serhii.net
In the middle of the desert you can say anything you want
-
Day 389 (24 Jan 2020)
Day 389
Python type hinting
Allegedly one of the best tutorials to start with: Type hinting and annotations — Python for you and me 0.4.alpha1 documentation, link found here: A deep dive on Python type hints · Vicki Boykis. That blog in general is quite interesting, she’s the same person who wrote IT runs on Java 8 · Vicki Boykis.
Random - good small datasets
From the same blog above, Good small datasets · Vicki Boykis is nice. TIL datasets can have documentation.
Tensorflow SequenceExamples to and from String
tf.train.SequenceExample.FromString(se.numpy()).SerializeToString()==se, logically. They can be parsed without an extract function andtf.io.parse_single_sequence_example()
-
Day 386 (21 Jan 2020)
Intermezzo - 2
Три истории про Мерзебург
Вот про Мерзебург надо писать на русском языке, на самом деле, хотя нереально объяснить почему.
Сижу за идеально пустым столом комнатки где провел предыдущие 4 года. Вокруг какие-то непонятные бумаги на полу, какие-то ручки, как будто после урагана.
Now playing: Stravinsky - Le sacre du printemps / The Rite of Spring
Господи, сколько же всякого происходило тут за последние 4 года.
Сижу за знакомым столом, который на идеальной высоте, куда идеально ложатся локти. Хотя все вещи кроме общажной мебели отсюда увезены, чудом осталась свечка и спички. Сейчас она горит и пахнет воском, тоже до боли знакомый запах, с точностью до всех нот - конкретно такие свечки и покупал 4 года подряд. И писал на таких листочках А4, тем же почерком, той же рукой.
 {:height=“500px”}.
{:height=“500px”}.Свеча выглядит как будто она догорит сегодня, и это лучшее и самое правильное совпадение этого мира.
Комнатка прошла полный круг - а изменился ли я?
А еще - город где была сфокусирована моя жизнь довольно долгое время. Сейчас тут пустая комната, за окном - темнота, хорошие люди в городе и самом общежитии в общем-то остались, но само нахождение тут как-то просто странно. Очень хороший повод порефлексировать о том, как можно себя чувствовать совершенно чужим в каком-то городе, особенно по вечерам. Помню летние месяцы тут - за окном лето, ты в напрочь пустом общежитии маленького городка восточной Германии, чувство свободы и пустоты, лето, бесконечное лето, лето как состояние. С работой это все будет стираться, и надо пытаться себя учить замечать маленькие детали в изменениях сезонов, иметь хоть какие-то ритуалы связанные с разными порами года, чтоб это не сливалось и чувствовать, к приеру, лето, про-живать, пере-живать сезоны. Постик об этом, отчасти.
Но это все лирика, лирика которая не должна отвлекать нас от того, что на самом деле важно -
Окна
Слева от меня два огромных окна, традиционно жертвы моей любимой темы писать на окнах и давать хорошим людям писать на моих окнах. Очень много этих надписей связаны с вполне конкретными людьми и воспоминаниями.
Все что следует написано очень многими разными почерками и размерами и цветами, кроме левой половины первого окна.
 {:height=“500px”}.
{:height=“500px”}.Окно 1, левая половина
Life is a non-0-sum game. "Nothing exists except atoms and empty space. Everything else is opinion" - Democritus ____ - - - SIT, BE STILL AND LISTEN, BECAUSE YOU ARE DRUNK AND WE'RE ON THE EDGE OF THE ROOF - RUMI __________ BE A LIGHT UPON YOURSELF. ___________ ___________ I make my own coincidences, synchronicities, Luck, and Destiny. ____________ Rule your mind, or it will rule you. ____________ Безумие, безумие, безумие. (с) М. Рисунок роботов, вид сверху.Окно 1, правая половина
L'occhio del lupo Amazon U: ---/--- P: admin123 __________ Рисунок круга с точкой внутри Leave tonight or live and die this way. padik is where your semki shells lie Еще одна схема робота, одного, вид прямо Рисунок слона, подписан Ellina Antal Szerb: Reise im Mondlicht Это все часть путиNow playing: Händel - Sarabande, просто самая сильная извесная мне композиция. Мурашки по коже.
Продолжаю.
 {:height=“500px”}.
