Evaluating NLG
Papers
-
[2303.16634] G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment 1
- Excellent
- Main pitch:
- “Auto CoT evaluation”: make the LLM generate a chain-of-thoughts based on provided criteria
- get the LLM evaluate texts based on that CoT as form-filling task
- weight by the probabilities of the votes as given by the LLM
1*chance-of-1+2*chance-of-2
- Compares own evaluators to multiple others
-
[2302.04166] GPTScore: Evaluate as You Desire2
- basics:
- task: e.g. summarize
- aspect: e.g. relevance
- eval protocol: how likely it is that this text was generated given this task and this aspect?
- main pitch:
- LLM-estimated likelihood of text based on task+aspect+result.
- For summary:
{Task_Specification} {Aspect_Definition} Text: {Text} Tl;dr: {Summ}
- aspects:
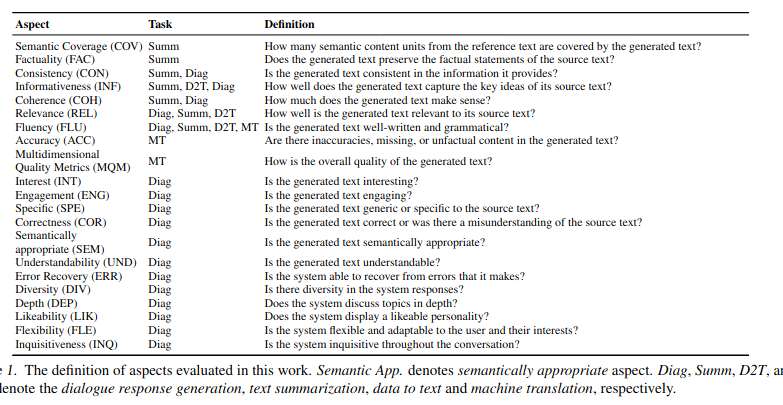
- basics:
-
UniEval [2210.07197] Towards a Unified Multi-Dimensional Evaluator for Text Generation3
- one trained evaluator to rule them all, based on boolean Q/A
- “is this a coherent summary?” -> chances for yes/no -> profit
-
LLM Comparative Assessment: Zero-shot NLG Evaluation through Pairwise Comparisons using Large Language Models4
Approaches
Main goal: coherence with human judgement
Kinds
Reference-free
- LLM-estimate the probability is a generated text
- assumption being that better texts have better probability
- downsides: unreliable / low human correspondence according to 1
- Ask an LLM how coherent / grammatical /
criterium_namethe output is from 0 to 5- downsides: LLMs will often pick
3but G-Eval works around that
- downsides: LLMs will often pick
Reference-based
- BLEU/ROUGE and friends (n-gram based)
- low correlation with human metrics
- (semantic) Similarity between two texts based on embeddings (BERTScore/MoverScore)
- GPTScore2: higher probability to texts better fitting the framing
- FACTUAL CONSISTENCY of generated summaries: FactCC, QAGS5
Framings (for GPT/LLM-based metrics)
- Form-filling (G-Eval)
- Conditional generation (=probability): GPTScore
Pairwise comparisons
- Pairwise comparisons4
How to evaluate evaluations
Meta-evaluators
- Meta-evaluators are a thing! (= datasets based on human ratings)
- Correlation with human metrics

Stats
- Many papers use various statistical bits to compare them.
- G-Eval (p. 6)
- Spearman, Kendall-Tau correlations
- Krippendorf’s Alpha
On a specific task
Task formulation
- Input:
- Advert for a car.
Car has 4 wheels
- Target profile of possible client
family with 10 kids 5 dogs living in the Australian bush
- Advert for a car.
- Output:
- Advert targeted for that profile:
ROBUST car with 4 EXTRA LARGE WHEELS made of AUSTRALIAN METAL able to hold 12 KIDS and AT LEAST 8 DOGS
- Advert targeted for that profile:
Concrete approaches
- Factual correctness / hallucinations
- Framed as summarization evaluation: FactCC, QAGS5
- GPTScore, G-Eval based on yet-to-be-determined-criteria
- Coherence, consistency, fluency, engagement, etc. — the criteria used by meta-evaluators?
- GPTScore aspects
- TODO: ask the car company what do they care about except factual correctness and grammar
- information density-ish? Use an LLM to get key-value pairs of the main info in the advert (
number_of_wheels: 4), formulate questions based on each, and score better the adverts that contain answers to more questions!- Inspired by QAGS
TODO
- LLM-as-a-judge and comparative assestment
- think about human eval + meta-eval
- think about what we want from the car company
- metrics they care about
-
G-Eval: <_(@liuGEvalNLGEvaluation2023) “G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment” (2023) / Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, Chenguang Zhu: z / http://arxiv.org/abs/2303.16634 / 10.48550/arXiv.2303.16634 _> ↩︎ ↩︎ ↩︎ ↩︎
-
<_(@fuGPTScoreEvaluateYou2023) “GPTScore: Evaluate as You Desire” (2023) / Jinlan Fu, See-Kiong Ng, Zhengbao Jiang, Pengfei Liu: z / http://arxiv.org/abs/2302.04166 /
10.48550/arXiv.2302.04166_> ↩︎ ↩︎ -
<_(@zhongUnifiedMultiDimensionalEvaluator2022) “Towards a Unified Multi-Dimensional Evaluator for Text Generation” (2022) / Ming Zhong, Yang Liu, Da Yin, Yuning Mao, Yizhu Jiao, Pengfei Liu, Chenguang Zhu, Heng Ji, Jiawei Han: z / http://arxiv.org/abs/2210.07197 /
10.48550/arXiv.2210.07197_> ↩︎ -
<_(@liusieLLMComparativeAssessment2024) “LLM Comparative Assessment: Zero-shot NLG Evaluation through Pairwise Comparisons using Large Language Models” (2024) / Adian Liusie, Potsawee Manakul, Mark J. F. Gales: z / http://arxiv.org/abs/2307.07889 /
10.48550/arXiv.2307.07889_> ↩︎ ↩︎ -
<_(@wangAskingAnsweringQuestions2020) “Asking and Answering Questions to Evaluate the Factual Consistency of Summaries” (2020) / Alex Wang, Kyunghyun Cho, Mike Lewis: z / http://arxiv.org/abs/2004.04228 / 10.48550/arXiv.2004.04228 _> ↩︎ ↩︎ ↩︎
-
<_(@fabbriSummEvalReevaluatingSummarization2021) “SummEval: Re-evaluating Summarization Evaluation” (2021) / Alexander R. Fabbri, Wojciech Kryściński, Bryan McCann, Caiming Xiong, Richard Socher, Dragomir Radev: z / https://direct.mit.edu/tacl/article/doi/10.1162/tacl_a_00373/100686/SummEval-Re-evaluating-Summarization-Evaluation / 10.1162/tacl_a_00373 _> ↩︎
-
<_(@gopalakrishnanTopicalChatKnowledgeGroundedOpenDomain2023) “Topical-Chat: Towards Knowledge-Grounded Open-Domain Conversations” (2023) / Karthik Gopalakrishnan, Behnam Hedayatnia, Qinlang Chen, Anna Gottardi, Sanjeev Kwatra, Anu Venkatesh, Raefer Gabriel, Dilek Hakkani-Tur: z / http://arxiv.org/abs/2308.11995 / 10.48550/arXiv.2308.11995 _> ↩︎