Masterarbeit Tagebuch
2023-10-10 10:03
- First conversation with CH about the topic
- Bits:
- I have a lower bound of about 1000 instances/examples for my own tasks
- Asking for help translating is OK!
- Using existing datasets, tasks, translated tasks is OK (if I cite ofc)
- A simple task measuring perplexity on a dataset is not required anymore in benchmarks but it’s possible
- As I thought, easy tasks are OK because not everyone uses gpt, most train their own models for tasks
- In the theory part I don’t need to explain the very basics, just Transformers+ and LLMs should be enough
- I have a lower bound of about 1000 instances/examples for my own tasks
- Decisions:
- I’ll use an existing eval harness!
- I’ll test the existing LMs on it at the end
- Also: finally set up Obsidian+Zotero and can now easily add citations! (231010-2007 A new attempt at Zotero and Obsidian)
2023-10-12 16:12
- Spontaneusly started writing the UP crawler thing and loving it!
- Read the first chapters of the basics of linguistics book, with more concentration this time, loving it too
- Wrote part of the chapter about UA from a linguistics perspective
2023-10-16 17:22
- Almost finished the UP crawler! It now:
- Accepts a date range and saves the URIs of articles posted in the days in that date range
- Crawls and saves all these URIs, with unified tags (their id + their Russian and Ukrainian name
2023-10-17 09:57
- Conversation with CH about possible tasks
- Deemphasize perplexity in general
- UP dataset can be used as downstream task to compare scores w/ benchmark
- OK for interference, OK for gendered language
2023-11-09 22:37
- UA-CBT day!
- Refactored UA-CBT code so it’s much cleaner!
- ADDED AGREEMENT/morphology to the options! Word shape too!
<SingleTask
context='Одного разу селянин пішов у поле орати. Дружина зібрала йому
обід. У селянина був семирічний син. Каже він матері: — Мамо, дай-но я віднесу обід
батькові. — Синку, ти ще малий, не знайдеш батька, — відповіла мати. — Не бійтеся,
матінко.'
question='Дорогу я знаю, обід віднесу. Мати врешті погодилась, зав’язала
хліб у вузлик, приладнала йому на спину, вариво налила у миску, дала синові в руки та й
відправила у поле. Малий не заблукав, доніс обід батькові. — Синку, як ти мене знайшов? —
запитав батько. — Коли вже так, віднеси обід до ______ , я туди прийду і поїмо. — Ні,
батьку, — сказав син.'
options=['цар', 'рибки', 'хлопця', 'сина', 'джерела']
answer='джерела'
>,
- Found out that pymorphy2 is not as good as I hoped :(
- Can I use spacy for getting morphology info, and pymorphy only for inflecting?
2023-11-27 23:33
- Decided to work on morphology just a bit,
- was a deep dive in morphology tagging systems (FEATS, Russian OpenCorpora etc.,) that I documented in 231024-1704 Master thesis task CBT
- Realized that picking the correct result from pymorphy is critical for me because I need it for correct changing-into-different-morphology later
- for this I need some similarity metric
- there’s a project to convert between different tagging systems OpenCorpora/russian-tagsets: Russian morphological tagset converters library. that will help me a lot, and then I can convert OpenCorpora to spacy/UD
2023-11-29 19:55
- started and finishing writing the program that discriminates between pymorphy2 morphologies based based on spacy data! will be a separate python package maybe
2023-12-01 16:53
- Uploaded the package to a public github repo!
- pchr8/pymorphy-spacy-disambiguation: A package that picks the correct pymorphy2 morphology analysis based on morphology data from spacy
- No real release process etc., but now it can be not just
pip install git+https://github.com/pchr8/pymorphy-spacy-disambiguation, but alsopoetry add git+https://github.com/pchr8/pymorphy-spacy-disambiguation
- UA-CBT task is surprisingly complex because pymorphy2-ua seems to have no singular tags for Ukrainian languages etc., described in 231024-1704 Master thesis task CBT. Which leads me to: Given how long and interesting each step is, maybe I can write blog posts for each of the CBT tasks? With more details than used in the Master thesis, AND with an easy place to copypaste from.
2023-12-02
- 231201-1401 How to read and write a paper according to hackernews suggested drawing a mindmap on paper, I did, and DAMN IT WAS HELPFUL
- Got a much better idea of the entire structure, but mostly - got many more new fresh awesome ideas
- Creativity does work much better when you’re doing pen and paper!
2023-12-04
- Spent the day doing more brainstorming and mindmaps but mainly looking into python LLM packages
- Was able to write a working example of Python program that generates instances for the 231204-1642 Masterarbeit evaluation task new UA grammar and feminitives task by talking to OpenAI and getting back JSON!
2023-12-07
- Started the evening wanting to start the 90% finished UP Crawler, but then realized I hate what I wrote and it’s ugly and started rewriting in. Was hard, since I already had even the CLI interfaces done with three cool progress bars ta the same time, and it was downloading the articles.
