Masterarbeit eval task LMentry-static-UA
Context: 220120-1959 taskwarrior renaming work tasks from previous work
First notes
Just tested this: DAMN!
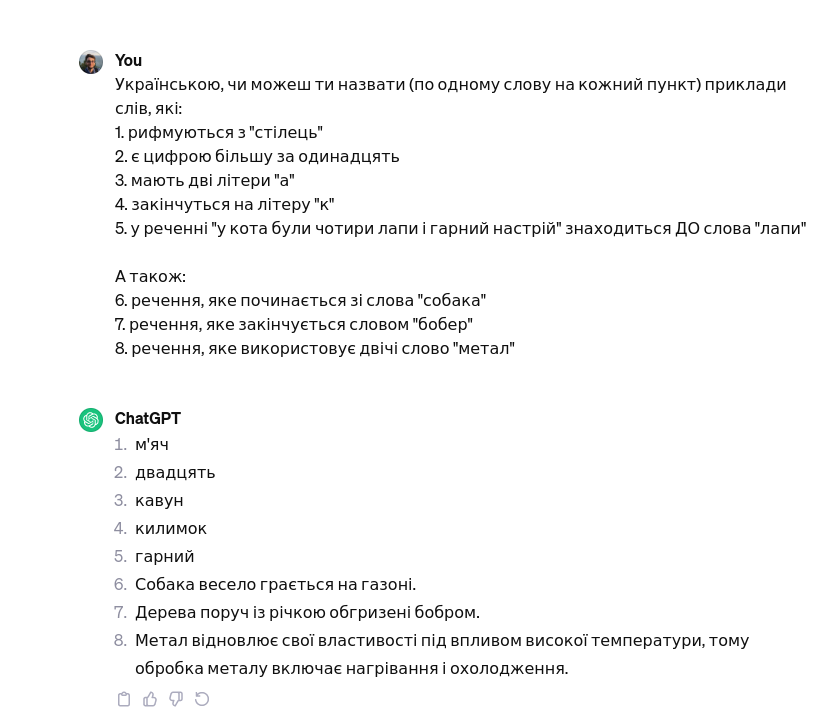
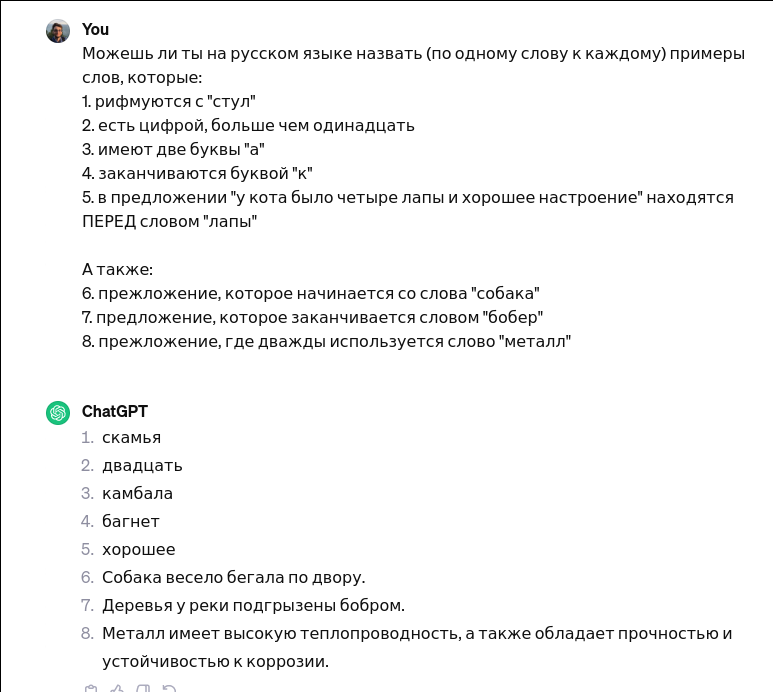
User
Can you, in English, name one word for each of these tasks:
1. Rhymes with "chair"
2. Is a number larger than eleven
3. Has two letters "a"
4. Ends with the letter "k"
5. In the sentence "the cat had four paws and a good mood" is BEFORE the word "paws"
Also:
6. A sentence that starts with the word "dogs"
7. A sentence that ends with the word "beaver"
8. A sentence that uses the word "metal" twice
https://chat.openai.com/share/3fdfaf05-5c13-44eb-b73f-d66f33b73c59
lmentry/data/all_words_from_category.json at main · aviaefrat/lmentry
Not all of it needs code and regexes! lmentry/data/bigger_number.json at main · aviaefrat/lmentry
I can really do a small lite-lite subset containing only tasks that are evaluatable as a dataset.
