serhii.net
In the middle of the desert you can say anything you want
-
Day 2689 (13 May 2026)
Borda count
- Borda count - Wikipedia is a way to fairly rank, rating = number of candidates below them in ranking
- Originally for voting
- Used in IR to aggregate ratings and benchmarking models on tasks w/ different metrics
- First seen in [2510.20508] Assessing the Political Fairness of Multilingual LLMs: A Case Study based on a 21-way Multiparallel EuroParl Dataset
- BLEU variants not comparable across language pairs so used BC to rank
Related: Likert scale
- Borda count - Wikipedia is a way to fairly rank, rating = number of candidates below them in ranking
-
Day 2655 (09 Apr 2026)
xh notes
ducaale/xh: Friendly and fast tool for sending HTTP requests o
Shorthand
# from README xh http://localhost:3000/users # resolves to http://localhost:3000/users xh localhost:3000/users # resolves to http://localhost:3000/users xh :3000/users # resolves to http://localhost:3000/users xh :/users # resolves to http://localhost:80/users xh example.com # resolves to http://example.com xh ://example.com # resolves to http://example.com
Convert enum to dict in python
python - How to make a dict from an enum? - Stack Overflow
# Source - https://stackoverflow.com/a/60451617 # Posted by Chris Doyle # Retrieved 2026-04-09, License - CC BY-SA 4.0 from enum import Enum class Shake(Enum): VANILLA = "vanilla" CHOCOLATE = "choc" COOKIES = "cookie" MINT = "mint" dct = {i.name: i.value for i in Shake} print(dct)
-
Day 2647 (01 Apr 2026)
NiceGUI notes
NiceGUI is freaking awesome.
-
Resources
- NiceGUI Documentation that leads to nicegui/examples at main · zauberzeug/nicegui and is the most useful examples I’ve seen in any python project ever.
- There’s a FAQs · zauberzeug/nicegui Wiki that I found far too late
- Has bits about performance, long-running functions etc.
-
Useful examples
- search_as_you_type for updating a table based on
Misc
- ui.list | NiceGUI hows very pretty complex lists with sections!
- ui.icon | NiceGUI works for icons: Material Symbols & Icons - Google Fonts
- Tooltips can contain all other elements! ui.tooltip | NiceGUI
- All inputs, labels date etc: Input | Quasar Framework
- ui.radio | NiceGUI
props('inline')for inline, remove for vertical;denseexists - ui.number | NiceGUI makes binding and processing string ui.inputs easier!
Modularization
- Modularization example: nicegui/examples/modularization at main · zauberzeug/nicegui
- apirouter
- fn, class, etc.
# somewhere def create() -> None: @ui.page('/a') def page_a(): with theme.frame('- Page A -'): message('Page A') ui.label('This page is defined in a function.') from somewhere import create # Example 2: use a function to move the whole page creation into a separate file # in main.py function_example.create()Slots
OK I think I got it! In e.g. Select | Quasar Framework look for “slots” then you can use them thus1:
sel = ui.select( list(items), value=item, ) with sel.add_slot("after"): ui.button(icon="description").props("flat no-caps").on( "click", lambda e: ui.navigate.to(f"/bp/{whatever}"), )Table magic
table = ui.table()#... with table.add_slot("body-cell-ColumnName"): with table.cell("ColumnName"): # button w/ cell text ui.button().props(""" :innerHTML="props.value" """).on( "click", js_handler="() => emit(props.row.SomeColumnName)", handler=lambda e: ui.navigate.to(f"/sth/{e.args}"), # e.args is cell content ) # conditionals .props(""" flat no-caps :label="props.value !== 'N/A' ? props.value : ''" """) # tooltips! with table.add_slot("body-cell-ISIN"): with table.cell("ISIN"): with ui.row().classes("items-stretch gap-0"): u ui.label().props(':textContent="props.value"') ui.tooltip().props(""" center left :innerHTML="props.row.bp_link ? props.row.Basisprospekt : ''" :target="props.row.bp_link ? true : false" """)Link
