In the middle of the desert you can say anything you want
29Nov 2021
Attempting to parse Obsidian tags with Templater templates
Obsidian
After more than a month of use, I’m still totally completely absolutely in love with Obsidian.
The standard scenario for any new technology I get excited about is something like
Discover something really cool
Read the entire Internet about it
Try to use it to solve all my problems, to see what sticks
After a week or so, either I stop using it completely, or I keep using it for a narrow use-case. I consider the latter a success.
I think this is the first time the opposite happened: I started to play with Obsidian as a way to quickly sync notes between my computer and phone (better than one-person Telegram groups or Nextcloud or Joplin or…), then started using it to write the Diensttagebuch, then realized I can drag-n-drop pictures/PDFs into it and can use it to keep my vaccination certificate and other stuff I need often on my phone, then oh nice it’s also a markdown editor, and we’re not done yet.
I’d usually avoid closed-source solutions, but it has everything I could ask for except that:
a really active community, with blog posts being written, repositories, plugins etc being constantly developed by very different people
notes being stored markdown, which then can be version-controlled and edited using any of my existing tools
this is much better than being able to “export” them to markdown, one less step to do (or forget, or easily disable). Fits seamlessly into the backup strategies being used.
Downloadable program that works even without an Internet connection, even if Obsidian HQ gets hit by a meteorite
Obsidian themselves having paid options1, which means a chance, clear plan and incentive to survive, and clear ways to support them. Better than whatever I’d be able to do with an abandoned open source project I rely on. (That said, I’d love them to open source at least the client at some point.)
This mix between personal-and-not-personal stuff, and having both my phone and my laptop as first-class citizens, is something I’ve never had before, and something I like, then if I also try to make it into my published blog I’m bound to find edge cases, one of them being tags. That said until now, and including this bit, everything I tried to do worked seamlessly.
This post describes my attempt to set up tags in a way that both Obsidian’s native autocompletion/search AND Hugo’s
tagging work.
Two types of tags
This blog is written in markdown and converted into a static website with Hugo.
Both the Diensttagebuch
and the journal
take files from specific subfolders in a specific Obsidian vault, and get converted into Hugo-friendly markdown using Obyde.
There are two kinds of tags as a result of that:
Obsidian’s #tags in the body of the text. They are the main kind supported, they get autocompleted, various #tag/subtag options can happen, etc. They get ignored by obyde/Hugo during conversion.
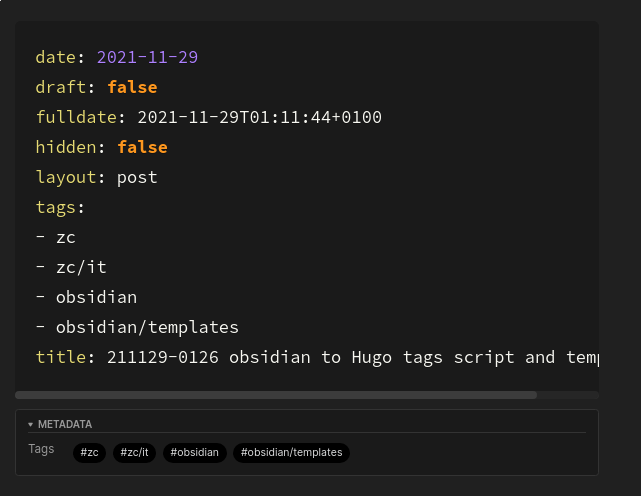
Front matter tags. They look like this in yaml/obsidian:
Obsidian metadata
They are parsed by Obsidian, as in searching by them works, but adding them manually is painful and has no autocompletion. One needs to set the ‘metadata’ to be shown in settings for them to be displayed.
They are the only ones understood by Obyde/Hugo, though.
I decided to write something that takes care of this for me easily.
Logical first step was Templater, which is a plugin for Obsidian I already use for my templating needs, such as generating a YAML frontmatter based only on a filename (see Day 1021).
I wanted:
obsidian’s #tags to become part of the yaml frontmatter
optionally - adding a line at the end of the file, like “Tags: #one #two #three” with the tags found in the frontmatter but not in the body.
I found a template2 doing pretty much this in the Template Showcase. It uses purely Obsidian’s/Templater’s JS/Templating language and is very close to what I want - but not exactly, and somehow I didn’t want to write more Javascript than needed.
My solution is more of a hack, less portable, and uses Python, because that’s what I know how to write best.