LMentry-micro-UA
// minimal, micro, pico
Plan:
- go methodically through all of those task, divide them into regex and not regex, clone the code translate the prompts generate the dataset
Decision on 231010-1003 Masterarbeit Tagebuch#LMentry-micro-UA: doing a smaller version works!
LMentry-static-UA
Basics
Will contain only a subset of tasks, the ones not needing regex. They are surprisingly many.
The code will generate a json dataset for all tasks.
Implementation
Original task/code/paper analysis
- lmentry/resources at main · aviaefrat/lmentry has the JSONs with static words etc. used to generate the tasks
- lmentry/lmentry/predict.py at main · aviaefrat/lmentry contains the predicting code used to evaluate it using different kinds of models - I’ll need this later.
- tasks enumeration:
- lmentry/lmentry/constants.py at main · aviaefrat/lmentry list of all tested models
- static tasks (
won’timplement, completed):Sentence containing wordSentence not containing wordWord containing letterWord not containing letter- Most associated word
- Least associated word
- Any words from category
- All words from category
- First alphabetically
- More letters
- Less letters
- Bigger number
- Smaller number
- Rhyming word
HomophonesWon’t do because eight/ate won’t work in ukr- Word after in sentence
- Word before in sentence
Sentence starting with wordSentence ending with wordWord starting with letterWord ending with letter- First word of the sentence
- Last word of the sentence
- First letter of the word
- Last letter of the word
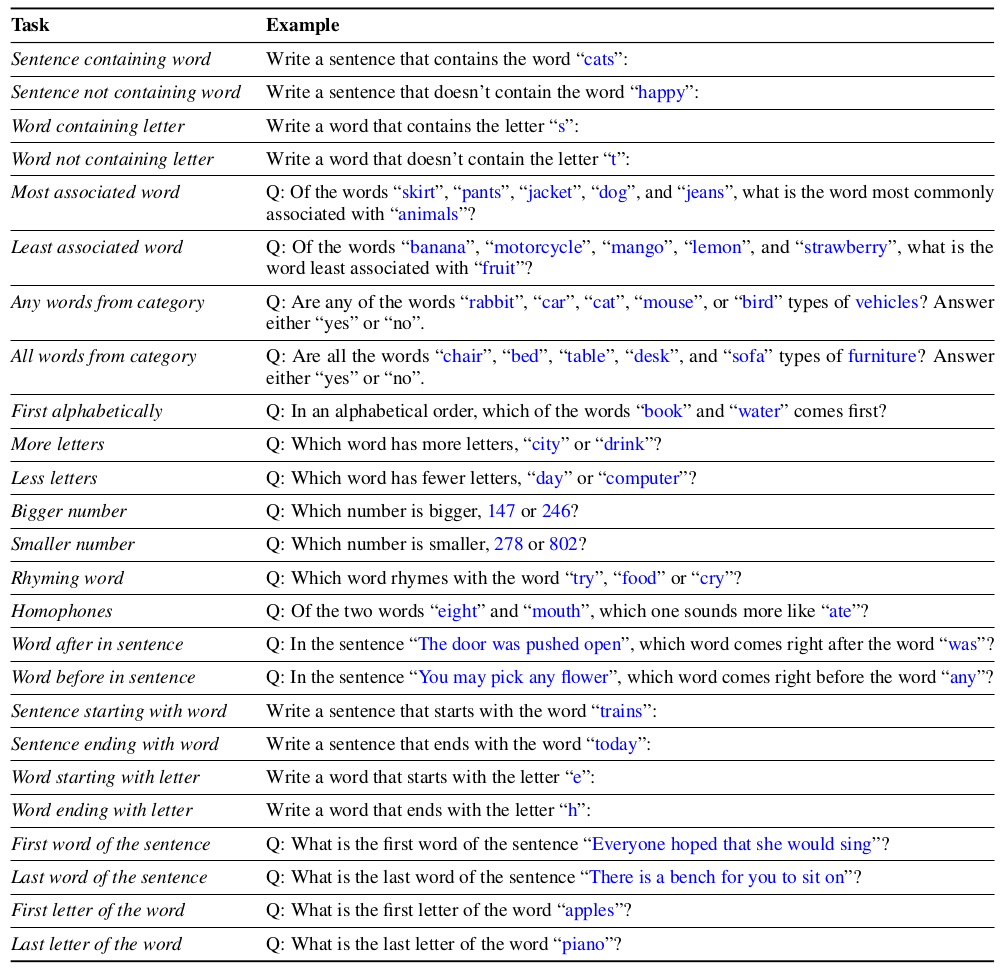 from the paper
from the paper Distractors
- order of words
- template content
- adj tasks VS arg. content
My changes
- I’d like to have words separated by:
- frequency
- length,
- … and maybe do cool analyses based on that
- (DONE) in addition to first/last letter/word in word/sentence, add arbitrary “what’s the fourth letter in the word ‘word’?”
