serhii.net
In the middle of the desert you can say anything you want
-
Day 1872 (15 Feb 2024)
DBnary is a cool place I should look into further
Dbnary – Wiktionary as Linguistic Linked Open Data
It’s something something Wiktionary something, but more than that I think. “RDF multilingual lexical resource”.
Includes Ukrainian, though not in the dashboard pages: Dashboard – Dbnary.
Learned about it in the context of 240215-2136 LMentry improving words and sentences by frequency, linked by dmklinger/ukrainian: English to Ukrainian dictionary.
Huggingface Hub full dataset card metadata
The HF Hub dataset UI allows to set only six fields in the metadata, the full fields can be set through the YAML it generates. Here’s the full list (hub-docs/datasetcard.md at main · huggingface/hub-docs):
--- # Example metadata to be added to a dataset card. # Full dataset card template at https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md language: - {lang_0} # Example: fr - {lang_1} # Example: en license: {license} # Example: apache-2.0 or any license from https://hf.co/docs/hub/repositories-licenses license_name: {license_name} # If license = other (license not in https://hf.co/docs/hub/repositories-licenses), specify an id for it here, like `my-license-1.0`. license_link: {license_link} # If license = other, specify "LICENSE" or "LICENSE.md" to link to a file of that name inside the repo, or a URL to a remote file. license_details: {license_details} # Legacy, textual description of a custom license. tags: - {tag_0} # Example: audio - {tag_1} # Example: bio - {tag_2} # Example: natural-language-understanding - {tag_3} # Example: birds-classification annotations_creators: - {creator} # Example: crowdsourced, found, expert-generated, machine-generated language_creators: - {creator} # Example: crowdsourced, ... language_details: - {bcp47_lang_0} # Example: fr-FR - {bcp47_lang_1} # Example: en-US pretty_name: {pretty_name} # Example: SQuAD size_categories: - {number_of_elements_in_dataset} # Example: n<1K, 100K<n<1M, … source_datasets: - {source_dataset_0} # Example: wikipedia - {source_dataset_1} # Example: laion/laion-2b task_categories: # Full list at