serhii.net
In the middle of the desert you can say anything you want
-
Day 1821 (26 Dec 2023)
Ideas for annotating glosses in my Masterarbeit
Current best:
eng: the manNOM.SG saw the dogNOM.SG
ukr: чоловікman-NOM.SG побачивsaw-PST собакydog-ACC.SGIdeas
I’d love to integrate the usual UD feats bits but they take a lot of space, and it’s either latex magic or one word per line.
-
ukr: чоловік(man): Case=Nom|Number=Sing побачив(saw) собакy(dog): Case=Acc|Number=Sing
-
$чоловік^{man}_{Case=Nom|Number=Sing}$
-
${\underset{man}{чоловік}}^{Case=Nom|Number=Sing}$
-
$\underset{Case=Nom|Number=Sing}{чоловік^{man}}$
-
$\underset{NOM.SG}{чоловік^{man}}$
-
${\underset{man}{чоловік}}^{Case=Nom|Number=Sing}$
-
${\underset{man}{чоловік}}^{NOM.SG}$
-
${\underset{man}{чоловік}}^{NOM.SG}$ ${\underset{saw}{побачив}}$ ${\underset{dog}{собаку}}^{GEN.PL}$
я I Case=Nom|Number=Sing
побачив saw
собаку saw Animacy=Anim|Case=Acc|Gender=Masc|Number=Singukr: чоловікman-NOM.SG побачивsaw-PST собакydog-GEN.PL
${\underset{man}{чоловік}}$ Case=Nom|Number=Sing ${\underset{man}{чоловік}}$ Case=Nom|Number=Sing
I think this is cool! But hell to write and parse:
$\underset{\text{NOUN.NOM}}{\overset{\text{man}}{\text{чоловік-}\varnothing}}$ $\underset{\text{PST}}{\overset{\text{saw}}{\text{побачив}}}$ $\underset{\text{NOUN-ACC}}{\overset{\text{dog}}{\text{собак-у}}}$.
$\underset{\text{NOUN.NOM}}{\overset{\text{man}}{\text{чоловік-}\varnothing}}$ $\underset{\text{PST}}{\overset{\text{saw}}{\text{побачив}}}$ $\underset{\text{NOUN-ACC}}{\overset{\text{dog}}{\text{собак-у}}}$.Let’s play more with it:
$\underset{\text{Case=Nom|Number=Sing}}{\overset{\text{man }}{\text{чоловік}}}$ $\underset{\text{}}{\overset{\text{saw}}{\text{побачив}}}$ $\underset{\text{Case=Acc|Number=Sing}}{\overset{\text{dog}}{\text{собаку}}}$.
I can split it in diff lines: $\underset{\text{Case=Nom|Number=Sing}}{\overset{\text{man }}{\text{чоловік}}} \underset{\text{}}{\overset{\text{saw}}{\text{побачив}}} \underset{\text{Case=Acc|Number=Sing}}{\overset{\text{dog}}{\text{собаку}}}$.
$$\underset{\text{Case=Nom|Number=Sing}}{\overset{\text{man }}{\text{ЧОЛОВІК}}} \underset{\text{}}{\overset{\text{saw}}{\text{ПОБАЧИВ}}} \underset{\text{Case=Acc|Number=Sing}}{\overset{\text{dog}}{\text{СОБАКУ}}}$$
Splitting by morphemes
ukr: використовуватимуться Aspect=Imp|Number=Plur|Person=3
1 використовуватимуться використовуватися VERB _ Aspect=Imp|Mood=Ind|Number=Plur|Person=3|Tense=Fut|VerbForm=Fin 0 root _ SpaceAfter=Noukr: використовуватимуть-сяVERB-REFL
ukr: використовуватимутьVERB -сяREFL
$\underset{\text{NOM.SG}}{\overset{\text{man }}{\text{чоловік}}}$ $\underset{\text{PST}}{\overset{\text{saw}}{\text{побачив}}}$ $\underset{\text{SG-ACC}}{\overset{\text{dog}}{\text{собак-у}}}$.
Markdown collaboration tools
I’ll need something like overleaf for my markdown thesis.