… with button
with ui.link(target="/sd"): ui.button("Show", icon="description")… without underline
with ui.link(target=target_link).classes("no-underline"): ui.item_label("look ma no underline!")Multiple badges
Ref: Badge: Floating - Quasar Playground but that’s quasar-heavy. Strangely not mentioned in the official quasar docs either. After playing with this this is the python solution:
# remove the floating prop and add one of these classes. # Removing the prop is useful if using e.g. both top-left and top-right # then they are on an identicafl height ui.badge(faiss_dist_str, color="light-blue-10").props( # "floating" ).classes("absolute-top-left")Styling
- Quasar header classes: Typography | Quasar Framework
Events
ui.table(rows=rows).props("flat bordered").on( "row-click", lambda e: ui.navigate.to(f"/pr/{e.args[1]['ISIN']}"), )The row-click event comes from quasar: https://quasar.dev/vue-components/table#qtable-api
APIs
-
ui.run(..., fastapi_docs=True)to make documentation available -
nicegui/examples/api_requests/main.py at main · zauberzeug/nicegui
async def show_new_quote(): async with httpx.AsyncClient() as client: response = await client.get('https://zenquotes.io/api/quotes') quote = random.choice(response.json())['q'] label.text = f'“{quote}”'Snippets
Debugging long-running functions
From the FAQ:
# (..) app.on_startup(setup) # def setup(): # if CFG.debug_mode: import asyncio loop = asyncio.get_running_loop() loop.set_debug(True) loop.slow_callback_duration = 0.05Uploading files
ui.upload( auto_upload=True, on_upload=lambda e: handle_upload(e) ).classes("max-w-full") async def handle_upload(e: events.UploadEventArguments): with tempfile.NamedTemporaryFile(delete=False, prefix="uns") as tmp: save_path = Path(tmp.name) await e.file.save(save_path) return save_pathBonus: FastAPI File upload
- python - How to Upload File using FastAPI? - Stack Overflow has many diff ways
- Building a Secure and Efficient File Upload API in FastAPI | Mahdi Abu Tafish is a deep dive
- blocking operations, security, etc.
Smallest text ever
- https://tailwindcss.com/docs/font-size says you can do
<p class="text-[14px] ..."> Lorem ipsum dolor sit amet...</p>iftext-xsetc. is not enough. - text-xs is 0.75rem ->
.classes(text-[0.6rem])
Dynamically load tab content
Ugly but this is the concept, TODO later make it clearer
tabs.on_value_change( lambda e: load_bad_datasets() if e.value == "show_bad_datasets" else None ) ui.tab("show_info", label="Info", icon="info") ui.tab("show_bad_datasets", label="Bad Datasets", icon="error") with ui.tab_panels(tabs, value="show_info").classes("w-full"): with ui.tab_panel("show_info"): p_info() with ui.tab_panel("show_bad_datasets"): bds = None async def load_bad_datasets(): await asyncio.sleep(2) bad_ds = await get_bad_datasets() bds = show_pretty_json(bad_ds).classes("text-[8pt]")TODO
Focus
element.run_method('focus')focuses the element, I could connect this to ui.keyboard | NiceGUI to do nice keyboard-centric focus of important fields!
Ref: element.run_method(‘focus’) not working · Issue #1092 · zauberzeug/nicegui (not documented elsewhere I could find)
Elsewhere
Validating in real time based on a pydantic BaseModel!: Real-Time Form Validation in Python Using Pydantic | by Aman Deep | Medium
Async hell
Using a variable globally defined outside a function creates issues. E.g. globally WHAT=‘ever’ and then inside a function. TODO better description.
-
-
Day 2646 (31 Mar 2026)
Translating pattern with LLMs
I know enough German to judge but not enough to write grammatically myself, and this is a pattern I don’t want to forget.