https://github.com/huggingface/huggingface.js/blob/main/packages/tasks/src/pipelines.ts - {task_0} # Example: question-answering - {task_1} # Example: image-classification task_ids: - {subtask_0} # Example: extractive-qa - {subtask_1} # Example: multi-class-image-classification paperswithcode_id: {paperswithcode_id} # Dataset id on PapersWithCode (from the URL). Example for SQuAD: squad configs: # Optional for datasets with multiple configurations like glue. - {config_0} # Example for glue: sst2 - {config_1} # Example for glue: cola # Optional. This part can be used to store the feature types and size of the dataset to be used in python. This can be automatically generated using the datasets-cli. dataset_info: features: - name: {feature_name_0} # Example: id dtype: {feature_dtype_0} # Example: int32 - name: {feature_name_1} # Example: text dtype: {feature_dtype_1} # Example: string - name: {feature_name_2} # Example: image dtype: {feature_dtype_2} # Example: image # Example for SQuAD: # - name: id # dtype: string # - name: title # dtype: string # - name: context # dtype: string # - name: question # dtype: string # - name: answers # sequence: # - name: text # dtype: string # - name: answer_start # dtype: int32 config_name: {config_name} # Example for glue: sst2 splits: - name: {split_name_0} # Example: train num_bytes: {split_num_bytes_0} # Example for SQuAD: 79317110 num_examples: {split_num_examples_0} # Example for SQuAD: 87599 download_size: {dataset_download_size} # Example for SQuAD: 35142551 dataset_size: {dataset_size} # Example for SQuAD: 89789763 # It can also be a list of multiple configurations: # ```yaml # dataset_info: # - config_name: {config0} # features: # ... # - config_name: {config1} # features: # ... # ``` # Optional. If you want your dataset to be protected behind a gate that users have to accept to access the dataset. More info at https://huggingface.co/docs/hub/datasets-gated extra_gated_fields: - {field_name_0}: {field_type_0} # Example: Name: text - {field_name_1}: {field_type_1} # Example: Affiliation: text - {field_name_2}: {field_type_2} # Example: Email: text - {field_name_3}: {field_type_3} # Example for speech