- Longer/shorter words: add same length as option
My code bits
- I have to write it in a way that I can analyze it for stability wrt morphology etc. later
Ukrainian numerals creation
Problem: ‘1’ -> один/перший/(на) першому (місці)/першою
Existing solutions:
- pymorphy can inflect existing words but needs
- savoirfairelinux/num2words: Modules to convert numbers to words. 42 –> forty-two can’t do ordinals+case
Created my own! TODO document
TODO https://webpen.com.ua/pages/Morphology_and_spelling/numerals_declination.html
More tagsets fun
Parse(word='перша', tag=OpencorporaTag('ADJF,compb femn,nomn'), normal_form='перший', score=1.0, methods_stack=((DictionaryAnalyzer(), 'перша', 76, 9),))
compb
Nothing in docu, found it only in the Ukr dict converter tagsets mapping: LT2OpenCorpora/lt2opencorpora/mapping.csv at master · dchaplinsky/LT2OpenCorpora
I assume it should get converted to comp but doesn’t - yet another future bug report to pymorphy4
EDIT 2025-06-03: Casey Jones (caseyjones.us) emailed me with a much better explanation! Quoting (bold text mine):
The link you provide there to LT2OpenCorpora/lt2opencorpora/mapping.csv was helpful for me.
It lists:
- compb: базова форма
- compr: порівняльна форма
- super: найвища форма
You wrote:
I assume it should get converted to comp but doesn’t - yet another future bug report to pymorphy4
But I don’t think so. My interpretation of the above is that “compb” stands for “comparable BASE form”, which makes sense once you figure it out, but that should definitely be better documented. And it’s weird then that
comprandsuperaren’t consistently namedcompcandcompsrespectively, but whatever, I guess, if only people can figure out what they mean.
Even more tagsets fun
pymorphy2 doesn’t add the sing tag for Ukrainian singular words. Then any
inflection that deals with number fails.
Same issue I had in 231024-1704 Master thesis task CBT
Found a way around it:
@staticmethod
def _add_sing_to_parse(parse: Parse) -> Parse:
"""
pymorphy sometimes doesn't add singular for ukrainian
(and fails when needs to inflect it to plural etc.)
this creates a new Parse with that added.
"""
if parse.tag.number is not None:
return parse
new_tag_str = str(parse.tag)
new_tag_str+=",sing"
new_tag = parse._morph.TagClass(tag=new_tag_str)
new_best_parse = Parse(word=parse.word, tag=new_tag, normal_form=parse.normal_form, score=parse.score, methods_stack=parse.methods_stack)
new_best_parse._morph=parse._morph
return new_best_parse
# Not needed for LMentry, but I'll need it for CBT anyway...
@staticmethod
def _make_agree_with_number(parse: Parse, n: int)->Parse:
grams = parse.tag.numeral_agreement_grammemes(n)
new_parse = Numbers._inflect(parse=parse, new_grammemes=grams)
return new_parse
parse._morphis the Morph.. instance, without one added inflections of that Parse fail.TagClassfollows the recommendations of the docu2 that say better it than a newOpencorporaTag, even though both return the same class.