- Finished the evening having split it into an XML/Sitemap parser (much better than the previous approach of parsing the website archive pages themselves!) that was working, and 80% finished crawler-crawler part
- Just now (2023-12-08 20:06) realized the main key I missed - I can just use the code as-is to download the articles in the basic form to disk, and later (with a third pass) parse them for the tags and their translations to build a tag tree
- This will allow to decouple everything totally and it’s absolutely awesome
- Then I’ll track what has been downloaded and what not just by the presence of files/folders on disk!
2023-12-11
- Almost finished the UPCrawler, including a CSV export of the dataset!
- Started downloading one year of articleskk
- Wrote most of the thesis text about the UPCrawler
2023-12-13 17:26
Instead of doing things with higher priority, I:
- Uploaded the UP dataset to HF Hub! shamotskyi/ukr_pravda_2y · Datasets at Hugging Face
- Uploaded the code for it to Github! pchr8/up_crawler: Script that downloads articles from Ukrainska Pravda
- Moved the chapter to a separate dtb post under 231213-1710 Ukrainska Pravda dataset
2023-12-15
First 1h Masterarbeit meeting with CH, many ideas
- Human evaluation will be needed at least for a subset of tasks for each task!
231213-1710 Ukrainska Pravda dataset
- Issue: UP is chaotic about tags it assigns -> impossible to predict tags
- If humans can’t solve it it’s not a good downstream task
- Solution: article text -> title, out of X options
- give ~10 options with
- ~3 random from the dataset
- ~7 from similar articles from the dataset, e.g. all of the same topic ‘war’
- give ~10 options with
231024-1704 Master thesis task CBT
- general idea about label-studio to filter bad ones is solid
- -> what are the chances that a LM gets the answer right randomly?
- some examples are bad not because impossible, but because no context needed to narrow down solutions
- e.g. in the example below, it’s clearly ‘vater’ or ‘mutter’ regardless of what the context says:
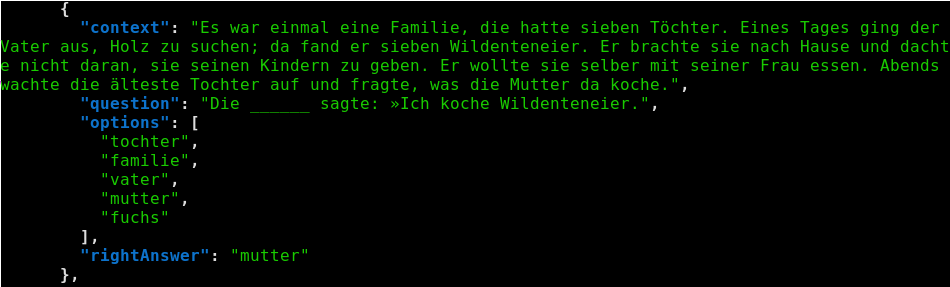
- … leading to a probability not of 1/4(..10) but 1/2
- e.g. in the example below, it’s clearly ‘vater’ or ‘mutter’ regardless of what the context says:
- one way to filter out such bad examples is to get a LM to solve the task without providing context, or even better - look at the distribution of probabilities over the answers and see if some are MUCH more likely than the others
- some examples are bad not because impossible, but because no context needed to narrow down solutions
- Issue with 2-3-4 plurals: I can just create three classes of nouns, singular, 2-3-4, and >=5
- don’t forget to discuss the morphology complexities in the masterarbeit
- Conveying the issues in English is hard, but I can (for a given UA example)
- provide the morphology info for the English words
- provide a third German translation
- Conveying the issues in English is hard, but I can (for a given UA example)
Feminitives task 231204-1642 Masterarbeit evaluation task new UA grammar and feminitives:
- the task format is a solved problem, papers in ~2015 about slot filling
- Adding male examples to the task would allow me to have a baseline and do fancier statistics about how often it gets e.g. the profession wrong.
LMentry-micro-UA
- Doing a subset of tasks that result in a static dataset works just as well
2023-12-17 00:19
LMentry
Started working on [[231203-1745 Masterarbeit eval task LMentry-static-UA]], new deep dive into pymorphy2.
Wrote a small library that does 2->дві/двох/другому/…
Finally wrote that pymorphy2 bugreport: Числа и проблемы с склонением в разборах всех украинских слов · Issue #169 · pymorphy2/pymorphy2 but also found workarounds for the singular/plural/make_agree issue.
Results for the first task!
low.generate_task("завтра", n=-1)
[
'Яка остання літера y слові "завтра"?',
'Яка літера в слові "завтра" остання?',
'В слові "завтра" на останньому місці знаходиться літера ...'
]
Finished a number of others as well, together with basic config mechanism and serialization.