datasets: I agree to not attempt to determine the identity of speakers in this dataset: checkbox extra_gated_prompt: {extra_gated_prompt} # Example for speech datasets: By clicking on “Access repository” below, you also agree to not attempt to determine the identity of speakers in the dataset. # Optional. Add this if you want to encode a train and evaluation info in a structured way for AutoTrain or Evaluation on the Hub train-eval-index: - config: {config_name} # The dataset config name to use. Example for datasets without configs: default. Example for glue: sst2 task: {task_name} # The task category name (same as task_category). Example: question-answering task_id: {task_type} # The AutoTrain task id. Example: extractive_question_answering splits: train_split: train # The split to use for training. Example: train eval_split: validation # The split to use for evaluation. Example: test col_mapping: # The columns mapping needed to configure the task_id. # Example for extractive_question_answering: # question: question # context: context # answers: # text: text # answer_start: answer_start metrics: - type: {metric_type} # The metric id. Example: wer. Use metric id from https://hf.co/metrics name: {metric_name} # Tne metric name to be displayed. Example: Test WER --- Valid license identifiers can be found in [our docs](https://huggingface.co/docs/hub/repositories-licenses). For the full dataset card template, see: [datasetcard_template.md file](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md).Found this in their docu: Sharing your dataset — datasets 1.8.0 documentation
Full MD template : huggingface_hub/src/huggingface_hub/templates/datasetcard_template.md at main · huggingface/huggingface_hub EDIT: oh nice “import dataset card template” is an option in the GUI and it works!
-
Day 1867 (10 Feb 2024)
CBT Task filtering instructions (Masterarbeit)
(Context: 240202-1312 Human baselines creation for Masterarbeit / 231024-1704 Master thesis task CBT / 240202-1806 CBT Story proofreading for Masterarbeit)
Ціль: відсортувати добрі і погані тестові завдання по казкам. Погані казки - ті, де проблеми з варіантами відповіді.