Notes by task
Taxonomy
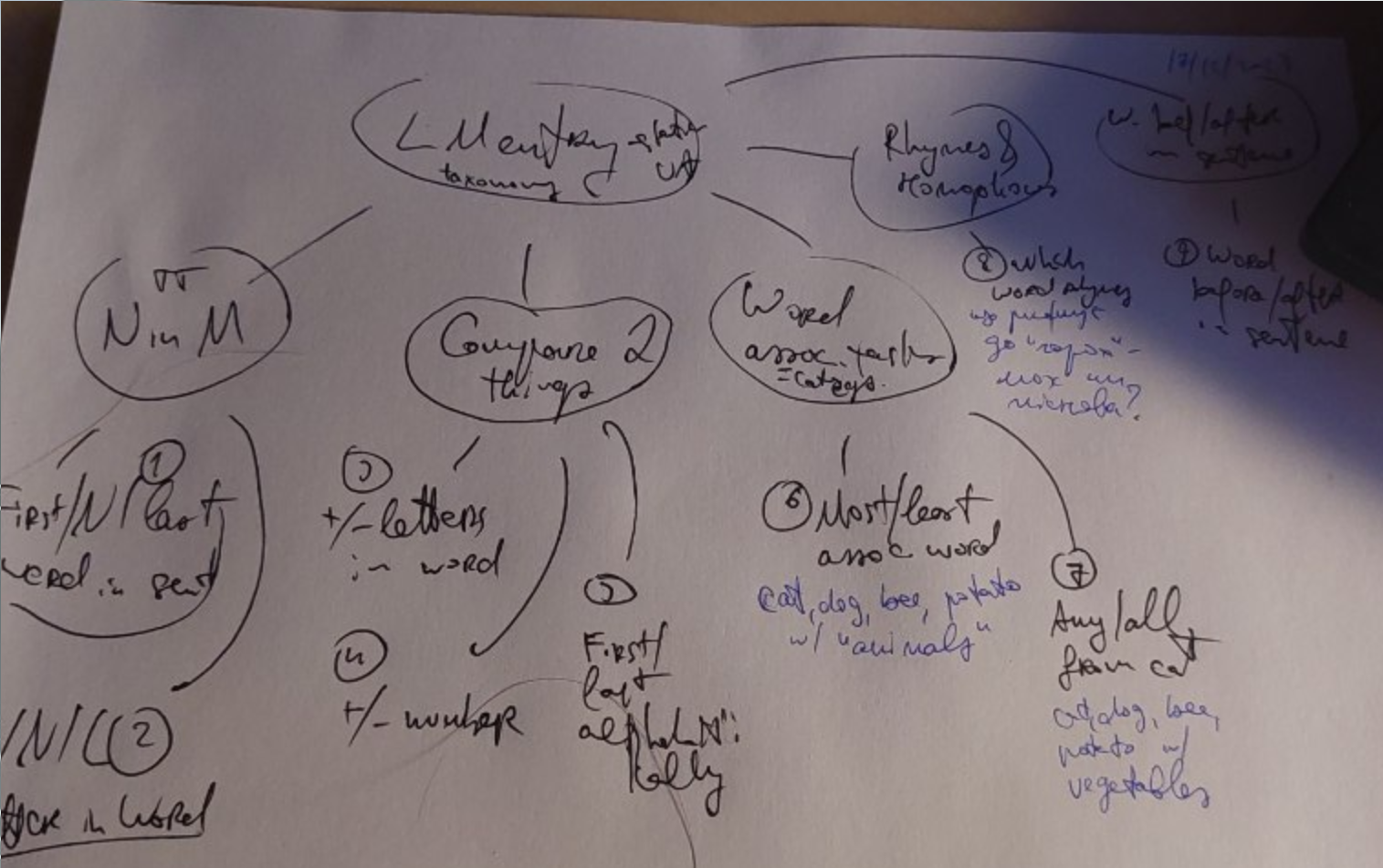 +
+
Comparing two things
Words of different lengths, alphabet order of words, etc.
Main relationship is kind=less|more, where less means “word closer to beginning of the alphabet”, “smaller number”, “word with fewer letters” etc., more is the opposite.
Alphabet order of words
- (DONE) which word is closer to beginning of alphabet
- Are these words in alphabet order?
Which word is longer
TODO Which number is bigger
- use the one-million bits and add to the text that this is why I needed to care about agreemnet
- do comparisons of entities! one box has a million pencils, the other has five hundred thousand. Which has more pencils?
GPT4 agreement issues
https://chat.openai.com/share/b52baed7-5d56-4823-af3e-75a4ea8d5b8c: 1.5 errors, but I’m not sure myself about the fourth one.