2023-12-17 17:58
- LMentry-static-UA
- Refactored the abstract classes architecture in a way that is consistent and easier to use (for me, when writing the rest of the tasks…)
- Moved Numbers to a separate project: pchr8/ukr_numbers: Converts numbers (3) to Ukrainian words (третій/три/третьому/третьої) in the correct inflection
2023-12-19 17:34
Really productive long bike ride under the rain where I got the following ideas:
- CBT task annotation
- Basically - a way to annotate which words will become gaps.
- Given the stories, annotate them with the existing program, but use that only as suggestions. THEN, create out of each story a document where each word has a number and/or sentence-number and/or absolute number
- then either print it out or show on screen in a way, that each word has (as subscript/superscript/…) its number. The pre-selected words to make gap should be in bold. One sentence per line.
- Then just circle or annotate the numbers of the words I want to replace. E.g. for document N.10 word sentence 4 word 2 I’d circle it, an then mapbe write it down as 4-2/2 or just 2/2.
- Then I can automatically parse these numbers to get back the words, and generate the gaps based on them etc.
- Other task ideas
- GPT4 can’t do things like “which ATU indexes are missing at the following list”. Test for that. “Which numbers are missing in the following list”, and then do gaps of diff sizes, and numbers of different number of digits (e.g. is 404,405,…,408 harder than 4,5,…,8?)
- How well does GPT-X parse Ukrainian-language instructions about output format, e.g. JSON schemas?
- ARCHITECTURE
- A single data structure to represent tasks (+items), similar to the one I wrote for LMentry. A question, the correct answer, and any additional metadata useful for me for later analysis, e.g. LMentry whether the correct choice is closer to the start of the question or whether the number is a ’large’ one.
- Reuse that data structure across all my tasks, e.g. CBT, LMentry-X, etc.
- Write a single script that out of a task dataframe creates a HF dataset, that may or may not include all the metadata rows etc.
- Write analysis code once that assumes that structure w/ metadata
- Rewrite LMentry existing templating logic to get a template + metadata belonging to it: not a list of strings, but a list of dicts / named-tuples /…..
- Next steps
- Implement the architecture bit, generate some basic datasets in HF format, and start writing code that runs the evaluations themselves! Then start finishing the other tasks.
2023-12-20 12:19
CH short discussion:
- annotation scheme OK if I think it’ll make my life easier
- clumping/packaging - keeping it separate better if I’ll want to separate it in the future. Add together only the parts I’m adamantly sure won’t need task-specific changes
AP short conversation:
-
for the CBT graph story generation, he suggests using a common onthology for the graphs
- “fairy tale generation” seems promising
-
LMentry
- updated templates to use dataclasses that allow adding metadata to each template string
- updated code to read templates from YAML
2023-12-21 22:34
LMentry:
- wrote a better dataset generator script
- added serialization of tasks into HF and CSV formats
- realized there’s the HF evaluation library, and that it’s basically all I need
- decided that I want a HF dataset with diff configs, a la glue, for all my subtasksG
- Refactored/renamed/documented some of the class structure, I’ll thank myself later.
2023-12-22 18:43
-
TIL about UNLP 2024 | Call For Papers workshop on LREC-2024! (https://t.me/nlp_uk/8570)
- Paper deadline is March 1, 2024.
- Sign from God that I should submit a paper about the benchmark if it’s done by then. And the strongest motivation I could imagine as well. :P
-
unrelated but, heavily improved my pchr8/ukr_numbers package (should not be my priority at all, and hopefully I’m done with it for now)
2023-12-24 14:33
… and up to 2023-12-28:
- promised myself I wouldn’t write any task code — and I did
- basically finished the grammar bits, a notation I like, tested pandoc conversions etc.
- 231225-2240 Glosses markdown magic / 231226-1702 Ideas for annotating glosses in my Masterarbeit
- And realized that tufte style is really nice for me at least for proofreading:

- Started describing my LMentry tasks
2024-01-04 14:35
Re-read what I have and I mostly like it!
Planned next steps:
- Finish UA-CBT to a reasonable extent
- Dig deep into formats / eval harnesses / benchmarks code,
- write the relevant theory as I go
- find cool UA LMs to use for my tests
- Finish basic code for evaluation and experiments to have it ready
- Finish the existing tasks, LMentry and UA-CBT as the key ones
- (they alone would be enough honestly)
- Run experiments, and hopefully write the paper based on what I have!
- Finish the Pravda dataset eval task code
- Solve for real the pandoc issues etc. and have code for camera-ready citations, glosses, etc.
- Write the additional tasks if I have any time left at this point
- Run all experiments
Honestly sounds like a lot and like I have much less time than I expect. Especially given that it’s not gonna be the only thing going on in my life. Ah well
2024-01-05 15:32
- conversation with CH
- need sources for everything that’s not common knowledge
- clearly including my grammar stuff
- criteria for appendixes are the same - all sources should be there as well
- when I’ll be shortening things, this will be the criterium I’ll use when decide which paragraphs to remove and which to not
- grammar notation OK, but…
- … need as little grammar as possible
- but a different secord Prüfer possible if not, and there’ll be questions about the grammar in this case
- need sources for everything that’s not common knowledge
2024-01-11 12:52
- Idea for RU-UA interference task!
