serhii.net
In the middle of the desert you can say anything you want
-
Day 1740 (06 Oct 2023)
Pandas aggregation with multiple columns and/or functions
One way to do it, if it’s all for all:
df.groupby("collection")[ ["num_pages", "num_chars", "num_tokens", "num_sentences"] ].agg( [ # "count", "sum", "mean", # "std", ] )An even better way:
# ... ].agg( num_documents=("num_pages", "count"), num_pages=("num_pages", "sum"), mean_pages=("num_pages", "mean"), mean_tokens=("num_tokens", "mean"), )They are literally named tuples! Yay for Named Aggregation1!
-
Day 1739 (05 Oct 2023)
Matplotlib extend limits to fit text
Draft.
Context: 230529-2208 Seaborn matplotlib labeling data points
Given: need to make the limits larger to fit text, the last lines here:
data = df_pages.reset_index().sort_values('num_pages') ax = sns.barplot(data,y="collection",x="num_pages") # label points for i in ax.axes.containers: ax.bar_label( i, ) # make the labels fit the limits xlim = ax.axes.get_xlim()[1] new_xlim = xlim + 14600 ax.axes.set_xlim(0, new_xlim)Question: by how much?
Answer:
- Transformations Tutorial — Matplotlib 3.8.0 documentation for converting text-pixels to data-limit
- ??? to get the text dimensions
for i in ax.axes.containers: an = ax.bar_label( i, ) # `an` is a list of all Annotationsan[0].get_window_extent() >>> Bbox([[88.66956472198585, 388.99999999999994], [123.66956472198585, 402.99999999999994]]) def get_text_size(anno): # Annotation """ TODO: get array of annos, find the leftmost one etc.""" bbox = anno.get_window_extent() ext = bbox.bounds # > (91.43835300441604, 336.19999999999993, 35.0, 14.0) x=ext[2] y=ext[3] return x,y """ ano = an[1] bbox = ano.get_window_extent() bbox.bounds > (91.43835300441604, 336.19999999999993, 35.0, 14.0) """ get_text_size(an[6])
Removing Gitlab tasks from issues thorugh search filter
Gitlab introduced tasks, and they get shown by default in the issue list.
Type != taskin the search leaves only the issues.Can one save search templates?..
-
Day 1737 (03 Oct 2023)
~~My own evaluation harness for Masterarbeit notes~~ eval harnesses notes
Is this needed or I can just use one of the existing ones?I’ll use one of the existing ones!Then this is about notes about choosing one and adapting my own tasks for it.
First of all, I’d like the generator things to be runnable through Docker, especially the pravda crawler!
Related:
- 230928-1735 Other LM Benchmarks notes has examples
- I have to support prompts, e.g. see what other papers1 do, as well as the harnesses
General:
- I don’t have to forget that the OpenAI API exists!
- And I can use it for evaluation too!
Other / useful libraries:
- 230928-1735 Other LM Benchmarks notes has a list of harnesses, todo move here.
- bigscience-workshop/lm-evaluation-harness: A framework for few-shot evaluation of autoregressive language models.
- TheoremOne/llm-benchmarker-suite: LLM Evals Leaderboard
Main idea
- Following established practice, dataset on HF hub and some magic code to convert it into actual LM inputs.
- Have a versioning system (both for individual tasks and the benchmark in general?)
Architecture
Tasks
- A task has a metadata file, and the task data.
- task metadata
- VERSION!
- Can contain a task description for the model as prompt
- Can contain the format-strings etc. for building examples
- The task data
- can be either a
- .json
- a HF dataset string
- contains:
- All the data needed to build test cases for each example
- can be either a
Task types
-
exact match: true/false
-
multiple choice
- incl. binary yes/no
-
lmentry/lmentry/predict.py at main · aviaefrat/lmentry contains the predicting code used to evaluate it using different kinds of models - I’ll need this.