5 Best Collaborative Online Markdown Editors - TechWiser
- HackMD
- Markdown quick start guide - HackMD is nice!
- The comments are part of the markdown code itself
- but no way to highlight a certain phrase, just add a comment in a place of the text
- you can share your doc to make it editable to not-logged-in users
- Seems to hold my current thesis length quite well
- I think I can stop looking
-
-
Day 1820 (25 Dec 2023)
Glosses markdown magic
Interlinear Glosses
… are a way to annotate grammar bits of a language together with translation: Interlinear gloss - Wikipedia
The Leipzig Glossing Rules are a set of rules to standardize interlinear glosses. They are focused less on understandability and more on consistency.
- Markdown
- cysouw/pandoc-ling: Pandoc Lua filter for linguistic examples
- gunnarnl/pangb4e: Pandoc filter for gb4e support
- parryc/doctor_leipzig: Leipzig, MD - glossing for Markdown
- one can always do
<span style="font-variant:small-caps;">Hello World</span>[^1]
- Python
Using interlinear glosses
I’m writing my thesis in Obsidian/Markdown, synced to Hugo, later I’ll use sth like pandoc to make it into a PDF, with or without a latex intermediate step.
EDIT: newer technical part lives now here 231226-1702 Ideas for annotating glosses in my Masterarbeit
Pandoc-ling
cysouw/pandoc-ling: Pandoc Lua filter for linguistic examples
> pandoc --lua-filter=pandoc_ling.lua 231225-2240\ Glosses\ markdown\ magic.pandoc.md -o test.pdf Error running filter pandoc_ling.lua: pandoc_ling.lua:21: attempt to call a nil value (method 'must_be_at_least') stack traceback: pandoc_ling.lua:21: in main chunk:::ex | Dutch (Germanic) | Deze zin is in het nederlands. | DEM sentence AUX in DET dutch. | This sentence is dutch. ::::::ex | Dutch (Germanic) | Deze zin is in het nederlands. | DEM sentence AUX in DET dutch. | This sentence is dutch. :::
.. it was the pandoc version. Updated. No error, but no luck either.
Digging into the examples I think this is happening:
Code is code. Using that formatting without code makes it be interpreted as a line, and that doesn’t survive the obsidian’s pandoc extensions’ conversion to pandoc markdown.
The original docu generation had this script:
function addRealCopy (code) return { code, pandoc.RawBlock("markdown", code.text) } end return { { CodeBlock = addRealCopy } }It changes code blocks into code blocks and the content of the code block. Then the
:::block is put after the code but like normal markdown text, and it gets correctly changed by the pandoc-ling filter.> pandoc 231225-2240\ Glosses\ markdown\ magic.pandoc.md -t markdown -L processVerbatim.lua -s --wrap=preserve | pandoc -L pandoc_ling.lua -o my.htmlI can drop exporting extensions and just manually convert bits?..
This works:
> pandoc "garden/it/231225-2240 Glosses markdown magic.md" -t markdown -L pandoc_ling.lua -s > pandoc "garden/it/231225-2240 Glosses markdown magic.md" -L pandoc_ling.lua -o my.htmland is OK if my masterarbeit file will have no complexities at all.
(Can i add this as parameter to the existing bits?)
YES!
-L /home/sh/t/pandoc/pandoc_ling.luaadded as option to the pandoc plugins, together with “from markdown” (not HTML) option, works for getting this parsed right!
(Except that it’s ugly in the HTML view but I can live with that)
And Hugo. Exporting to Hugo through obyde is ugly as well.
I colud write sth like this: A Pandoc Lua filter to convert Callout Blocks to Hugo admonitions (shortcode).
We’lll o
Obsidian link gloss plugin
Mijyuoon/obsidian-ling-gloss: An Obsidian plugin for interlinear glosses used in linguistics texts.
Pandoc export from HTML visualizes them quite well.