This is SO MUCH BETTER than anything else I’ve used for this! For very short snippets it’s golden
-
Day 2645 (30 Mar 2026)
LaTeX paper checklist
For the main file, see: 240116-1701 LaTeX best practices
Camera-ready checklist
- Enable reviewing mode in Overleaf
- Change package options
[review/final]etc. - Authors emails, names, order correct?
- Acknowledgements present and uncommented?
- Anonimity: uncensor names+URIs
- Are acknowledgements, references, appendices a) allowed, b) part of page limit?
- COMPRESSION: reconsider all hacks if you got more space for the camera-ready version
\setlength{\itemsep}{0pt} \setlength{\parskip}{0pt}and friends\setlength{\belowcaptionskip}{0}\setlength{\abovecaptionskip}{10pt}1 <- default values\looseness-1- Any paragraphs to un-merge for readability?
- Go through pre-flight checklist below
- Manually check ALL review-mode changes at the end!
Pre-flight checklist
- Ask LLMs to proofread! THEN do the steps below.
- Acknowledgements, references, appendices: a) allowed, b) count towards page limit?
- In which order?
- Anonymity: acknowledgements, again!
- Search for
TODOs in the text! - Consistency:
- When to use single/double quotes (quotes), when emphasis (foreign languages?)
- terminology?
- (including in captions and inside figures (labels, titles!))
- Table headers’ variables and names are easy to forget to update!
- Tables
- Did any footnote markers get deleted when pasting new data in tables?
- Adding
\bottomruleshelps if distance between table and caption too small
- Titles
- Title Case where needed (paper title + sections)
- Break the paper title in some pretty way
\mboxto avoid breaks,\-within word to mark break words
- Citations+references
- before periods and footnotes
- always w/ NBSP
- Double-check each reference, including inside table/figure captions!
- citep=cite, citet if subject, citealp in parentheses
- Don’t forget multiple citations
exist [1,3]!
- Commands/macros
- Search for
\TODOand any custom commands/macros you created - Check the spacing after any custom macros
- Search for
- Typography bits
- 231206-1501 Hyphens vs dashes vs en-dash em-dash minus etc
- Smart Quotes: Either `x’ and ``x’’ or
\enquote{}everywhere - Large Numbers: Write large numbers as 54{,}000.99
~is\textasciitilde: check any estimate numbers (~50%)!%is\%; check all percentages!\is\textbackslash- underscores, subscripts, superscripts are dangerous
- Avoid footnotes after numbers
- does minted caption use the same font as the rest?
-,--,---are the safest — look and remove pasted UTF8 ones
- NBSP (search and manually check each!)
- Citations,
\references (Figure~\ref{fig:somefig})- Actually
\autoref!
- Actually
- TODO
- Citations,
- Look at logs!
Things that can go wrong with content
- Read through all analysis and tables, make sure the data makes sense, the analysis/results match the numbers in the tables, the plots and the tables match to each other.
- Make sure whatever you used to generate plots and tables used the exact same data!
-
Day 2643 (27 Mar 2026)
Tiny PRF demo program
I wrote this debugging some metrics, bad code but I don’t want it to die. Shows formulas for Precision/Recall/F-Score based on number of TP TN FP FN.
Depends only on rich, runnable w/ uv through 250128-2149 Using uv as shebang line.