Контекст: автоматично створюю казки, а потім тестові завдання по цим казкам, щоб перевіряти наскільки добре ШІ може розуміти суть казок (and by extension - мови). Для цього треба перевірити, чи створені казки та тести по ним взагалі можливо вирішити (і це мають робити люди). Потрібно зібрати 1000 правильних тестових завдань.
Завдання: НЕ вибирати правильну відповідь (вона +/- відома), а вирішувати, чи завдання ОК чи ні.
Типове завдання:
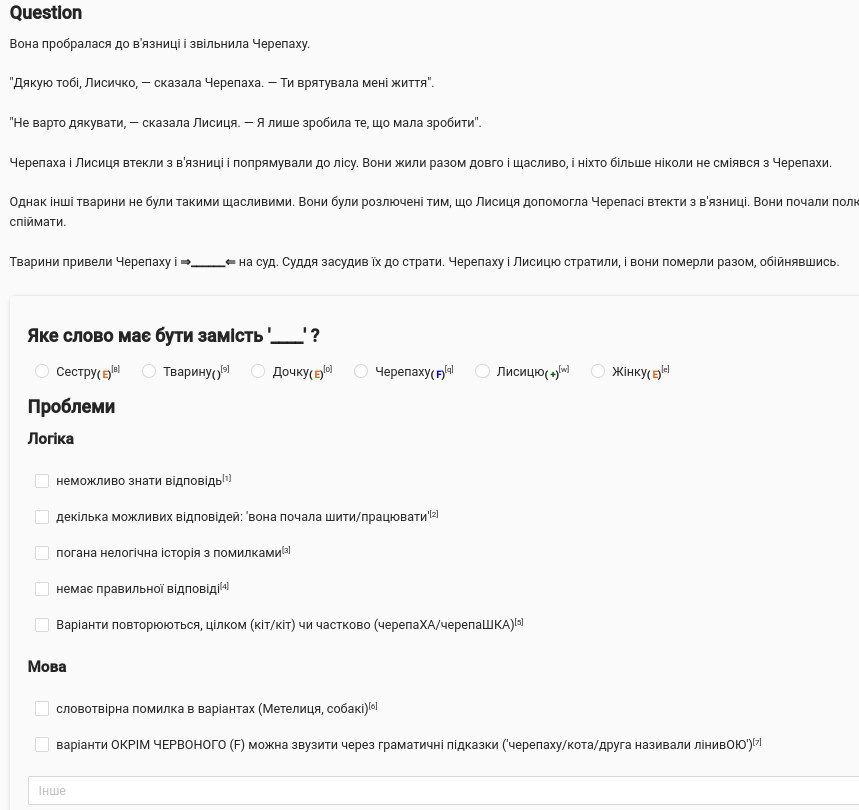
Коротко суть
Інтерфейс
- Нажимаємо на Label All Tasks:
- Клавіші зручні:
- Ctrl+Enter “зберегти і далі”
- Ctrl-Space для “пропустити”
- Для варіантів в квадратних дужках їх клавішаG
Казки
В списку казок натискаємо на label all tasks і бачимо історію з двох частин:
- context: перші 60% казки. Часто можна не читати взагалі, відповідь буде зрозумілою по другій частині
- question: останні 40% казки, і якесь слово там буде замінено на “
_____”.
Далі бачимо варіанти відповіді і проблеми.
Варіантів відповіді шість. Це різні слова які можуть бути у прочерку. Можливі три типи прочерків:
- головні герої (Коза, Черепаха, кравчиня)
- іменники (їжа, одежа)
- дієслова (пішла, вирішив)
Варіанти мають бути узгодженими з текстом. Узгоджено:
- синій плащ, черепаха сміялась Не узгоджено:
- весела кіт, орел полетіла
Проблеми
Переважна більшість завдань ОК, але не всі.
Якщо є питання, кидайте в чат скрін та номер завдання.
Воно в URI:
Проблеми в завданні можуть бути логічні і мовні.
Логічні проблеми
- відповідь знати неможливо
- текст до і після не дає достатньо інформації щоб вибрати правильний варіант
- ми тупо не знаємо до кого вони пішли додому, кота чи черепахи, і не можемо дізнатися. Але це різні істоти
- декілька відповідей правильні
-
Лев сказав Черепасі, що йому потрібен піджак. Черепаха взялася за роботу/шиття.
-
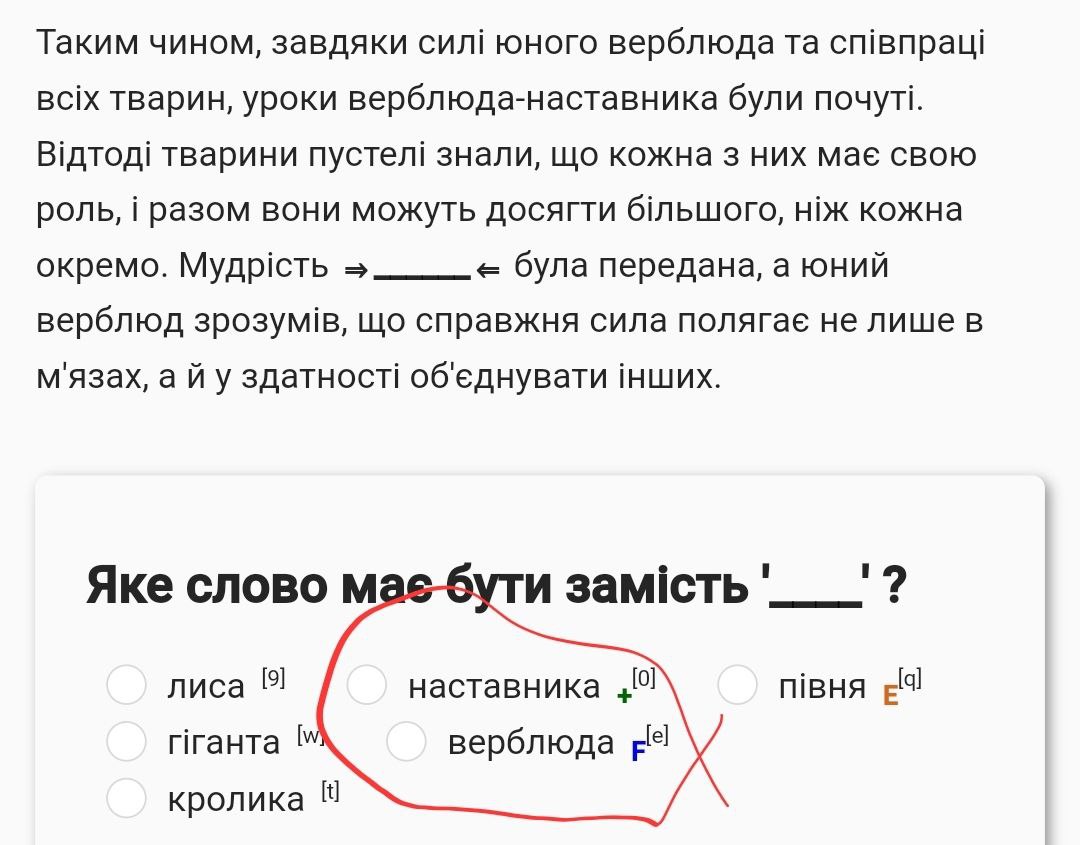
- Декілька варіантів підходять тому ж поняттю. Він почав шити+працювати, він Кіт+підозрюваний.
- Виключення:
- тварина/звір. Якщо в варіантах є тварини і слово тварина/звір (а всі коти тварини), то критерій якщо воно натурально може бути вживано. Якщо кіт і їжак йдуть мандрувати, то писати потім кіт і звір дивно. Тобто це проблема тільки якщо можна вжити в тому реченні ці слова і воно буде ОК.