Links
- HF evaluation library
- lmentry
- UA models: Models - Hugging Face
- I should look into QA models as well!
SWAG seems the closest out of the modern models to UA-CBT — one-word completions etc. I should look into what exactly they do
NarrativeQA!
-
Day 1736 (02 Oct 2023)
Masterarbeit toread stack
Also: 231002-2311 Meta about writing a Masterarbeit
Relevant papers in Zotero will have a ’toread’ tag.
When can we trust model evaluations? — LessWrong
-
How truthful is GPT-3? A benchmark for language models — LessWrong
- paper: [2109.07958] TruthfulQA: Measuring How Models Mimic Human Falsehoods
- especially the bits about constructing and validating!
- sylinrl/TruthfulQA: TruthfulQA: Measuring How Models Imitate Human Falsehoods
- paper: [2109.07958] TruthfulQA: Measuring How Models Mimic Human Falsehoods
-
Code:
- spacy:
- the entire site: Finding linguistic patterns using spaCy
- spacy:
-
lists: AI Evaluations - LessWrong
-
Datasets - The Best Ukrainian Language Datasets of 2022 | Twine some aren’t ones I addedj
-
Victoria Amelina: Ukraine and the meaning of home | Ukraine | The Guardian
-
Ukrainian and Russian: Two Separate Languages and Peoples – Ukrainian Institute of America
-
Bender and friensd:
- Unsupervised Cross-lingual Representation Learning & Unsupervised Cross-lingual Learning - Google Slides
- The cool state and fate paper1 , especially the last bits about language typology.
-
Eval
Python stuff
“Питон для продвинутой группы лингвистов, 2020-2021” (lecture): klyshinsky/AdvancedPyhon_2020_21
I should read through everything here: A quick tour
- HF, LLM etc. Hamel’s Blog - Dataset Basics
-
<_(@inclusion) “The state and fate of linguistic diversity and inclusion in the NLP world” (2020) / Pratik Joshi, Sebastin Santy, Amar Budhiraja, Kalika Bali, Monojit Choudhury: z / https://arxiv.org/abs/2004.09095 / _> ↩︎
Meta about writing a Masterarbeit
Literature review
LessWrong
-
Literature Review For Academic Outsiders: What, How, and Why — LessWrong
-
‘Literature review’ the process is a way to become familiar with what work has already been done in a particular field or subject by searching for and studying previous work
-
Every time I do research I perform a simple thought experiment: assuming somewhere in the world exists evidence that would prove or disprove my hypothesis, where is it?
-
Citations are a hierarchy of ideas
Style etc.
My old note about tenses in a bachelor thesis: Day 155 - serhii.net linking to the excellent Effective Writing | Learn Science at Scitable
- My notes at 231201-1401 How to read and write a paper according to hackernews. Main takeaway for me is to keep in mind my target audience, what they know and what they don’t, when writing.
Grammar glossing
Leipzig glossing rules
Leipzig Glossing rules seems to be the key for me:
-
Markdown and python and stuff
-
Markdown
- cysouw/pandoc-ling: Pandoc Lua filter for linguistic examples
- gunnarnl/pangb4e: Pandoc filter for gb4e support
- parryc/doctor_leipzig: Leipzig, MD - glossing for Markdown
- one can always do
<span style="font-variant:small-caps;">Hello World</span>1
-
Python
Useful literature for Masterarbeit
Linguistics basics
- Random book I found: Essentials of Linguistics, 2nd edition – Simple Book Publishing
- Also
- (172) What are some books I can read if I want to get into studying linguistics casually? : linguistics
- Steven Pinker’s “The Language Instinct” - allegedly really cool but not for my purposes
- (172) What are some books I can read if I want to get into studying linguistics casually? : linguistics
Essentials of Linguistics, 2nd edition
The online version1 has cool tests at the end!
Generally: a lot of it is about languages/power, indigenous languages etc. Might be interesting for me wrt. UA/RU and colonialism
- Chapter 5 / Morphology gets interesting
- 5.7 Inflectional morphology!