- find false friends through word embeddings
- same word, different place in RU-UA word embeddings = false friend!
- find false friends through word embeddings
- Finally talked to a linguist!
- prep: 240111-1157 Linguistic questions in the Masterarbeit
- She thinks the idea above is solid enough
- Correct context in the task questions is the most important part in any case
- She OK’d the UA-GEC ablation idea that my system measures the correct language inteference if it’s more sensitive to errors by RU native speakers than other languages
- I can happily remove typos etc. to focus only on the interference - so basically as planned focus only on some error classes in UA-GEC
2024-01-12 11:13
-
CH conversation
- grammar and glosses and notation to theory, list of abbreviations like ML before introduction
- introduction:
- why?
- non-English is important
- the world needs more Ukrainian NLP
- if I want to emphasize RU/UA base it on facts
- statement - what I’m doing
- clearly formulate research goal
- hypothesis
- goals
- why?
- theory
- basically only what’s incleded in my work — no LSTMs, today BERT+ transformers LLMs and stuff
- LMs define
- incl. as representation of words, basically embeddings but more general
- intrinsic/extr. introduce but briefly — like in the paper
- nowadays extrinsic is definitely more important
- and make it clear I focus only on it
- task framings — no easy answers, look into modern paper
- theory VS related work
- a lot of overlap
- thery and afterwards related work
- because then it’s easier to explain theory before
- notable tasks/benchmarks to RELATED work, keep the rest in theory
- incl. eval harnesses
- include some Ukrainian NLP bits in the theory
- related work is what I compete with basically
- => all packages in theory
- explain things like POS tagging, SQuad etc. in theory as well
- if I don’t find enough Ukrainian benchmarks to compete with then talk about general English things to more or less give an idea about benchmarking in general
- construction, validation etc. goes inside the individual tasks
- challenges go in the task description
- human validation keep separate from the tasks
-
Where to put pravda dataset
- can it become part of the benchmark?
