Unsymbols ml generation notes
The plan
- I get the idea that Stable Diffusion is better than GAN, less fuss and memorization
Ideas
-
ChatGPT says:
Add a style token (font) and content token (Unicode code point). During sampling, drop the content token → the model synthesises “glyph-like” shapes no Unicode ever had.
Condition-free sampling. To get shapes outside Unicode, drop or randomise the content token (for FontDiffuser) or sample a latent without the class embedding (for DeepSVG/GlyphGAN). This produces “glyph-like” forms that aren’t tied to any code point.
if class was one-hot, pass either 00000 or a random soft vector
-
We can get a GAN model encoded on e.g. latin and then fine-tune it on the rest, instead of doing it from scratch
Tentative plan
- Generate chars
- Generate unseen chars
- Filter
Generate chars
- FontDiffuser
- try running existing checkpoint
- play w/ sampling script to make it no-sampling
- DeepSVG
- they explicitly do font generation at the end, training with a letter class on a vector fonts dataset. So:
- Get weights
- Play with latent operations: deepsvg/notebooks/latent_ops.ipynb at master · alexandre01/deepsvg
- Try to reproduce their fonts thingy
- try to generate unseen glyphs from their fonts weights
- train on my own fonts dataset
- Run GlyphGAN on correctly-sized pictures as notebook, on GPU, see if it stabilizes
- Run an existing checkpoint — GAN w/ correct size, style diffusion — to get existing chars
- Try condition-free sampling
Filter chars
- todo
Play with more creative char generation
Resources
Font generation
-
[1905.12502] GlyphGAN: Style-Consistent Font Generation Based on Generative Adversarial Networks
- in: character class+style, out -> character in style
- looks light on resources
- single jupyter notebook actually, wow.
- needs directory with pics, notebook easy to run
- ChatGPT says GANs don’t like resizing, diffusion does.
-
- stable diffusion
- in: char (utf8 or image)+other char in this style, out -> character in style
- ‘generalizes for unseen chars and styles’, ’excels at complex characters’
- Can I provide no seed character? Their sample script is promising: FontDiffuser/sample.py
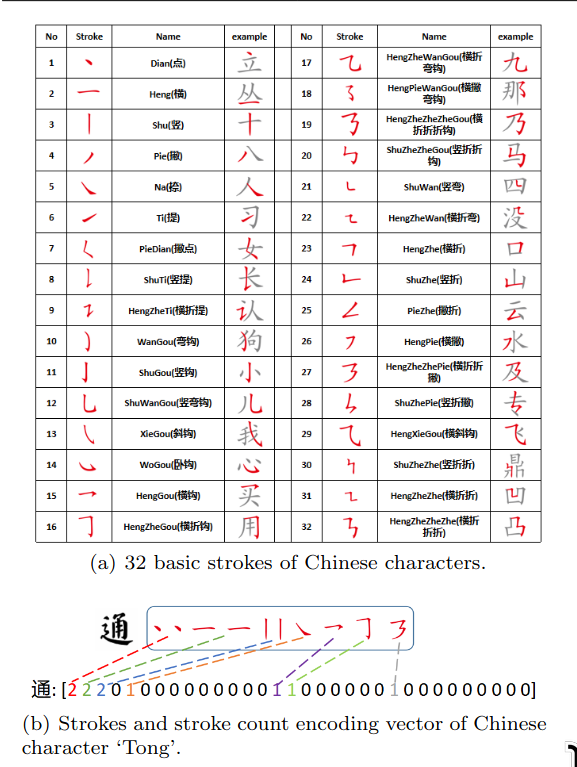
- Input is info about a character, that is content, strokes, style etc.
-
-
[2212.05895] Diff-Font: Diffusion Model for Robust One-Shot Font Generation
- STROKE-BASED I think -> generates more logical characters?..
- they have a stroke-based chinese dataset which they use
- diffusion, pretrained model available
- Official code implementation: Hxyz-123/Font-diff
- STROKE-BASED I think -> generates more logical characters?..
-
[2312.10540] VecFusion: Vector Font Generation with Diffusion
- another REALLY cool vector thingy, png->vector
- represents vectors differently than deepSVG or what was the name
-

Handwriting
Generation
- [2306.10804] Conditional Text Image Generation with Diffusion Models generates handwritten text
-
- Diff-font above
- Generally: China/Japan are the places to look, their calligraphy is heavily stroke-based and they need this more than most

Movements
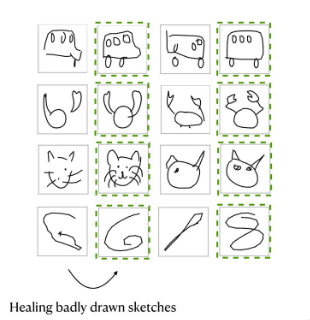
- ChiroDiff: Modelling chirographic data with Diffusion Models – Ayan Das
- model strokes etc!!!
- “healing badly drawn sketches”:
Misc
Datasets
- Font Book a lot of variations for English chars, used in glyphgan, 2700 chars