\gla Péter-nek van egy macská-ja \glb pe:tɛrnɛk vɒn ɛɟ mɒt͡ʃka:jɒ \glc Peter-DAT exist INDEF cat-POSS.3SG \ft Peter has a cat.\gla Péter-nek van egy macská-ja \glb pe:tɛrnɛk vɒn ɛɟ mɒt͡ʃka:jɒ \glc Peter-DAT exist INDEF cat-POSS.3SG \ft Peter has a cat.\set glastyle cjk \ex 牆上掛著一幅畫 / 墙上挂着一幅画 \gl 牆 [墙] [qiáng] [wall] [^[TOP] 上 [上] [shàng] [on] [^]] 掛 [挂] [guà] [hang] [V] 著 [着] [zhe] [CONT] [ASP] 一 [一] [yì] [one] [^[S] 幅 [幅] [fú] [picture.CL] [] 畫 [画] [huà] [picture] [^]] \ft A picture is hanging on the wall.Maybe a solution
- Do all my glosses using pandoc-ling format
- put them into code blocks belonging to a special class
- write a very similar filter to processVerbatim but that operates only on code blocks of this class
- when outputting to Hugo they’ll stay as preformatted code
- when exporting to pandoc run them through it first, then pandoc-ling, leading to pretty glosses in the final exported option
function addRealCopy (code) -- return { code, pandoc.RawBlock("markdown", code.text) } if code.classes[1] == "mygloss" then return { pandoc.RawBlock("markdown", code.text) } else return { code } end end return { { CodeBlock = addRealCopy } }Should parse:
:::ex | Dutch (Germanic) | Deze zin is in het nederlands. | DEM sentence AUX in DET dutch. | This sentence is dutch. :::Should stay as code:
:::ex | Dutch (Germanic) | Deze zin is in het nederlands. | DEM sentence AUX in DET dutch. | This sentence is dutch. :::pandoc "/... arden/it/231225-2240 Glosses markdown magic.md" -L processVerbatim.lua -t markdown -s | pandoc -L pandoc_ling.lua -o my.htmlIt works!
But not this:
> pandoc "/home231225-2240 Glosses markdown magic.md" -L processVerbatim.lua -L pandoc_ling.lua -o my.htmlLikely because both require markdown and the intermediate step seems to break.
Maybe I’m overcomplicating it and I can just use the UD I can use superscripts!
Just use superscripts
The inflectional paradigm of Ukrainian admits free word order: in English the Subject-Verb-Object word order in “the manman-NOM.SG saw the dogdog-NOM.SG” (vs “the dog man-NOM.SG saw the manman-NOM.SG “) determines who saw whom, while in Ukrainian (“чоловікman-NOM.SG побачивsaw-PST собакУdog-GEN.PL”) the last letter of the object (dog) makes it genetive, and therefore the object.
- Markdown
-
Day 1816 (21 Dec 2023)
Perceptual image hashes
Related: 231220-1232 GBIF iNaturalist plantNet duplicates
KilianB/JImageHash: Perceptual image hashing library used to match similar images does hashes based on image content, not bytes (a la SHA1 and friends)
Hashing Algorithms · KilianB/JImageHash Wiki is a cool visual explanation of the algos involved.
Kind of Like That - The Hacker Factor Blog is a benchmark thing, TL;DR
- aHash is very quick but many FP
- dHash just as quick but better
One of the comments suggest running a quick one with many FPs and then a slower one on the problematic detected images.
-
Day 1815 (20 Dec 2023)
GBIF iNaturalist plantNet duplicates
TL;DR
- plantNet does no deduplication I could find
- iNat
- allows literally duplicating observations with a click e.g. if there are multiple plants to detect, keeping image files constant
- etiquette allows duplicating observations in many cases, unless it’s e.g. literally the same photo (but diff observations for different growth stages is fine)
- good karma to mention related observations in the description
- does no deduplication by images etc. on its side, but may soon have something
- GBIF
- is more worried about adding the same herbarium plant twice from different collections or same picture both from iNat and Pl@ntNet
- does deduplication more like record linking
- has a clustering/collection feature but it looks for similar observations only across datasets, not within the same one. But the blog post about it is awesome and usable to do deduplication within same datasets as well.