-
Невідомо – це коли ми тупо не знаємо до кого вони пішли додому, кота чи черепахи, щоб почати шити далі, і не можемо дізнатися. Але це різні істоти
- немає правильної відповіді
-
Тигр вкусив собаку. Коза/синхрофазотрон закричала від болі: “тигр, за що ти мене вкусив”.
-
- варіанти повторюються
- або один і той самий варіант двічі, або дуже схожі між собою (кіт/котик) і означають те саме
- Виключення: якщо там два різних персонажа, умовно кіт і його син котик, то все ОК.
- доконаний/недоконаний вид дієслів дублікатом не вважається (вона летіла/полетіла до свого вулика), але МОЖЕ бути “декілька правильних відповідей” (якщо контекст дозволяє обидва варіанти)
- або один і той самий варіант двічі, або дуже схожі між собою (кіт/котик) і означають те саме
Мовні проблеми
- неіснуючі слова в варіантах
-
Метелиця, собакі, …
-
- граматика в варіантах дає підказки, …
- … КРІМ дієслів
- … КРІМ варіанта відміченного F
- Наприклад, тут є підказки і це завдання некоректне:
-
черепаху/кота/метелика називали лінивОЮ
-
лисиця взяла свій кожух/сумку/їжу…
-
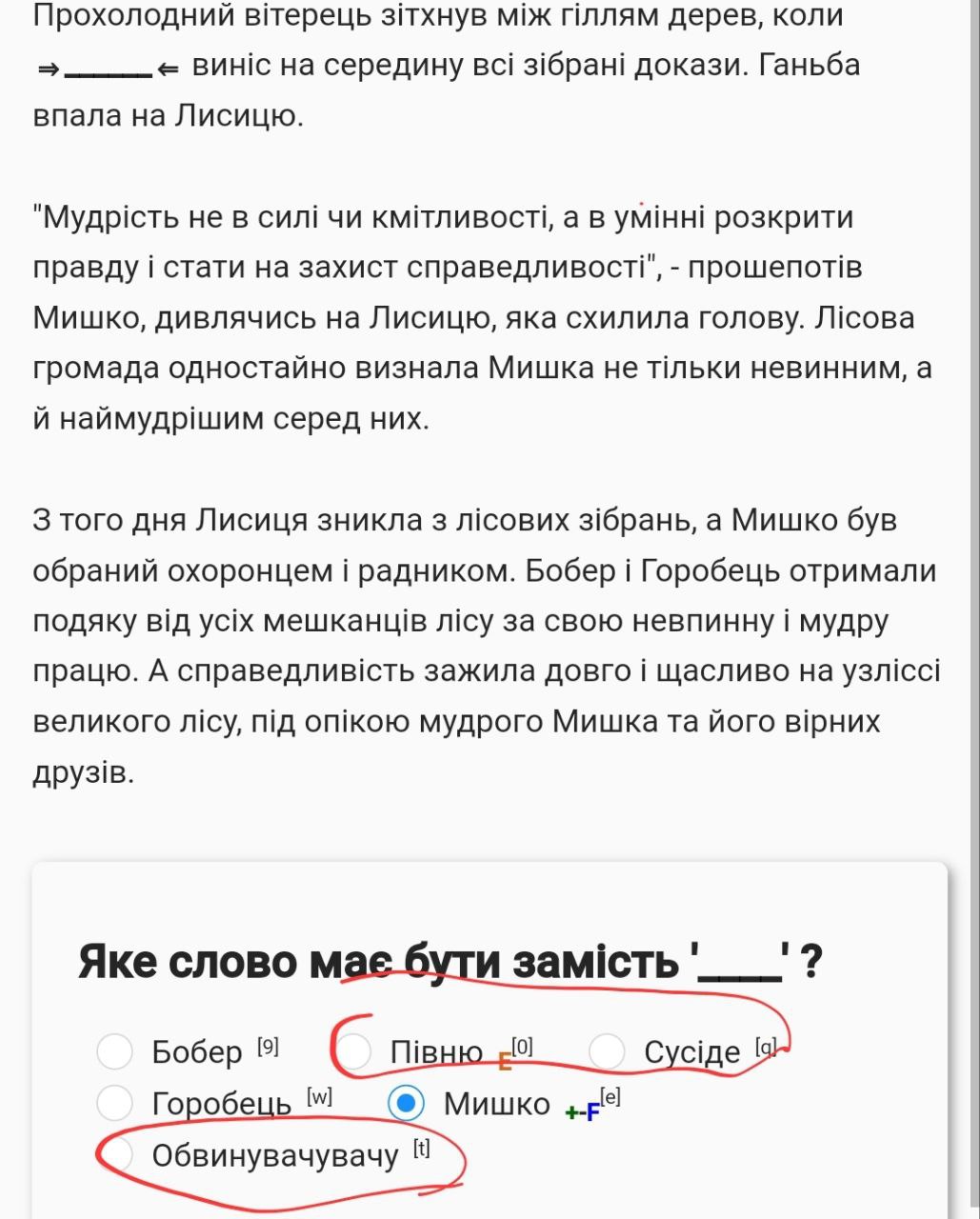
-
- А ці варіанти ОК, бо виключення
- Тут “сорочці” не підходить бо “всьому” означає чоловічий рід, АЛЕ під варіантом є літера F - тобто це норм

- Тут можна сказати, що “переслідували” очевидно не може бути перед “будувати” і відкинути варіант навіть не знаючи казки, АЛЕ це дієслова і тут все ОК

- Тут “сорочці” не підходить бо “всьому” означає чоловічий рід, АЛЕ під варіантом є літера F - тобто це норм
- ВИКЛЮЧЕННЯ: правила милозвучності (на жаль) не вважаємо граматичними проблемами.
- “з твариною/звіром” - “з звіром” граматично не ОК, але ми це ігноруємоjjj
Інші проблеми
- В деяких казках є граматичні проблеми, не шукайте спеціально, але якщо помітите – кидайте в чат з номером task де знайшли
- лише раз, в усіх інших тасках по цій історії можна не відмічати
- Щось інше, для цього поле внизу
Будь-які думки чи нотатки пишіть в полі внизу.
- Нажимаємо на Label All Tasks:
-
Day 1866 (09 Feb 2024)
Spacy has both Token.lemma_ and Token.norm_
This could have saved me a lot of time.
And contrasting it with pymorphy’s is interesting.