- 6: Syntax - even more interesting
- 6.2 word order
- p.264 Key grammatical terminology
- word order
- really cool and quite technical up until the end, esp. trees
-
- Semantics
-
- Pragmatics
- todo - all of it
Python self type
https://peps.python.org/pep-0673/
from typing import Self class Shape: def set_scale(self, scale: float) -> Self: self.scale = scale return selfRelated: 220726-1638 Python typing classmethods return type
I remember writing about the typevar approach but cannot find it…
-
-
Day 1732 (28 Sep 2023)
Random side quests about the Masterarbeit
UA-RU parallel corpus
pravda.com.ua1 має статті трьома мовами:
- Залужний востаннє поговорив з Міллі на його посаді | Українська правда
- Залужный в последний раз поговорил с Милли в его должности | Украинская правда
- Commander-in-Chief of Ukrainian Armed Forces speaks with Milley for last time before latter steps down | Ukrainska Pravda
The difference seems to be only in that one part of the URL!
Article; title; tags; date,author.
Then article title+classification might be one of the benchmark tasks!
Is there anything stopping me from scraping the hell out of all of it?
Google finds 50k articles in
/eng/, 483k in/rus/, assumption: all english articles were translated to Russian as well.=> For each english article, try to get the Russian and Ukrainian one from the URI.
-
©2000-2023, Українська правда. Використання матеріалів сайту лише за умови посилання (для інтернет-видань - гіперпосилання) на “Українську правду” не нижче третього абзацу.
- Правила використання матеріалів сайтів Інтернет-холдингу ‘‘Українська правда’’ (Оновлено) | Українська правда
Related: ua-datasets/ua_datasets/src/text_classification at main · fido-ai/ua-datasets Related: facebook/flores · Datasets at Hugging Face frow wikinews in infinite languages including UA!
Somehow magically use WikiData
- Douglas Adams - Reasonator
- KGQA/QALD_9_plus: QALD-9-Plus Dataset for Knowledge Graph Question Answering
How does alignment/censoring work with UA?
eg could other langs help for that?2
-
Same goes for Економічна правда and friends. ↩︎
-
(172) Detailed walkthrough of procedure to uncensor models : LocalLLaMA.g. ↩︎
Very first notes on my Master thesis - Evaluation benchmark for DE-UA text
Officially - I’m doing this!
This post will be about dumping ideas and stuff.
Related posts for my first paper on this topic:
- 221120-1419 Benchmark tasks for evaluation of language models
- 221205-0009 Metrics for LM evaluation like perplexity, BPC, BPB
- 221119-2306 LM paper garden My first paper on the topic:
Procedural:
- I’ll be using Zotero
- I’ll be writing it in Markdown
- TODO: Zotero+markdown+obsidian?..
General questions:
Write my own code or use any of the other cool benchmark frameworks that exist?If I’ll write the code: in which way will it be better than, e.g., eleuther-ai’s lm-evaluation-harness?- I will be using an existing harness
- Task types/formats support - a la card types in Anki - how will I make it
- extensible (code-wise)
- easy to provide tasks as examples? YAML or what?
Do I do German or Ukrainian first? OK to do both in the same Master-arbeit?- I do Ukrainian first
- Using existing literature/websites/scrapes (=contamination) VS making up my own examples?
- Both OK
Actual questions
- What’s the meaningful difference between a benchmark and a set of datastes? A leaderboard? Getting-them-together?..
- Number of sentences/task-tasks I’d have to create to create a unique valid usable benchmark task?
- 1000+ for it to be meaningful
Is it alright if I follow my own interests and create more hard/interesting tasks as opposed to using standard e.g. NER etc. datasets as benchmarks?- OK to translate existing tasks, OK to copy the idea of the task - both with citations ofc
My goal
- Build an Ukrainian benchmark (=set of tasks)
- Of which at least a couple are my own
- The datasets uploaded to HF
- Optionally added/accepted to BIG-bench etc.