- is more worried about adding the same herbarium plant twice from different collections or same picture both from iNat and Pl@ntNet
- Recommendation: roll SHA1 ourselves
iNaturalist
Fazit
- duplicates can happen if:
- bad: multiple pics of the same organism at same time as different observations
- good: different organisms on the same pic
- using the duplicate function -> URI seems to be preserved
- manually upload picture, possibly cropped
- etiquette seems to be that if it’s different parts of picture add it to description
- we can look for links to observations in descriptions
- no auto-duplication detection included in iNat. Wikipedia uses SHA1 for this purpose.
Refs
-
Finally, you can totally upload the same picture multiple times if there’s multiple organisms in one picture that you would like identified - you want to have a separate observation for each organism. Usually if I do this I’ll make a note in the description of what I’m looking to have IDed.
- duplicate observations OK if same plant different time etc.
-
https://www.inaturalist.org/posts/28325-tech-tip-tuesday-duplicating-observations: “perfectly okay to duplicate observations”, because species in the background etc.
- there’s literally a function for this
- otherwise one can crop the picture
-
https://forum.inaturalist.org/t/duplicate-obervations/18378/4
- wikimedia uses SHA1 to identify duplicates
-
- inat doesn’t have duplicate detection for pictures uploaded multiple times (discussion on adding this feature)
-
Random
-
just came across a user who repeatedly submits pairs of some robber fly photo weeks apart. (https://forum.inaturalist.org/t/create-a-flag-category-for-duplicate-observations/29647/42)
-
Example instances
- same pic, different crops:
- Other observations mentioned in descriptions
PlantNet
- TL;DR nothing.
- Found nothing useful after a quick google search
- Pl@ntNet automatically identified occurrences
- TODO understand what is that, but I think it’s about requests than about plants:
remove shared queries (already present in observation dataset) - remove duplicate session (keep the most recent query based on the session number) -
- TODO understand what is that, but I think it’s about requests than about plants:
GBIF
Fazit
- GBIF has clustering of records to find duplicates, but does it only between datasets, not within the same one
- REALLY cool pages on the topic and in general: Identifying potentially related records - How does the GBIF data-clustering feature work? - GBIF Data Blog
- Examples
- how to search for it: this is all plantnet observations that are part of a cluster Occurrence search (“has related records”)
- observation that is part of a cluster Occurrence 4011692074
- Darwin Core has
associatedOccurrencesfor kinda similar ones, incl. by parsing the descriptions for mentions etc.: Darwin Core Quick Reference Guide - Darwin Core- not used for duplicate detection as of the awesome blog post above from 2021-11-04
- some people use it in other ways: https://discourse.gbif.org/t/differences-in-use-between-associatedoccurrences-and-associatedorganisms/2561/2
- I can’t find how to access it from the API
- Their main threat model is the same herbarium speciment scanned and put into different collections, or the same plant photo uploaded to two different platforms (e.g. pNet + iNat) ending in GBIF twice
Refs
-
Has clustering of records that appear to be similar:
- Identifying potentially related records - How does the GBIF data-clustering feature work? - GBIF Data Blog
- very thorough
- downsides
- clustering compares only across datasets, not within the same one!
- runs once every few weeks
- Biodiversity Data Use (less cool page mentioning duplications)
- More theory on this: New data-clustering feature aims to improve data quality and reveal cross-dataset connections
- Occurrence search (“has related records”)
- Example: Occurrence 4036191318
- in API:
- New data-clustering feature aims to improve data quality and reveal cross-dataset connections
matching similar entries in individual fields across different datasets
- https://api.gbif.org/v1/occurrence/1141981356/experimental/related
- vanilla
curl https://api.gbif.org/v1/occurrence/4011664186 | jq -C | lesshasisInClusterbut nothing more
- New data-clustering feature aims to improve data quality and reveal cross-dataset connections
- Identifying potentially related records - How does the GBIF data-clustering feature work? - GBIF Data Blog
-
GBIF has
associatedOccurrences- Darwin Core Quick Reference Guide - Darwin Core
- not yet used in clustering
- parses descriptions etc. for links
-
Darwin Core Resource Relationship – Extension darwin core bit about relationships between records docu
-
Duplicate occurrence records - Data Publishing - GBIF community forum
- user distinguishes three types of duplicates: exact, strict, relaxed
- discussions of using bash/cli magic to parse occurrences.txt to find them,
- ref. A data cleaner’s cookbook - Content 1
- BASHing data: Partial duplicates
- all with a more record linking vibe
-
I’m not aware of any backend or external packages (e.g. in R or Python) that can tidy a Darwin Core dataset
-
Fortunately or unfortunately, Darwin Core datasets are complex beasts that don’t lend themselves to automated checking and fixing. For this reason people (not backend routines) are the best Darwin Core data cleaners 4. The code recipes 2 I use are freely available on the Web and I (and now others) are happy to train others in their use.
