Day 787
Python multiprocessing/threading basics
From Multiprocessing vs. Threading in Python: What Every Data Scientist Needs to Know
Terminology:
-
Processes: instances of a program being executed; don’t share memory space
- Slower to create, take a bit more memory and stuff
-
Threads: components of a process that run in parallel; share memory, variables, code etc.
- Faster to create, less overhead
- Much easier to share objects between them
-
Race Condition: “A race condition occurs when multiple threads try to change the same variable simultaneously.” (Basically - when order of execution matters)
-
Starvation: “Starvation occurs when a thread is denied access to a particular resource for longer periods of time, and as a result, the overall program slows down.”
-
Deadlock: A deadlock is a state when a thread is waiting for another thread to release a lock, but that other thread needs a resource to finish that the first thread is holding onto.
-
Livelock : Livelock is when threads keep running in a loop but don’t make any progress.
Python / GIL
In CPython, the Global Interpreter Lock (GIL) is a (mutex) mechanism to make sure that two threads don’t write in the same memory space.
Basically “for any thread to perform any function, it must acquire a global lock. Only a single thread can acquire that lock at a time, which means the interpreter ultimately runs the instructions serially.” Therefore, python multithreading cannot make use of multiple CPUs; multithreading doesn’t help for CPU-intensive tasks, but does for places where the bottleneck is elsewhere - user interaction, networking, etc. Multithreading works for places w/o user interaction and other bottlenecks where the tasks are CPU-bound, like doing stuff with numbers.
Tensorflow uses threading for parallel data transformation; pytorch uses multiprocessing to do that in the CPU.
TODO - why does Tensorflow do that?
Python libraries
Python has two libraries, multithreading and multiprocessing, with very similar syntax.
Comparing execution time
Both pictures from the same article above1:
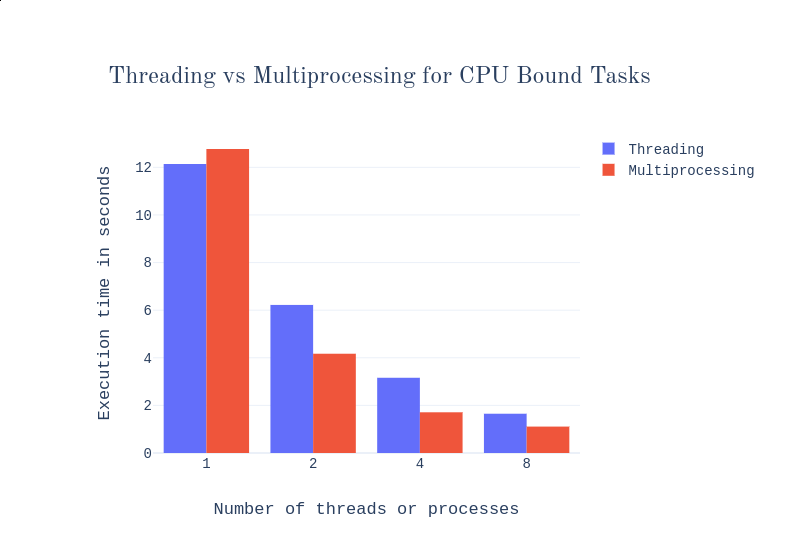
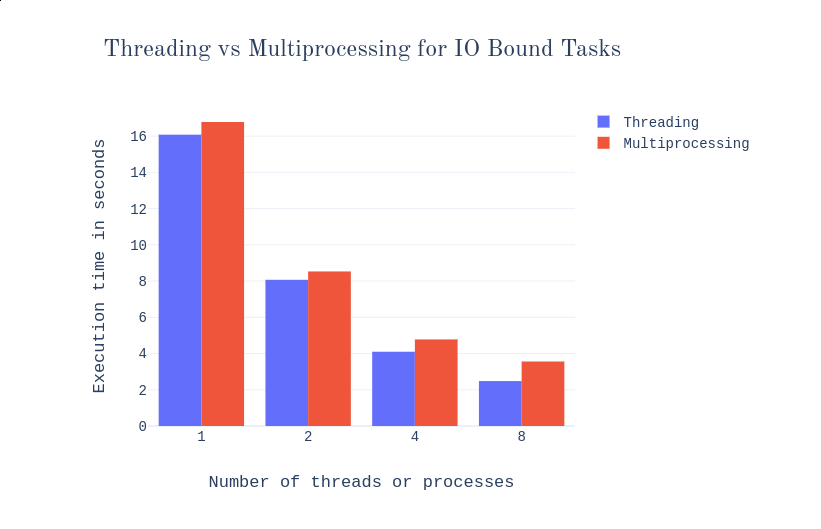
- One process is slower than one thread always; for more than one, processes win for CPU-only tasks, threads for bottlenecked tasks.