- Optional experiments:
- Compare whether google translating benchmarks is better/worse than getting a human to do it?
- Evaluate the correctness of Ukrainian language VS Russian-language interference!
- Really optionasl experiments
- Something about UA-specific bits, e.g. does it answer better about Ukrainian Aberglauben in UA or in EN?
- since chatGPT fails so hard at Ukrainian grammar(https://chat.openai.com/share/426c0d1c-10d0-41d4-b287-cc52a7790c4f) see if I can quantify that, and use an example of why morphologically complex langs are hard
Decisions
- Will write in English
- I’ll upload the tasks’ datasets to HF hub, since all the cool people are doing it
- Will be on Github and open to contributions/extensions
If I end up writing code do it as general as possible, so that both it’ll be trivial to adapt to DE when needed AND to other eval harnesses- EDIT 2023-10-10:
- I will be using an existing evaluation harness
Resources
-
Github
- asivokon/awesome-ukrainian-nlp: Curated list of Ukrainian natural language processing (NLP) resources (corpora, pretrained models, libriaries, etc.)
- see their links to other resources!
- Helsinki-NLP/UkrainianLT: A collection of links to Ukrainian language tools
- UA grammatical error correction competition! Damn! CodaLab - Competition
- see their links to other resources!
- Ukrainian nlp projects on github, as well as
#nlp #benchmarks Repository search results - ukrainian-language · GitHub Topics
- asivokon/awesome-ukrainian-nlp: Curated list of Ukrainian natural language processing (NLP) resources (corpora, pretrained models, libriaries, etc.)
-
- The UNLP 2023 Shared Task on Grammatical Error Correction for Ukrainian - ACL Anthology really cool paper with cool links/citations.
-
Cool model with links to datasets etc.! robinhad/kruk: Ukrainian instruction-tuned language models and datasets
-
Datasets UA, almost exclusively
- Lists
- A lot of them here: ukrainian-language · GitHub Topics
- zeusfsx/ukrainian-stackexchange · Datasets at Hugging Face
- hard to read but: Hugging Face – The AI community building the future. - starting from page 2-3-4 the non-multilingual ones start
- grammarly/ua-gec: UA-GEC: Grammatical Error Correction and Fluency Corpus for the Ukrainian Language!
- LARGE news with titles and uris: zeusfsx/ukrainian-news · Datasets at Hugging Face
- Machine Learning Datasets | Papers With Code
- Multiple choice comprehension, multilang: Belebele Dataset | Papers With Code
- FactCompletion
- reviews from rozetka/tripadv/.. vkovenko/cross_domain_uk_reviews · Datasets at Hugging Face
- 300k IS-A relations, some quite funny: lang-uk/hypernymy_pairs · Datasets at Hugging Face
- Lists
-
Benchmarks UA
- Contextual Embeddings for Ukrainian: A Large Language Model Approach to Word Sense Disambiguation - ACL Anthology
- fido-ai/ua-datasets: A collection of datasets for Ukrainian language
-
ua_datasets is a collection of Ukrainian language datasets. Our aim is to build a benchmark for research related to natural language processing in Ukrainian.