-
Duplicate observations across datasets - GBIF community forum
-
Something that I often hear repeated on iNaturalist and BugGuide is that posting the same observation on both platforms results in the observation being ingested twice by GBIF.
- TL;DR posted twice, not found as duplicate because had no location info on one of the platforms
-
Random
- Developer Blog: “I noticed that the GBIF data portal has fewer records than it used to – what happened?” about removing dulicates from GBIF in 2012
GBIF/iNat
Looking for observations with links in description
- creeping thistle from Norfolk County, ON, Canada on July 12, 2019 at 08:44 AM by Jeremy Hussell. Same plants as in this previous observation: https://www.inaturalist.org/observations/28646599 · iNaturalist == Occurrence 3005247358
- “occurrence remarks” in GBIF are iNat’s “description”
Random / fun
- https://community.openstreetmap.org/t/semi-automated-tree-additions/102197/57?page=4 openstreetmap automatically adding trees and needing deduplication
Next steps
Look for GBIF/iNat/plantnet repos on Github and look their mentions of duplicates
-
Day 1812 (17 Dec 2023)
Obsidian has an Outline core plugin
Core plugins -> Outline!
Poetry add spacy model to requirements
Usually models are added as
python -m spacy download de_core_news_smFor poetryi: python - How to download spaCy models in a Poetry managed environment - Stack Overflow
TL;DR: spacy models are python packages!
Get direct link to model packages here: uk · Releases · explosion/spacy-models
Add to poetry tool dependencies in pyproject.toml:
[tool.poetry.dependencies] python = "^3.10" # ... uk_core_news_sm = {url = "https://github.com/explosion/spacy-models/releases/download/uk_core_news_sm-3.7.0/uk_core_news_sm-3.7.0-py3-none-any.whl"}add through poetry CLI:
poetry add https://github.com/explosion/spacy-models/releases/download/uk_core_news_sm-3.7.0/uk_core_news_sm-3.7.0-py3-none-any.whl
-
Day 1810 (15 Dec 2023)
Hierarchical tree list of running processes in linux
I’d usually do
ps aux.The
pscommand can also do:ps -ef --forest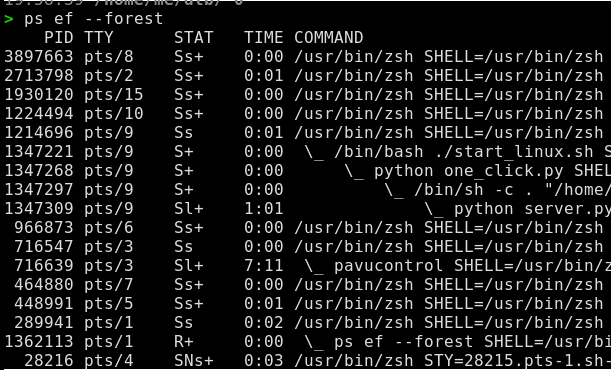
But the best one is
pstree1 from thepsmiscpackage.pstree # or pstree -i # for processids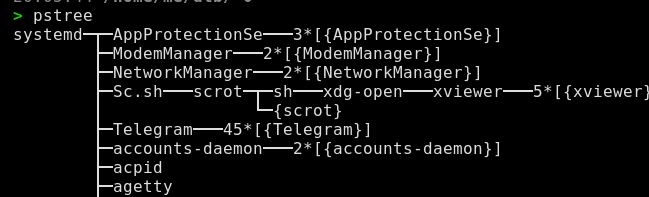
-
Day 1809 (14 Dec 2023)
Asking ChatGPT to make its own prompts is a superpower
Used it 3 times already and it’s awesome.