LIST = [
"Яке слово стоїть ближче до початку алфавіту: '{t1}' чи '{t2}'?",
"Що є далі в алфавіті: '{t1}' чи '{t2}'?",
"Між '{t1}' та '{t2}', яке слово розташоване ближче до кінця алфавіту?",
# TODO - в алфавіті?
"У порівнянні '{t1}' і '{t2}', яке слово знаходиться ближче до A в алфавіті?",
# ChatGPT used wrong відмінок внизу:
# "Визначте, яке з цих слів '{t1}' або '{t2}' знаходиться далі по алфавіті?",
]
HF Dataset
I want a ds with multiple configs.
Base patterns
- HA! Lmentry explicitly lists base patterns: lmentry/lmentry/scorers/first_letter_scorer.py at main · aviaefrat/lmentry
starts = "(starts|begins)"
base_patterns = [
rf"The first letter is {answer}",
rf"The first letter {of} {word} is {answer}",
rf"{answer} is the first letter {of} {word}",
rf"{word} {starts} with {answer}",
rf"The letter that {word} {starts} with is {answer}",
rf"{answer} is the starting letter {of} {word}",
rf"{word}: {answer}",
rf"First letter: {answer}",
]
For more: lmentry/lmentry/scorers/more_letters_scorer.py at main · aviaefrat/lmentry
Looking for example sentences
- spacy example sentences
- political ones from UP!
- implemented
- for words, I really should use some normal dictionary.
Assoc. words and resources
Another dictionary I found: slavkaa/ukraine_dictionary: Словник слів українською (слова, словоформи, синтаксичні данні, літературні джерела)
- Excel_word_v10.xslx
- sql as well
- a lot of columns
Next tasks
- List
- Most associated word
- Least associated word
- Any words from category
- All words from category
All basically need words and their categories. E.g. Animals: dog/cat/racoon
I wonder how many different categories I’d need
Ah, the O.G. benchmark has 5 categories: lmentry/resources/nouns-by-category.json at main · aviaefrat/lmentry
Anyway - I can find no easy dictionary about this.
options:
Wordnet
- Other Wordnet: olgakanishcheva/WordNet-Affect-UKR: WordNet-Affect (http://wndomains.fbk.eu/wnaffect.html) is an extension of WordNet Domains, including a subset of synsets suitable to represent affective concepts correlated with affective words.
- multi-lang incl. Ukr
- emotions only
- txts are tab-separated, colums are lists of words in column-language
- WordNet — someone started it for UKR!
- wordnet/resources/wn-ua-2015 at main · lang-uk/wordnet
- wordnet/assumptions.md at main · lang-uk/wordnet this is so cool!
- wordnet/notebooks/wn-translation-analysis-khrystyna.md at main · lang-uk/wordnet 10/10 would love to work on/at/with that/them
- 2015
- all-dict-entries: definitions
- all-in-one-file: relationships between these definitions
- wordnet/resources/wn-ua-2015 at main · lang-uk/wordnet
- WordNet - Wikipedia:
- hypernym: Y is a hypernym of X if every X is a (kind of) Y (canine is a hypernym of dog)
- hyponym: Y is a hyponym of X if every Y is a (kind of) X (dog is a hyponym of canine)
- holonym: Y is a holonym of X if X is a part of Y (building is a holonym of window)
- meronym: Y is a meronym of X if Y is a part of X (window is a meronym of building)
for all-in-one:
> grep -o "_\(.*\)(" all-in-one-file.txt | sort | uniq -c
49 _action(
8 _action-and-condition(
58 _holonym(
177 _hyponym(
43 _meronym(
12 _related(
51 _sister(
102 _synonym(
looking through it it’s sadly prolly too small
2009’s hyponym.txt is nice and much more easy to parse.
GPT
Ideas: WordNet Search - 3.1 Ask it to give me a list of:
- emotions
- professions
- sciences
- body parts
- animals
- times (dow, months, evening, etc.)
- sports It suggests also
- musical instruments
- dishes
- clothing
-
<_(@bm_lmentry) “LMentry: A language model benchmark of elementary language tasks” (2022) / Avia Efrat, Or Honovich, Omer Levy: z / / 10.48550/ARXIV.2211.02069 _> ↩︎
-
API Reference (auto-generated) — Морфологический анализатор pymorphy2 ↩︎