- it can be part of the benchmark itself
- zero-shot text classification
- Decision: becomes an eval task!
-
CBT task — manually filter the instances myself, so that I’m better than the original CBT
2024-01-16 13:44
What if I do an eval benchmark containing only my tasks VS eval benchmark with my tasks and the other three? eval-ua-tion and eval-ua-tion+?
2024-01-18 16:49
- Started playing with 240118-1516 RU interference masterarbeit task embeddings mapping
2024-01-19 10:49
Questions:
-
Interf
- many older papers, no one did for RU/UA
- mapping vectors
- will I have to describe word2vec then?
- reasonable minimals
- which dataset goes will be in paper?
- do I have time, based on intuition??
- how to use these words?
-
otherwise
- existing code
- pravda in the future
- remaining questions
-
Conversation
- deadlines and scope
- UNLP paper deadline 1 march
- Thesis extension is absolutely possible from his side, but I don’t really want to
- UNLP paper might be about some of the tasks, but not the entire eval benchmark
- decisions:
- do CBT, maybe other low-hanging fruits
- if something needs dropping, it’s UP
- Drop the not-my datasets eval tasks (squad and POS), becomes related work then
- most important focus now is Eval code
- Interference and word embeddings:
- decided to not do this in the context of thesis and paper
- will stay as a side project and maybe paper next year
- has a chance because it’s INTERESTING, as opposed to some of the other eval tasks
- deadlines and scope
2024-01-22 10:21
^90748a
Yesterday:
- thought of and started implementing generating folk tales for CBT task via prompts, not graphs
Today:
- discovered that llama2-70b-chat outright starts talking in Russian
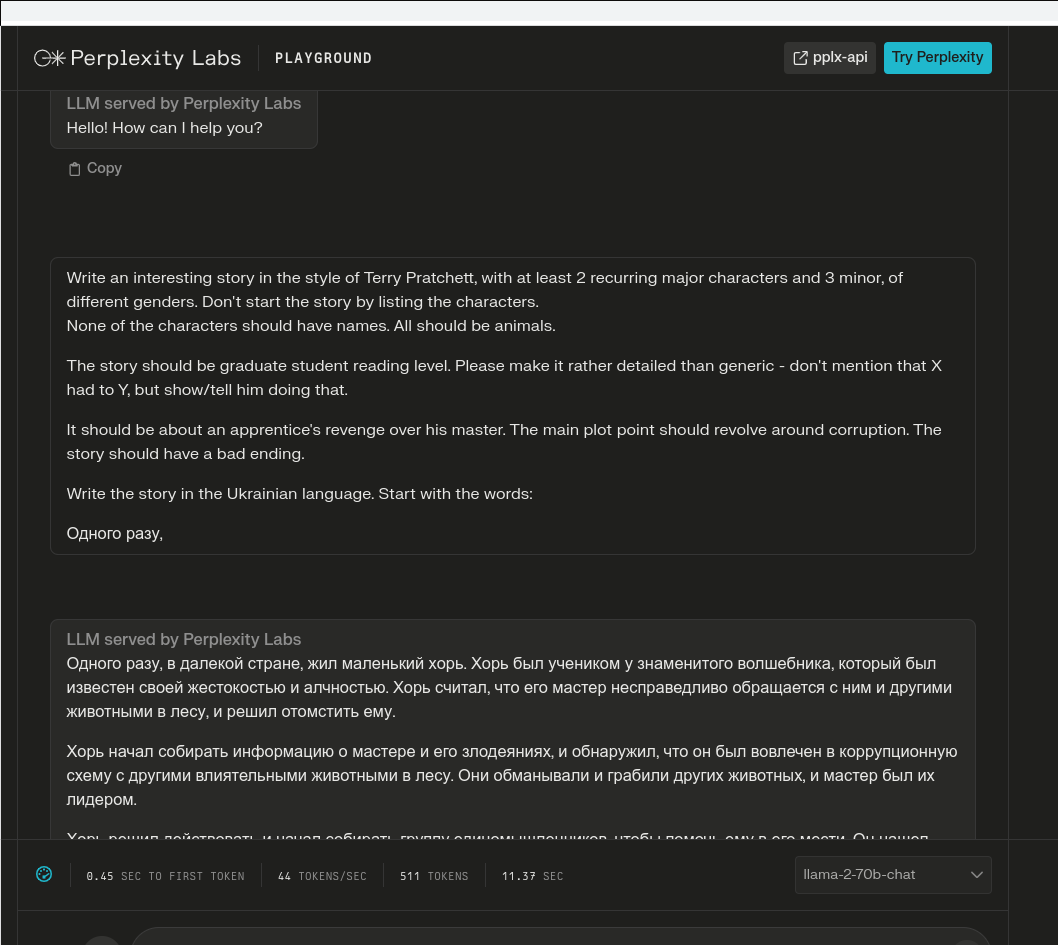 G
G - others often insert random English words or letters:
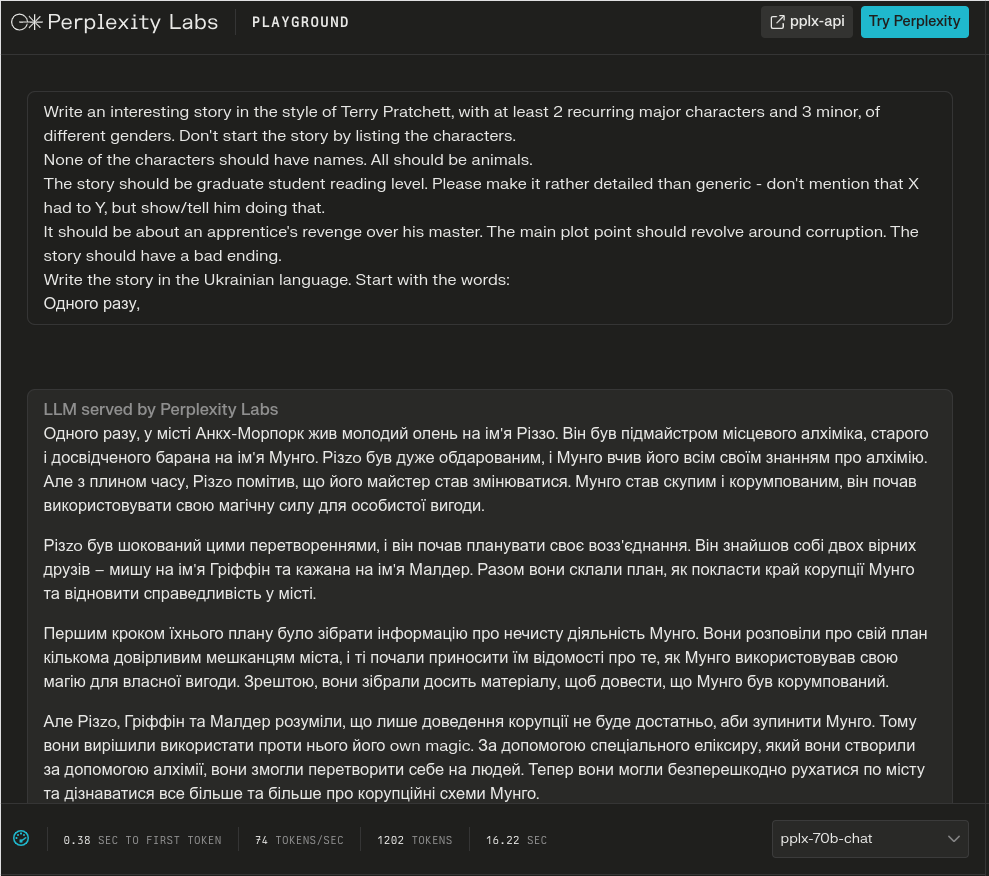
- started and finished the code that interfaces with OpenAI to generate the stories; it reads the CSV of the template generator and writes a CSV with an additional column
- learned that one gpt4 story is basically 5 cents, more than I expected honestly. We’ll see
2024-01-23 13:14
- CBT stories
- Read the CBT generated stories, they have a lot of errors, most clearly Russian-influenced. They will need correction.