- Cool example of API usage: ua-datasets/ua_datasets/src/question_answering at main · fido-ai/ua-datasets
-
-
UA grammar/resources/…
- Linguistic Resources for the Ukrainian language on-line - Universität Regensburg
- лабораторія української
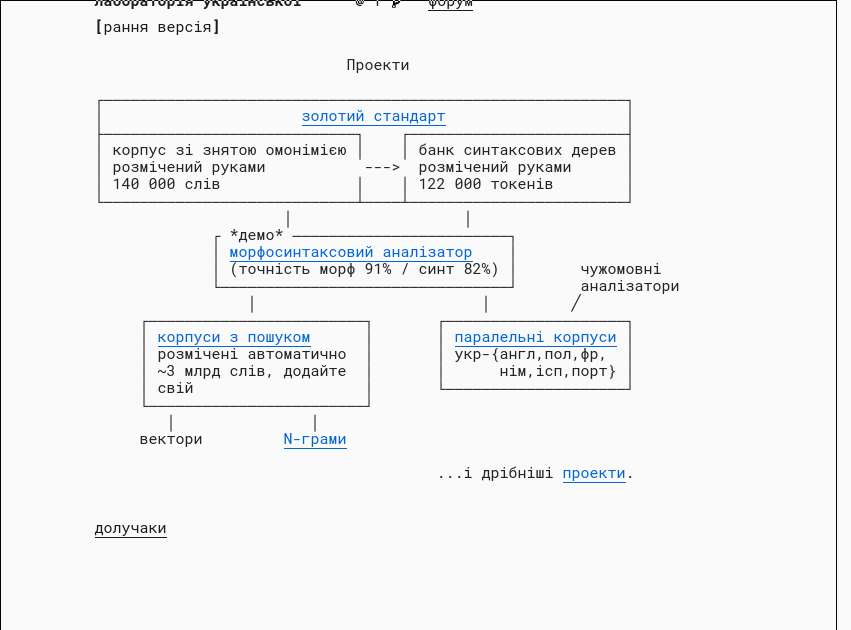
- I need to know more theory to understand but feels EXTREMELY useful
- has an API:
> curl -F json=false -F data='привіт мене звати Сірьожа' -F tokenizer= -F tagger= -F parser= https://api.mova.institute/udpipe/process
- лабораторія української
- Генеральний регіонально анотований корпус української мови (ГРАК): ГРАК - site.name
- Українська морфеміка — Вікіпедія
- Corpora UA
- brown-uk/corpus: Браунський корпус української мови
- золотий стандарт / UniversalDependencies/UD_Ukrainian-IU at dev
- Інші корпуси української мови та слов’янських мов - site.name, with info about whether it can be downloaded
- saganoren/ukr-twi-corpus: A corpus of Ukrainian Twitter texts + instructions for downloading and filtering texts.
- Linguistic Resources for the Ukrainian language on-line - Universität Regensburg
-
General evaluation bits:
-
Random UA:
- GRAC, can’t download but can use it for research
Benchmarks - generic
- Here:230928-1735 Other LM Benchmarks notes
- “literature”:
- Criterias of established benchmarks: BIG-bench/docs/doc.md at main · google/BIG-bench
- Related work of <
@ruisLargeLanguageModels2022(2022) z/d/>
Cool places with potential
- Ask Про сайт | Горох — українські словники if they can make dumps available, I could do something like “find the closest synonym to this word” etc.
- OH NICE: Home · LinguisticAndInformationSystems/mphdict Wiki
- These seem to be the DBs of the dictionaries: mphdict/src/data at master · LinguisticAndInformationSystems/mphdict
- OH NICE: Home · LinguisticAndInformationSystems/mphdict Wiki
- Cited in WSD task3:
- Open data places:
Plan, more or less
- Methodically look through and understand existing benchmarks and tasks
- Kinds of tasks
- How is the code for them actually written, wrt API and extensibility
- Do this for English, russian, Ukrainian
- At the same time:
- Start creating small interesting tasks 230928-1630 Ideas for Ukrainian LM eval tasks
- Start writing the needed code
- Write the actual Masterarbeit along the way, while it’s still easy
Changelog
- 2023-10-03 00:22: EvalUAtion is a really cool name! Ungoogleable though
-
Reproducing ARC Evals’ recent report on language model agents — LessWrong ↩︎
-
<
@labaContextualEmbeddingsUkrainian2023Contextual Embeddings for Ukrainian (2023) z/d/> / Contextual Embeddings for Ukrainian: A Large Language Model Approach to Word Sense Disambiguation - ACL Anthology ↩︎