Pandas adding prefix to columns and making metadata out of column subsets
One can convert some column values to dict/json easily:
some_cols_subset = ['col1','col2'] df['my_metadata'] = df[some_cols_subset].apply(lambda x: to_dict(),axis=1) #to_json()To rename all cols by adding a prefix:
df[some_cols_subset].add_prefix("pr_") # now these columns are called pr_col1, pr_col2And of course both at the same time works as well:
tales[csv_md_target_key] = tales[other_cols].add_prefix(tale_metadata_prefix).apply(lambda x: x.to_dict(), axis=1) # now that column contain a dict representation of the row, and I can later pass it as metadata to log somewhere where I don't want to drag pandas dataframes to, without manually creating dictionary
Rancher setting up gitlab registry secrets
(Note to self: if you are reading this, the HSA k8s howtos exist and have screenshots to describe this exact process…)
- In the Gitlab project Settings->Repository, create a new Deploy token with at least reading access.
- username will be ~
gitlab+deploy-token-N
- username will be ~
- Rancher
- Storage->Secret, create a new secret in of type Custom. Registry Domain Name is the gitlab instance including the port, so
your.gitlab.domain.com:5050w/ the password - let’s call it
project-x-gitlab-registry
- Storage->Secret, create a new secret in of type Custom. Registry Domain Name is the gitlab instance including the port, so
- Pods
- In the config:
apiVersion: v1 kind: Pod metadata: name: lm-eval-sh namespace: project-eval-lm-ua spec: containers: - name: xxx # etc imagePullSecrets: - name: project-x-gitlab-registry
- In the Gitlab project Settings->Repository, create a new Deploy token with at least reading access.
-
Day 1865 (08 Feb 2024)
Sorting Ukrainian words in Python
How to sort Ukrainian words in Python
(Як сортувати українські слова, for the soul that may be googling this in the logical language)
Context: first seen in 231203-1745 Masterarbeit LMentry-static-UA task, where I had this:
Серед 'їжа' і 'ліжко', яке слово знаходиться ближче до літери A в алфавіті? (end of prompt on previous line) target string or answer choice index (starting on next line): ліжко>>> ' '.join(sorted(set("А а, Б б, В в, Г г, Ґ ґ, Д д, Е е, Є є, Ж ж, З з, И и, І і, Ї ї, Й й, К к, Л л, М м, Н н, О о, П п, Р р, С с, Т т, У у, Ф ф, Х х, Ц ц, Ч ч, Ш ш, Щ щ, ь, Ю ю, Я я"))) ' , Є І Ї А Б В Г Д Е Ж З И Й К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Ю Я а б в г д е ж з и й к л м н о п р с т у ф х ц ч ш щ ь ю я є і ї Ґ ґ'Aha.
How to Sort Unicode Strings Alphabetically in Python – Real Python
sudo locale-gen --lang uk Generating locales (this might take a while)... uk_UA.UTF-8... done Generation complete. > sudo apt install language-pack-uk>>> import locale >>> locale.getlocale() ('en_US', 'UTF-8') >>> locale.setlocale(locale.LC_COLLATE, "uk_UA.UTF-8") 'uk_UA.UTF-8' >>> ' '.join(sorted(set("А а, Б б, В в, Г г, Ґ ґ, Д д, Е е, Є є, Ж ж, З з, И и, І і, Ї ї, Й й, К к, Л л, М м, Н н, О о, П п, Р р, С с, Т т, У у, Ф ф, Х х, Ц ц, Ч ч, Ш ш, Щ щ, ь, Ю ю, Я я"), key=locale.strxfrm)) ' , А а Б б В в Г г Ґ ґ Д д Е е Є є Ж ж З з И и І і Ї ї Й й К к Л л М м Н н О о П п Р р С с Т т У у Ф ф Х х Ц ц Ч ч Ш ш Щ щ ь Ю ю Я я'Bonus/todo: pandas spacy Token vs str sorting
Later I’ll look into this, but a Series of spacy Tokens in two langs gets sorted differently from a series of
str.The first uses a weird order where Latin letters get mixed up with Cyrillic ones, so that English
ais close to Ukrainiana.
rich inspect
from rich import inspect # I use this often inspect(thing) # for more details inspect(thing,all=True) # (for the rest, there's `inspect(inspect)`) # BUT inspect(thing,help=True) # is the hidden gem that made me write this postThe latter shows the help provided by the library, and sometimes (e.g. pandas) it’s excellent.