- ChatGPT can correct them if you paste the story and ask it to correct the errors!
- Lastly, intuitively - since I’ll be proofreading the stories myself anyway - I can capitalize the words that are good candidates to become gaps. And parse it with the existing code for LMentry.
- Created a google docs dir and put there the google sheets - there one will be able to paste the corrected stories
- added a pricing column to the dataframe that calculates the cost of every story generated
- Created templates v3, removing gender bits, gendered “his” from the templates, and later v4 removed “prove that they are a good SON” which creates conflicts with “cat”.
2024-01-24 20:31
- Played a lot with CBT task generation
- Improved many bits, especially animacy!
- made named_entities include not just nouns, but PROPN as well. Helps with “Миша, Кіт, Собака”
2024-01-25 21:18
- Improved CBT task generation by finally breaking down the one big function
- Fixed a bug w/ spacy morphology being taken as basis, not just the spacy-detected lemma and POS.
- Fixed the most embarassing bug ever in my disamb package: Fix wrong best morphology index · Issue #6 · pchr8/pymorphy-spacy-disambiguation
- Generally many weird small inflection errors went away now.
2024-01-26 12:34
-
Conversation with CH
- He liked the CBT story generation approach w/ the spreadsheet, hypothetically worth a paper sometime
- Showed in more detail the current state CBT + LMentry
- Levy Omer, third author of the LMentry project, is allegedly really cool and I should check him out
- CBT template: I can try with 8 minor characters etc., to solve the problem with not enough characters, and we’ll see how this impacts the story (bad as I expect or not)
- Pausing the generation of stories for a couple of days until maybe there’s a different OpenAI key, we’ll see
-
Finally started w/ evaluation!
- Made a basic loop that goes through models and datasets and does inference!
2024-01-29 19:55
- Eval
- went deeper in existing things for this in 240129-1833 Writing evaluation code for my Masterarbeit
- decided on jsonl format for openai interactions through their evals
- started implement writer for this in LMentry:
system_templates: - 'Ви розв''язуєте екзамен з української мови. Вкажіть правильну відповідь одним словом, без лапок. Наприклад: \n Питання: яке слово ПЕРШЕ у реченні "Я зараз буду снідати"? \n Відповідь: Я'
- Went deeper into eleutherAI harness as well
- Got inspired by the OpenAI evals README:
- improved writing
2024-01-29 19:55
- Eval
- went deeper in existing things for this in 240129-1833 Writing evaluation code for my Masterarbeit
- decided on jsonl format for openai interactions through their evals
- started implement writer for this in LMentry:
system_templates: - 'Ви розв''язуєте екзамен з української мови. Вкажіть правильну відповідь одним словом, без лапок. Наприклад: \n Питання: яке слово ПЕРШЕ у реченні "Я зараз буду снідати"? \n Відповідь: Я'
- Went deeper into eleutherAI harness as well
- Got inspired by the OpenAI evals README:
- improved writing
2024-01-30 23:55
- Implemented first lm-eval files for my datasets!
- Ran the first lm-evals on Rancher w/ Docker and pods!
- found/fixed misc issues like flattening w/
_and found a bug in the ground truth generation of lmentry - TODO for next time.
2024-01-31 18:48
- Learned how to use the CLI for Rancher: 240131-1730 Connecting to a Rancher pod with kubectl terminal
- Implemented splitting in lmentry and used a split as separate fewshot one
- played with zeno
- did my first ‘real’ eval of multiple datasets
2024-02-01 22:23
- UA-CBT
- Implemented per-story splitting into named splits
- Added basic deduplication for tasks
- Decision: CSV->HF thingy will live in eval, CSV will be the main output format of all tasks, and no need to harmonize CBT & LMentry-static because I’ll write individual lm-eval configs for all of them anyway.
2024-02-02 16:55
- Baselines
- Setup a cool label-studio project for labeling and baselines (240202-1312 Human baselines creation for Masterarbeit)
- made it available online through cloudflare tunnels and Docker
- Discovered Bard and the Gemini API!
- And generated stories with it and it has A LOT of potential
2024-02-05 20:09
- CBT
- 240202-1806 CBT Story proofreading for Masterarbeit: improved layout
- improved generated story CSV writing so that a separate CSV is created with only the NEW stories, that I can then import into label-studio w/o duplicates or overwriting
- started using new OpenAI keys
- story templates generation:
- rewrote the template generator so that some configurable bits like READING_LEVEL are saved as metadata as well!