Usage:
uv run prftset.py tp tn fp fn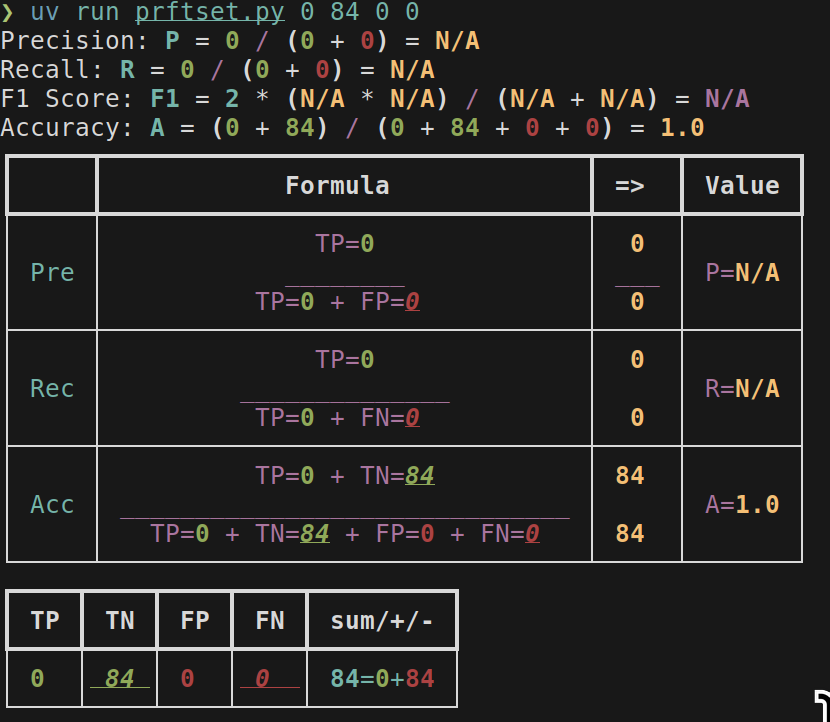
# /// script # dependencies = [ # "rich", # "pdbpp", # ви цього варті # ] # /// from rich import print from rich.layout import Layout from rich.table import Table import argparse def get_scores(tp, tn, fp, fn) -> dict[str, int | float | str | None]: """Calculate precision, recall, and F1 score from true positives, true negatives, false positives, and false negatives.""" precision = tp / (tp + fp) if (tp + fp) > 0 else None recall = tp / (tp + fn) if (tp + fn) > 0 else None f1_score = ( 2 * (precision * recall) / (precision + recall) if precision is not None and recall is not None and (precision + recall) > 0 else None ) accuracy = (tp + tn) / (tp + tn + fp + fn) if (tp + tn + fp + fn) > 0 else None f_precision = float(f"{precision:.3f}") if precision is not None else "N/A" f_recall = float(f"{recall:.3f}") if recall is not None else "N/A" f_f1_score = float(f"{f1_score:.3f}") if f1_score is not None else "N/A" total_ds = tp + tn + fp + fn res = { "TP": tp, "TN": tn, "FP": fp, "FN": fn, "total": total_ds, "P ": f_precision, "R ": f_recall, "F ": f_f1_score, "A ": float(f"{accuracy:.3f}") if accuracy is not None else "N/A", # "A ": accuracy, } return res def use_table(tp, tn, fp, fn, precision, recall, accuracy): total = tp + tn + fp + fn total_positive = tp + fn total_negative = tn + fp table_tn = Table() table_tn.add_column("TP", justify="center", style="green") table_tn.add_column("TN", justify="center", style="green underline italic") table_tn.add_column("FP", justify="center", style="red") table_tn.add_column("FN", justify="center", style="red underline italic") table_tn.add_column("sum/+/-", justify="right", style="cyan") table_tn.add_row( f"[bold green]{str(tp)}[/bold green]", f"[bold green]{str(tn)}[/bold green]", f"[bold red]{str(fp)}[/bold red]", f"[bold red]{str(fn)}[/bold red]", f"[bold cyan]{str(total)}[/bold cyan]=" + f"[bold green]{str(total_positive)}[/bold green]+" + f"[bold red]{str(total_negative)}[/bold red]", ) table = Table() table.add_column("", justify="right", style="cyan", no_wrap=True) table.add_column("Formula", justify="center", style="magenta") table.add_column("=>", justify="center", style="magenta") table.add_column("Value", justify="center", style="magenta") table.add_row( "", f"TP=[bold green]{str(tp)}[/bold green]", f"[bold yellow]{str(tp)}[/bold yellow]", "", ) table.add_row( "Pre", "_" * (len(str(tp)) + len(str(fp)) + 6), "___", f"P=[bold yellow]{precision}[/bold yellow]", ) table.add_row( "", f"TP=[bold green]{str(tp)}[/bold green] + FP=[bold red underline italic]{str(fp)}[/bold red underline italic]", f"[bold yellow]{str((tp + fp))}[/bold yellow]", "", ) table.add_section() table.add_row( "", f"TP=[bold green]{str(tp)}[/bold green]", f"[bold yellow]{str(tp)}[/bold yellow]", "", ) table.add_row("Rec", "______________", "", f"R=[bold yellow]{recall}[/bold yellow]") table.add_row( "", f"TP=[bold green]{str(tp)}[/bold green] + FN=[bold red underline italic]{str(fn)}[/bold red underline