— If I’ll want your help with this in the future, which prompt can I use to describe the task I need and the output type to get a graph in the format and complexity level of the one you just generated? How can I concisely describe it to you so that no clarifications will be needed and you can just give me the answer?
— “Create an abstract graph structure for a story involving multiple characters with interconnected goals, challenges, outcomes, and a moral lesson. The graph should use nodes and relationships similar to the format of the ‘Adventurer and Guide’ mountain climbing story you previously created, with entities, goals, challenges, interactions, outcomes, and a moral lesson. The structure should reflect underlying themes rather than the literal narrative, similar to the complexity and abstraction level of the previous example.”
After more clarifications:
“Generate an abstract graph structure for a narrative involving multiple animate characters. The graph should include nodes for entities, goals, challenges, interactions, outcomes, and moral lessons. Each node should abstractly represent the core elements of the story, focusing on thematic and moral aspects rather than the literal narrative. The format should be similar to a semantic web ontology, emphasizing relationships and abstract concepts. Please provide the graph in a Python dictionary format, with complexity and depth akin to an advanced semantic network.”
Context: 231024-1704 Master thesis task CBT
Masterarbeit benchmark task for Russian-Ukrainian interference
-
231213-1710 Ukrainska Pravda dataset#Can I also use this to generate tasks for the UA-CBT ( 231024-1704 Master thesis task CBT ) task? : both 3.5 and 4 during summarization use definitely Russian-inspired phrases :
-
In the news summarization bit, it magically changed Євген->Евген (https://chat.openai.com/share/2f6cf1f3-caf5-4e55-9c1b-3dbd6b73ba29)
-
Та подивись, баране, як я виглядаю з цим стильним сурдутом1
Вертить хвостиком і крутить рогами. Цап робить враження2.
Old links
(from 230928-1630 Ideas for Ukrainian LM eval tasks)
- СЛОВОВЖИВАННЯ | Горох — українські словники
- відноситися - Антисуржик. Словник «українського» суржика
- Словник-антисуржик онлайн
- Антисуржик (словник) - Русский/украинский язык, культура - Форум Днепродзержинск-Каменское
EXCELLENT! Мова – не калька: словник української мови - Тарас Береза - Тека авторів - Чтиво- parse -> estimate frequency -> include only the most frequent?
- A lot of the examples there are let’s say questionable to my central-Ukrainian ear
- голий -> “У костюмі (в одежі) Адама і Єви; у чому мати [на світ] народила.” alrighty then
- Льотчик -> летун
- Ліберія -> “Вільна країна” I’m done
- I want RU interference (!= суржик); I want RU interference (!= стилістика)
- Some kind of filtering is definitely needed. Could be as easy as putting “1” in rows of a spreadsheet
- https://chtyvo.org.ua/authors/Tykhyi_Oleksii/Slovnyk_movnykh_pokruchiv.pdf
- Суржиково-український словник
- has really nice intro!
- Українське життя в Севастополi Юрій Гнаткевич СЛОВНИК-АНТИСУРЖИК ^ff5ccc
- Frame as multiple-choice task! Or boolean? Or “Is this a correct sentence”?
- I really like this: `“Цей студент [взявся за/почав] дослідження важкої теми.”
- For fun, here’s ChatGPT lying about prefixes: https://chat.openai.com/share/0eda9061-d2cf-46bc-ad45-38cc6e58934a
- False friends!
- Here’s an itemized list: Фальшиві друзі перекладача — Вікіпедія
- сир/сыр, неділя/неделя/…
- False Friends of the Slavist/Russian-Ukrainian - Wikibooks, open books for an open world
- ChatGPT ideas:
-
On the semantic front, exploit polysemy and homonymy differences. Formulate sentences with words that have multiple meanings in Russian, but those meanings have distinct equivalents in Ukrainian. This will challenge the model to accurately discern the intended sense based on context.
More ideas
Using correct English spelling of cities etc!
-