- ALSO this allows editing template generation & creating a new file w/o needing hacks to keep the previously generated ones
- CBT Story generation
- Added some more logic for Gemini models that
- “please make this story longer”
- “please fix the errors in this story”
- Decided that Gemini is good at fixing stories
- And that I need to relax its safety settings because sometimes it gets blocked.
- And that it’s hard to do but I did it
- Added some more logic for Gemini models that
2024-02-06 11:56
- Videocall with CH
- answered many questions
- OK not to follow instruct model formats like everyone else, but mention it
- changing formulation of n-shot bits: usually it’s the same, but no info on this
- split w/o n-shot examples should be ~1000
- CBT
- CH likes the idea of
- adding verbs, because it makes the task more diverse
- adding “unknown/impossible”
- No opinion on adding random animals, PEOPLE etc. as distractors
- CH likes the idea of
- HF Datasets configs is easy, ask N. she did this
- CBT+LMentry alone are OK
- Uploading all datasets on HF hub is OK
- Gemini model TOS:
- creating an eval dataset != training models, so it’s fine
- I have to mention that no one is allowed to train on the datasets in the paper
- Thesis registration: I find the paper and fill it and send it to him
- Multiple-choice framing: ideally have an int label, but failing that both options OK
- Gemini model evaluation WILL be needed because I say it’s better than gpt4 at Ukrainian and use it
- no one cares about tests
- datasets splits uniformity
- do a random sampling, having it representative is not too critical
- no insights about temperature
- there will be no access to the training server for a bit longer, likely Thu+, he’ll ping me on this
2024-02-07 14:12
-
CBT task
-
implemented calculating prev occs of match in beginning of question span as well, which increases number of matches
- 134->172 NAMED_ENTITIES in 16 stories for min. num. occs of 1
-
CBT found a problem with adjectival character names (черепаха Повільна)
- The new generated stories have names like Грізний that get parsed as ADJF by Pymorphy (spacy thinks they’re
NameType=Sur/Giv) - Looked at it deeper inside 231024-1704 Master thesis task CBT and decided to give up and remove such stories.
- Updated anno guidelines
- The new generated stories have names like Грізний that get parsed as ADJF by Pymorphy (spacy thinks they’re
-
Implemented most frequent baseline and adding most frequent all genders distractor to options
-
-
LMentry
- Implemented getting words and sentences from UP as a start.
- implemented task type w/ word categories, and two tasks of this type!
- generated word categories list w/ chatgpt
2024-02-10 19:18
- CBT
- Generated final (hopefully) version of CBT tasks
- main change: nouns need 4 mentions to become gaps, other parts 2. The goal is to avoid too many uninteresting common-noun gaps in the last generic sentences of stories (.. and they learned that friendship is the biggest treasure.)
- set up the label-studio project for this
- including a lot of playing with HTML to make it easy to filter them:
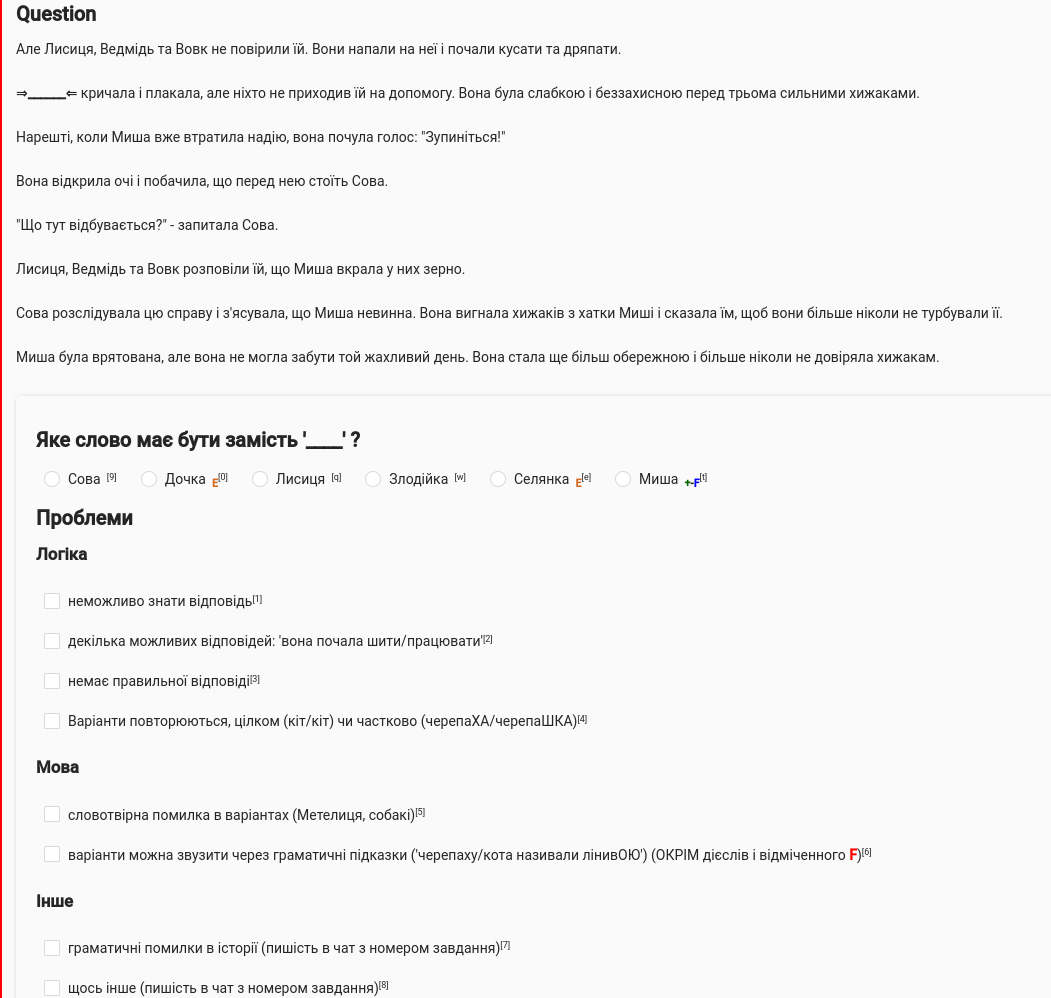
- including a lot of playing with HTML to make it easy to filter them:
- Created the anno guidelines for them (240210-0310 CBT Task filtering instructions) and even a video tutorial.