italic]", f"[bold yellow]{str((tp + fn))}[/bold yellow]", "", ) table.add_section() # Accuracy table.add_row( "", f"TP=[bold green]{str(tp)}[/bold green] + TN=[bold green underline italic]{str(tn)}[/bold green underline italic]", f"[bold yellow]{str((tp + tn))}[/bold yellow]", "", ) table.add_row( "Acc", "______________________________", "", f"A=[bold yellow]{accuracy}[/bold yellow]", ) table.add_row( "", f"TP=[bold green]{str(tp)}[/bold green] + TN=[bold green underline italic]{str(tn)}[/bold green underline italic] + FP=[bold red]{str(fp)}[/bold red] + FN=[bold red underline italic]{str(fn)}[/bold red underline italic]", f"[bold yellow]{str((tp + tn + fp + fn))}[/bold yellow]", "", ) print(table) print(table_tn) def pretty_scores(scores: dict[str, int | float | str | None], draw=True): tp, tn, fp, fn = scores["TP"], scores["TN"], scores["FP"], scores["FN"] precision, recall, f1_score = scores["P "], scores["R "], scores["F "] accuracy = scores["A "] # print( f"| TP: {scores['TP']}, TN: {scores['TN']}, FP: {scores['FP']}, FN: {scores['FN']} | ") # print( # f"| Precision: {scores['P ']}, Recall: {scores['R ']}, F1 Score: {scores['F ']} |" # ) print( f"Precision: [bold cyan]P[/bold cyan] = [bold green]{tp}[/bold green] / ([bold green]{tp}[/bold green] + [bold red]{fp}[/bold red]) = [bold yellow]{precision}[/bold yellow]" ) print( f"Recall: [bold cyan]R[/bold cyan] = [bold green]{tp}[/bold green] / ([bold green]{tp}[/bold green] + [bold red]{fn}[/bold red]) = [bold yellow]{recall}[/bold yellow]" ) print( f"F1 Score: [bold cyan]F1[/bold cyan] = 2 * ([bold yellow]{precision}[/bold yellow] * [bold yellow]{recall}[/bold yellow]) / ([bold yellow]{precision}[/bold yellow] + [bold yellow]{recall}[/bold yellow]) = [bold magenta]{f1_score}[/bold magenta]" ) print( f"Accuracy: [bold cyan]A[/bold cyan] = ([bold green]{tp}[/bold green] + [bold green]{tn}[/bold green]) / ([bold green]{tp}[/bold green] + [bold green]{tn}[/bold green] + [bold red]{fp}[/bold red] + [bold red]{fn}[/bold red]) = [bold yellow]{scores['A ']}[/bold yellow]" ) # use_layout(tp, tn, fp, fn, precision, recall) use_table(tp, tn, fp, fn, precision, recall, accuracy) def main(): args = parse_args() # Example usage # tp = 100 # tn = 50 # fp = 10 # fn = 5 tp = args.tp tn = args.tn fp = args.fp fn = args.fn scores = get_scores(tp, tn, fp, fn) pretty_scores(scores) def parse_args(): parser = argparse.ArgumentParser( description="Calculate precision, recall, and F1 score." ) # use positional arguments for tp, tn, fp, fn parser.add_argument("tp", type=int, help="True Positives", default=0) parser.add_argument("tn", type=int, help="True Negatives", default=0) parser.add_argument("fp", type=int, help="False Positives", default=0) parser.add_argument("fn", type=int, help="False Negatives", default=0) # parser.add_argument("--tp", type=int, required=True, help="True Positives") # parser.add_argument("--tn", type=int, required=True, help="True Negatives") # parser.add_argument("--fp", type=int, required=True, help="False Positives") # parser.add_argument("--fn", type=int, required=True, help="False Negatives") return parser.parse_args() if __name__ == "__main__": main()
-
