Evaluating RAG
General info
- Roughly, it’s evaluating
- context — how relevant/correct are the retrieved chunks
- answer — how good are the generated claims
- (with interplay inbetween — e.g. whether the answer comes from the context, regardless of whether both are relevant to the query)
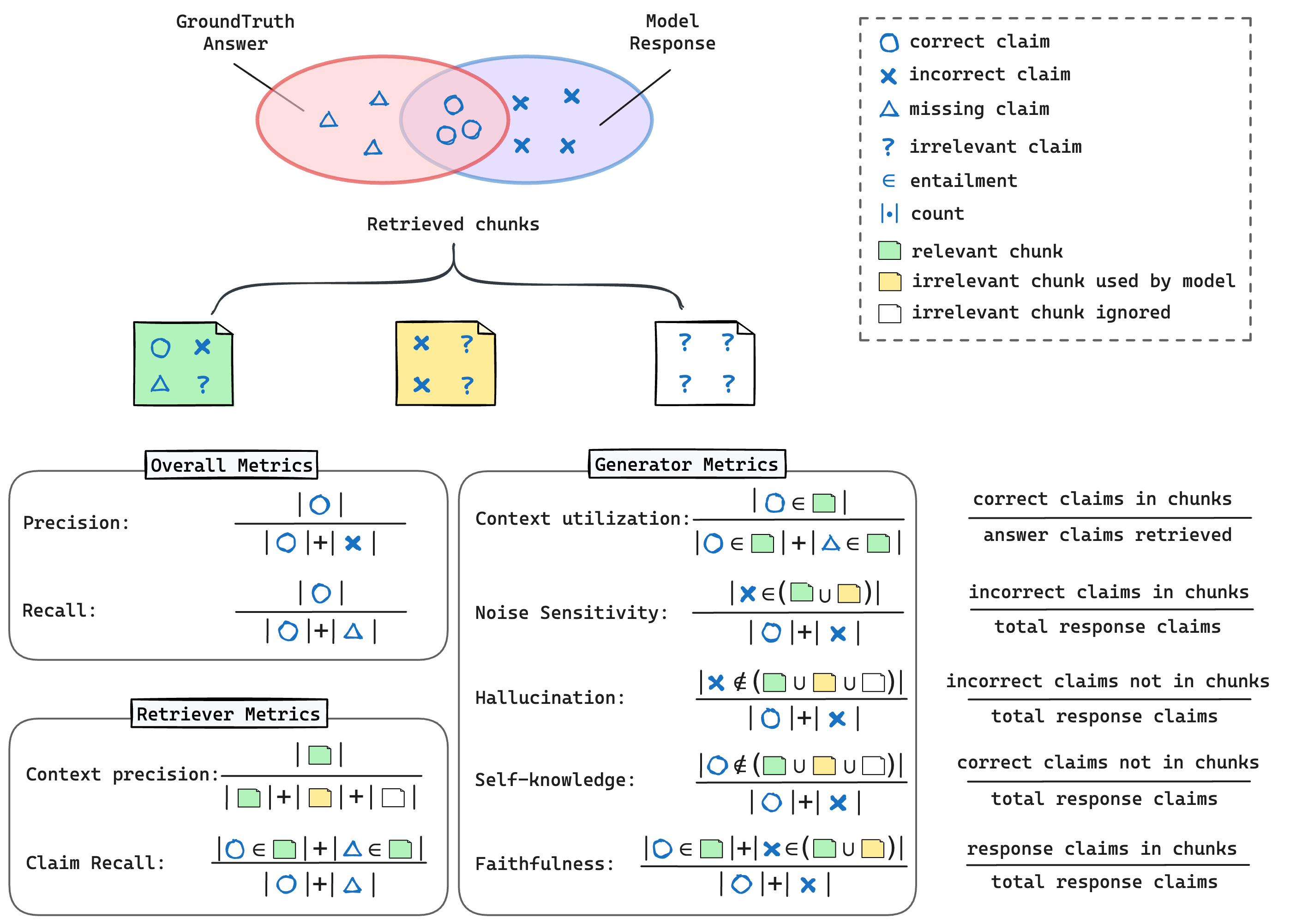
- Or: generator metrics, retriever metrics, and overall metrics as used in RAGChecker (see RAGChecker picture later below).
Sources / libs
-
- Especially Usage Pattern (Response Evaluation) - LlamaIndex
- Faithfullness: context(=source)+answer => whether the answer comes from the context available (=whether the answer was hallucinated)
- Relevancy: query+context+answer => whether the answer AND CONTEXT were relevant for the specific query
- All LlamaIndex’s eval modules: Modules - LlamaIndex
- CorrectnessEvaluator: compare query+answer to a reference answer: Correctness Evaluator - LlamaIndex w/ another LLM
- Embedding Similarity Evaluator - LlamaIndex response+reference semantic similarity via embeddings
- Especially Usage Pattern (Response Evaluation) - LlamaIndex
-
Deepeval’s metrics as given in the llamaindex docs:
from deepeval.integrations.llama_index import ( DeepEvalAnswerRelevancyEvaluator, DeepEvalFaithfulnessEvaluator, DeepEvalContextualRelevancyEvaluator, DeepEvalSummarizationEvaluator, DeepEvalBiasEvaluator, DeepEvalToxicityEvaluator, )
RAGChecker
- RAGChecker: RAGChecker: A Fine-grained Framework For Diagnosing RAG
- LlamaIndex integration docs: RAGChecker: A Fine-grained Evaluation Framework For Diagnosing RAG - LlamaIndex
Nel mezzo del deserto posso dire tutto quello che voglio.
comments powered by Disqus