='string', id=None), 'additionalMetadata_id': Value(dtype='int64', id=None), 'system_prompts': Sequence(feature=Value(dtype='string', id=None), length=-1, id=None)}
because column names don't match
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "test.py", line 18, in <module>
ds = load_dataset(path, n)
File "/home/sh/.local/lib/python3.8/site-packages/datasets/load.py", line 1797, in load_dataset
builder_instance.download_and_prepare(
File "/home/sh/.local/lib/python3.8/site-packages/datasets/builder.py", line 890, in download_and_prepare
self._download_and_prepare(
File "/home/sh/.local/lib/python3.8/site-packages/datasets/builder.py", line 985, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/sh/.local/lib/python3.8/site-packages/datasets/builder.py", line 1746, in _prepare_split
for job_id, done, content in self._prepare_split_single(
File "/home/sh/.local/lib/python3.8/site-packages/datasets/builder.py", line 1891, in _prepare_split_single
raise DatasetGenerationError("An error occurred while generating the dataset") from e
datasets.builder.DatasetGenerationError: An error occurredwhile generating the dataset
Oh goddammit. Relevant:
- pytorch - Load dataset with datasets library of huggingface - Stack Overflow
- python - Huggingface datasets ValueError - Stack Overflow is an issue because he loaded it locally
- machine learning - Huggingface Load_dataset() function throws “ValueError: Couldn’t cast” - Stack Overflow also Ukrainian
I give up.
Back to the script.
Last thing I’ll try (as suggested by tau/scrolls · Dataset Viewer issue: DatasetWithScriptNotSupportedError):
Convert Dataset To Parquet - a Hugging Face Space by albertvillanova
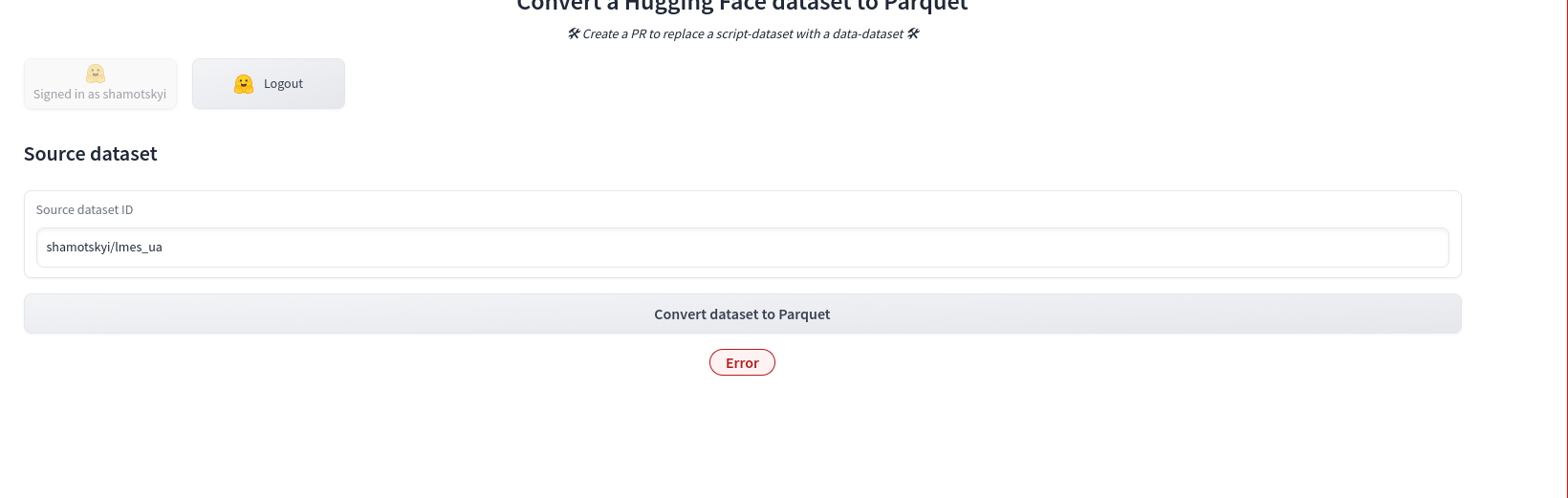
…
feels so unsatisfying not to see the datasets in the viewer :(
tau/scrolls · Dataset Viewer issue: DatasetWithScriptNotSupportedError this feels like something relevant to me. We’ll see.