My solution
Python script to parse/add the tags to frontmatter
I wrote a (quick-n-dirty) Python script that:
gets the tags from the frontmatter of the input .md file
gets the tags found by Obsidian from an environment variable
finds tags found by obsidian but not in frontmatter
rewrites the .md file with all the tags added to the frontmatter.
fromfrontmatterimport Frontmatter
frompathlibimport Path
importosimportargparseimportyamlENV_VAR_TAGS ='tags'TAGS_LINE ="\nTags: "IGNORE_TAGS = {"zc"}
TAGS_TO_LOWER =Truedefget_args() -> argparse.Namespace:
parser = argparse.ArgumentParser(description='Remove tags')
parser.add_argument('--input_file', type=Path, help='Input file')
parser.add_argument('--print', default=False, action="store_true", help='if set, will print to screen instead of rewriting the input file')
parser.add_argument('--add_new_tagline', default=False, action="store_true", help='if set, will create/edit a "Tags: " line at the end of the file with tags found in front matter but not text body')
return parser.parse_args()
defstr_tags_to_set(tags: str) -> set:
"""
Converts tags like "#one,#two,#three" into a set
of string tags without the "#"s:
{'one', 'two', 'three'}
"""defparse_tag(tag: str):
ret_tag = tag.lower() if TAGS_TO_LOWER else tag
return ret_tag[1:]
return_set = set([parse_tag(x) for x in tags.split(",")])
return return_set
defset_tags_to_str(tags: set, ignore_tags: set = IGNORE_TAGS) -> str:
"""
The opposite of str_tags_to_set, returns space-separated "#tag1 #tag, ..".
Ignores tags that contain even part of any ignore_tags.
""" final_tags =''for tag in tags:
for i in ignore_tags:
if i in tag:
continueif TAGS_TO_LOWER:
tag: str = tag.lower()
final_tags+=f"#{tag} "return final_tags
defline_is_tag_line(line: str) -> bool:
return line[0:len(TAGS_LINE)] == TAGS_LINE
defget_tags_in_tagline(tagline: str) -> set:
words = tagline.split(" ")
return {w for w in words if w[0]=="#"}
defmain() ->None:
args = get_args()
input_file = args.input_file
# input tags tags_frontmatter = set()
tags_all = set()
tags_obs = set()
# output tags missing_obs_tags = set()
missing_yaml_tags = set()
parsed_yaml_fm = Frontmatter.read_file(input_file)
frontmatter_dict = parsed_yaml_fm['attributes']
post_body = parsed_yaml_fm['body']
has_tags_in_fm ='tags'in frontmatter_dict
# all tags (yaml + #obsidian) env_tags_by_obsidian = os.getenv(ENV_VAR_TAGS)
tags_all = str_tags_to_set(env_tags_by_obsidian)
# tags in yaml frontmatter tags_frontmatter = set()
if has_tags_in_fm:
tags_frontmatter = set(frontmatter_dict['tags'])
# "obsidian" tags (basically #tags in the text) tags_obs = tags_all.difference(tags_frontmatter)
# print(f"{input_file}: \n\# all_tags: {tags_all}\n \# obs_tags: {tags_obs}\n \# fm_tags: {tags_frontmatter}\n"# )# tags found in frontmatter but not in #obsidian missing_obs_tags = tags_frontmatter.difference(tags_obs)
# #obsidian tags not found in frontmatter missing_fm_tags = tags_obs.difference(tags_frontmatter)
if missing_fm_tags:
ifnot has_tags_in_fm:
frontmatter_dict['tags'] = list()
frontmatter_dict['tags'].extend(missing_fm_tags)
if missing_obs_tags and args.add_new_tagline:
final_tags = set_tags_to_str(missing_obs_tags)
# If last line is "Tags: " last_line = post_body.splitlines()[-1]
if line_is_tag_line(last_line):
# tags_in_tl = get_tags_in_tagline(last_line)# Remove last "\n" in post body post_body = post_body[:-1]
# Add the missing tags to the last line post_body +=" "+ final_tags +"\n"else:
# If we have no "Tags: " line, we add one final_string = TAGS_LINE + final_tags
post_body+=final_string
new_fm_as_str ="---\n"+ yaml.dump(frontmatter_dict) +"\n---" final_file_content = new_fm_as_str +"\n"+ post_body
# print(final_file_content)if args.print:
print(final_file_content)
else:
input_file.write_text(final_file_content)
if__name__=="__main__":
main()
Obsidian templates
To use the python file, I added to Templater a “System command user function”3add_tags with this code:
It calls the python file and passes to it the location of the currently edited file.
Then I create the template that calls it:
<%tp.user.add_tags({"tags":tp.file.tags}) %>
tp.file.tags returns all (all) tags found by Obsidian, so #body tags and frontmatter ones.
They get passed to the python script as an environment variable, canonical way to do this as per Templater docu4.
Initially I tried to pass them as parameter, but tp.file.tags passed in the system command user function always returned an empty list.
Usage
I write the text in Obsidian as usual, adding any #body tags I like, then at the end run that template through the hotkey I bound it to (<C-S-a>), done.
Better ways to do this
Problems with this solution:
won’t work on Android
too many moving parts
Ways to improve it:
It’s possible to do this without Python. The template I found2 uses JS to find the editor window, then the text in it, then the YAML node. Though intuitively I like parsing the YAML as YAML more.
I wrote it with further automatization in mind, for example running it in deploy.sh so that it parses and edits all the markdown files in one go. This would mean splitting the thing by words, taking care of correctly grouping #tags-with/subtags and not looking inside code blocks etc. Not sure here. I’d still have Obsidian as ultimate source of truth about what it considers a tag and what not.
What now?
This is the first long-ish blog post I’ve written in a while. Feels awesome. Let’s see if I can get this blog started again.