(Ran the vanilla python
inspectby error and have seen the help and it was awesome, so I dug deeper.)
-
Day 1864 (07 Feb 2024)
Spacy has an attribute_ruler to force specific changes in matches
python - How to force a certain tag in spaCy? - Stack Overflow mentioned AttributeRuler · spaCy API Documentation.
Nice, more elegant than my prev. blacklist approach.
-
Day 1863 (06 Feb 2024)
Evaluating Google Gemini models in lm-eval harness for Masterarbeit
Context: 240129-1833 Writing evaluation code for my Masterarbeit
Problem: Gemini models (240202-1911 Using Google Bard to generate CBT stories for Masterarbeit) are not directly supported.
Options:
- Implement it
- Write a local proxy thing for it
- Find an existing local proxy thing
LiteLLM
Basics
from litellm import completion import os b = breakpoint messages = [{ "content": "Hello, how are you?","role": "user"}] # openai call response = completion(model="gpt-3.5-turbo", messages=messages) print(response) b() # cohere call response = completion(model="gemini-pro", messages=messages) print(response)As local proxy
litellm --model gpt3.5-turboRuns on localhost:8000
As mentioned in the README, this works:
def run_proxy(): import openai # openai v1.0.0+ client = openai.OpenAI(api_key="anything",base_url="http://0.0.0.0:8000") # set proxy to base_url # request sent to model set on litellm proxy, `litellm --model` response = client.chat.completions.create(model="gpt-3.5-turbo", messages = [ { "role": "user", "content": "this is a test request, write a short poem" } ]) print(response)For gemini-pro, I get
openai.RateLimitError: Error code: 429 - {BUT I’m generating stories in the bg as well, so that would be reasonable.
Benchmark LLMs - LM Harness, FastEval, Flask | liteLLM
export OPENAI_API_BASE=http://0.0.0.0:8000 python3 -m lm_eval \ --model openai-completions \ --model_args engine=davinci \ --task crows_pairs_english_ageI think it ignores the env variable
openai.NotFoundError: Error code: 404 - {'error': {'message': 'This is a chat model and not supported in the v1/completions endpoint. Did you mean to use v1/chat/completions?', 'type': 'invalid_request_error', 'param': 'model', 'code': None}}Feels relevant:Add Logits to OpenAI ChatCompletions model · Issue #1196 · EleutherAI/lm-evaluation-harness
This is the model implementation in lm-eval: lm-evaluation-harness/lm_eval/models/openai_completions.py at main · EleutherAI/lm-evaluation-harness
This runs but again ignores my proxy
python3 -m lm_eval --tasks low_test --model openai-chat-completions --model_args base_url=http://0.0.0.0:8000 --include ./resources --model_args model=gpt-3.5-turboAnother ignored proxy, but — oh damn! a nice value for letters in words by gpt3!
| Tasks |Version|Filter|n-shot| Metric |Value | |Stderr| |--------|------:|------|-----:|-----------|-----:|---|-----:| |low_test| 1|none | 3|exact_match|0.7222|± |0.1086|Anyway generation done, new gemini attempt, still:
litellm.llms.vertex_ai.VertexAIError: Your default credentials were not found. To set up Application Default Credentials, see https://cloud.google.com/docs/authentication/external/set-up-adc for more information.Gemini - Google AI Studio | liteLLM: My bad, I needed the gemini/ part. This works for basic proxying!
> litellm --model "gemini/gemini-pro"Now again back to eval-lm.
THIS WORKED! Again skipped bits because safety but still
> python3 -m lm_eval --tasks low_test --model local-chat-completions --model_args base_url=http://0.0.0.0:8000 --include ./resourcesOK! So next steps:
- find a way to configure it through config, include safety bits