- .. and got some awesome people to start helping me filter the tasks into good and bad ones!
- Generated final (hopefully) version of CBT tasks
2024-02-13 22:31
- CBT
- Really nice 2h whereby chat with everyone who’s helping annotate, got through 1150/~1300 instances!
- Added more task instances from new stories because apparently ~77% of tasks are ‘go’ and ~65% of stories
- Pravda
- Wrote the code and created the dataset with 5000 articles, ukr+eng version
- Uploaded temporarily to shamotskyi/ukr_pravda_titles_ukr · Datasets at Hugging Face, dataset card etc. will come later
- Doing very simple count vectorization + cosine similarity by tags, we’ll see if it’s too easy or not.
2024-02-15 14:54
- Pravda:
- Added dataset cards to both datasets:
- Added the 2y version to the 2y dataset, learned a lot about HF dataset file structure and SSH access etc. in the future:
- LMentry
- While I was sleeping, one of the people helping me wrote a TG bot for human-eval on the json files I sent (as example of structure, not by any means final versions! Now they are I guess), and everyone started and finished doing a human baseline on them. Wow. WOW.
- Gemini TOS:
- Looked at the TOS again and now they forbid its use only for the creation of COMPETING products, not any ML things. Neat!
- UA-CBT
- filtered and cleaned up the dataset and uploaded it to the HF Hub!
- shamotskyi/ua_cbt · Datasets at Hugging Face
- Private for now till I finish cleaning it up.
- TODO should I upload the intermediate stages and optionally raw data (anonymized)?
- Lmentry
- Found a dictionary with frequency, sampled words from there by pos etc.Go
2024-02-18 23:54
- Played with HF Hub dataset configs
- UA_CBT: added three splits to it viewable in the Dataset Viewer! shamotskyi/ua_cbt · Datasets at Hugging Face
- LMentry-static-UA
- uploaded it to HF hub with a complex python dataset loader thingy, which makes it impossible to view in the dataset viewer which makes me sad
- Couldn’t find any good solutions for this :(
- Remaining
- The entire paper
- Human evaluations for a couple of the datasets
- Analysis of the human evals for all of them
- Evaluating all existing LMs on these datasets
- separate few-shot splits for all of them!
- Evaluation
- Created eval for
- UP
- UA-CBT (including fancy fn to split by ‘,’)
- all LMentry-static-UA tasks
- Created eval for
2024-02-20 18:31
- Started writing paper, analyzed all the human baselines and they are fascinating.
- UA-CBT:
- added some more fixes to the dataset, especially Лихвар that had to be fixed inside options as well
- re-uploaded it as json as the others for better lists handling
2024-02-26 23:27
- much harder to work lately
- CBT created fewshot split based on new optimistic story, I fixed+filtered the bits, and added as split to the CBT dataset
2024-02-27 23:27
- LMentry:
- wrote code + sources for fewshot split other words sentences and categories
- left: upload to HF
2024-02-29 21:54
- Fixed a great many errors in datsaets and running thing
- Wrote a simple wrapper to evaluate datasets over multiple models
- REMAINING
- datasets
- UP-titles exact dataset matching prompts
- integrate unmasked option
- evaluate on openai models
- evaluate on gemini models
- paper
- integrate human masked baseline
- datasets
2024-03-11 10:36
Long pause in it all, UNLP paper submitted, time to breathe, next up: finish the thesis till
2024-03-25 23:49
Longer hiatus, but: moved the thesis to overleaf and will keep working on it there, soft internal deadline eom, hard internal deadline 15.04, hardest-deadline-ever is in October.