- More processes than cores doesn’t improve life by much in any case (still better than the same amount of threads though); in the picture, there are four cores.
Python-specific points
- Easier to make errors in multithreading programs (easier to share data, but you have to keep in mind object synchronisation and race conditions).
- Threads can’t do true parallelism in Python due to GIL
- The OS schedules processes, Python schedules threads
- “Child processes are interruptible and killable, whereas child threads are not. You have to wait for the threads to terminate or join.”
For data science
- Reading data from disk is I/O bound => multithreading
- Calculating stuff on CPU/GPU is CPU bound => multiprocessing
- Storing results => multithreading
Concurrency / parallelism / Python
From Python Multi-Threading vs Multi-Processing | by Furqan Butt | Towards Data Science:
Concurrency is essentially defined as handling a lot of work or different units of work of the same program at the same time.
Doing a lot of work of the same program at the same time to speed up the execution time.
Parallelism has a narrower meaning.
Python - concurrent.futures for multithreading and multiprocessing
Multithreading:
import concurrent.futures
with concurrent.futures.ThreadPoolExecutor() as executor:
executor.map(function_name, iterable)
This would create a thread for each element in iterable.
Multiprocessing works in an extremely similar way:
import concurrent.futures
with concurrent.futures.ProcessPoolExecutor() as executor:
executor.map(function_name, iterable)
More about it, as usual, in the docs:
The asynchronous execution can be performed with threads, using ThreadPoolExecutor, or separate processes, using ProcessPoolExecutor. Both implement the same interface, which is defined by the abstract Executor class. 2
Questions
Does concurrent.futures have any tradeoffs compared to doing multiprocessing.Pool() like the following?
pool = multiprocessing.Pool()
pool.map(multiprocessing_func, range(1,10))
pool.close()
Measuring and reading time
Python parallelism example
Parallelising Python with Threading and Multiprocessing | QuantStart has a nice point:
time python thread_test.py
real 0m2.003s
user 0m1.838s
sys 0m0.161s
Both user and sys approximately sum to the real time. => No parallelization (in the general case). After they use multiprocessing, two processes, real time drops by two, while user/sys time stays the same. So time on CPU per second is the same, but we have two CPUs that we use, and we get real time benefits.
Reading and interpreting time output:
Excellent article, copying directly: Where’s your bottleneck? CPU time vs wallclock time
real: the wall clock time.
user: the process CPU time.
sys: the operating system CPU time due to system calls from the process.
In this case the wall clock time was higher than the CPU time, so that suggests the process spent a bunch of time waiting (58ms or so), rather than doing computation the whole time. What was it waiting for? Probably it was waiting for a network response from the DNS server at my ISP.
Important: If you have lots of processes running on the machine, those other processes will use some CPU.
Reading CPU time ratios
Directly copypasting from the article above, “CPU” here is “CPU Time” (so user in the output of the command), second is “real” (=wall; real-world) time.
If this is a single-threaded process:
- CPU/second ≈ 1: The process spent all of its time using the CPU. A faster CPU will likely make the program run faster.
- CPU/second < 1: The lower the number, the more of its time the process spent waiting (for the network, or the harddrive, or locks, or other processes to release the CPU, or just sleeping). E.g. if CPU/second is 0.75, 25% of the time was spent waiting.
If this is a multi-threaded process and your computer has N CPUs and at least N threads, CPU/second can be as high as N.
- CPU/second < 1: The process spent much of its time waiting.
- CPU/second ≈ N: The process saturated all of the CPUs.
- Other values: The process used some combination of waiting and CPU, and which is the bottleneck can be harder to tell with just this measurement.
A bit more about cpu time
- The user-cpu time and system-cpu time [..] are the amount of time spent in user code and the amount of time spent in kernel code. 3
- multi-core machines and multi-threaded programs can use more than 1 CPU second per elapsed second 3
Python-specific thread programming:
- Examples of race-conditions and using locking: Multithreading in Python | Set 2 (Synchronization) - GeeksforGeeks
- TL;DR:
def thread_task(lock):
"""
task for thread
calls increment function 100000 times.
"""
for _ in range(100000):
lock.acquire()
increment()
lock.release()
- Examples of sharing data in multiprocessing (didn’t read, TODO): Multiprocessing in Python | Set 2 (Communication between processes) - GeeksforGeeks
- As usual, details (including sharing state etc):