Day 2605 (17 Feb 2026)
Killing Kubernetes pods without breaking stuff Rancher
- To force-kill pods w/o breaking k8s:
kubectl delete pod <> --now
Ty KM (https://github.com/kkmarv) for the following, quoting verbatim:
The expected behaviour of
kubectl deleteheavily depends on its arguments. There are 4 possible but wrongly documented options. I’ve tried to compile different sources into this list:kubectl delete pod <>will first send a SIGTERM, then a SIGKILL after X seconds (depends on the gracePeriods set by your pod)kubectl delete pod <> --grace-period=X(X>0) will first send a SIGTERM, then a SIGKILL after X secskubectl delete pod <> --nowis equivalent tokubectl delete pod <> --grace-period=1
There’s also
--force
Where things are possible to go wrong. It immediately deletes the pod from etcd, which will NOT kill the pod. It will too wait for the grace period before sending a SIGKILL. But even then it is not guaranteed that resources will be freed. There is even a warning inkubectl delete --helpabout this. Only use this when there is no other way to kill a pod.The force flag also allows to specify
--grace-period=0which will simply default to the grace period defined by the pod, effectively doing nothing since this is also the default behaviour.
- To force-kill pods w/o breaking k8s:
-
Day 2602 (14 Feb 2026)
Passing complex CLI params to Pydantic settings
Settings Management - Pydantic Validation is nice but doesn’t cover everything.
Passing
Nonethrough CLI- Settings Management - Pydantic Validation
Noneby default b/ccli_avoid_jsonis the default,[]
it will default to “null” if
cli_avoid_jsonisFalse, and “None” ifcli_avoid_jsonisTrue.Fun fact, works inside complex nested JSON flags as well.
Passing complex JSON-like fields incl. tuples
# Assume this class MySettingsClass(BaseSettings): I_am_a_list_of_tuples: list[tuple[str, str, str | None]] = Field( default=FILE_PAIRS, validation_alias=AliasChoices("fp", "file_pairs") ) FILE_PAIRS = [ ( "infer_doc_simplecriteria/pred_doc_simplecriteria.json", "merge_gold_simplecriteria/gold_simplecriteria.json", ), ( "file2-1", "file2-2", ), ]# Passing as a list of lists parses as a tuple # if done wrong the tuple is parsed as a list of strings uv run thing --I-am-a-list-of-tuples \ '"merge_gold_simplecriteria/gold_simplecriteria.json", "infer_doc_simplecriteria/pred_doc_simplecriteria.json"'
-
Day 2600 (12 Feb 2026)
Pydantic dumping model in json mode with serializable objects
TL;DR
pydanticmodel.model_dump(mode=>"json")Serialization - Pydantic Validation
To dump a Pydantic model to a jsonable dict (that later might be part of another dict that will be dumped to disc through
json.dump[s](..)):settings.model_dump() >>> {'ds_pred_path': PosixPath('/home/sh/whatever')} # json.dump... json.dumps(settings.model_dump()) >>> TypeError: Object of type PosixPath is not JSON serializable json.dumps(settings.model_dump(mode="json")) # works!