{:height=“500px”}.Окно 2, левая половина
-- Что мне терять на этоп этапе? -- Этап. Ойген Matthew 6:33 TachibanaPC2998 Wovor laüfst du weg? Непонятный рисунок с квадратиками, кружочками и штрих-пунктиром. We were dringking with Ukrainians! 19:01 Рисунок короны Рисунок трех синусоид, суммирующихся в 1 Две неразборчивых надписи 6C | 2-3 Wo bist du? Sergej Еще одна неразборчивая надпись Buch "Krabat" (↳ O.Preußler) Смайлик Логитип BMW Рисунок земли, над ней шар, вокруг шара концентрические стрелочки Под ним: "2001" I fucking like weather сука SOKOLY (I.M.T. SMILE)Окно 2, правая половина
Большой рисунок каббалисткого Древа Жизни, с буквами на иврите внутри 10:45 am Мыло для бульбашек Рисунок лица в очках Сережа ня :3 "Я тебя щелкну как семку!" (с) Женя Рисунок Дао 25см (i) 1:17 Странный рисунок лошади (?) перехоящей в ботинок (?) Der kleine Prinz ist bei mir! - Yasmin P.S. lies das Parfüm! Рисунок графика и минимумов в нем PRIMETIME SPIRIT Он хотел историй Он ее получит [sic] HN GL DF ALeXИнсмут
Тут еще будет уместен этот линк на пост, написанный когда я только-только приехал сюда: Файне місто Мерзбург | Я сам, соломка, чай.
Сложно написать что-то общее про Мерзебург и мое отношение к нему. Если бы писал, то “блеск и нищета” точно бы звучало. Чем-то очень темный город, маленький, по-своему в некотором роде некоторым образом уютный, без лишних претензий. Но все же, темный, давящий, причем давящий с самого начала. Все хорошее, что я мог про него говорить, было скорее стокгольмским синдромом и рационализацией.
Если город маленький, общение с людьми приобретает чуть больше граней. И общение с городом-вообще, где ты знаешь в лицо всех кассирш ближайшего магазина, единственного филиала банка, где четыре года подряд ходишь в одну аптеку и тебя там узнают, и ты узнаешь всех (двух) людей, которых ты там когда-либо видел за прилавком.
Как будто личности, которые часть этого города, имеют более прочную позицию в нем, имеют чуть большее значение. Ты встречаешь дедушку на лавочке, болтаешь с ним - дедушка важен, лавочка важна, озеро, около которого она, тоже важно. Ты не анонимен и лавочка не анонимна. Все имеет больший масштаб и связь между всем сильнее.
Вне этого - если что-то тебя давит, то город беспощаден, и тебе в нем не затеряться и не отвлечься. Сенека что-то писал про то, что постоянные переезды и путешествия – признак беспокойного духа. Мне кажется надо иметь нереально спокойный дух, чтоб мочь долго жить в маленьком городке.
Не Инсмут
А если иметь спокойный дух - условия в принципе идеальные. Маленький универсистет, университет в 50 метров от общежития. 200 метров дальше - спортивный комплекс. Там можно играть в теннис с людьми, которых туда приглашаешь. По дороге туда встречаешь всех. А в тренажерном зале встречаешь местами преподавательницу немецкого языка, местами - ректора, который стоит и ждет своей очереди на тренажер у тебя над душой, что очень неловко всем.
Мерзе это город где к тебе могут просто зайти и пригласить выйти погулять, и ты идешь и просто гуляешь по территории и по Tiergarten, до которого метров 500. Это город где шикарно гуляется ночью. И шикарно разговаривается ночью.
Это город, в котором нереально хорошо видны звезды, все, и ночью можно ходить на них смотреть в кукурузные поля (до которых метров 700). Где есть крыша, на которую можно залазить и оттуда смотреть на затмение.
Это город где ты идешь в магазин за едой и это интересно, и это развлекаловка, и ты резко понимаешь в чем может быть прелесть шоппинга.
Мерзе меня многому научил. От того, как это, когда вокруг у тебя Мерзебург, где мало что происходит, а ты хочешь чего-то интересного - и ты учишься to make your own fun и организовываешь вещи.
Эти 4 год атут были мне очень необходимыми и уместными, продлились ровно столько, сколько нужно, и закончились в идеальное для этого время.
В эти секунды тушится свечка.
Спасибо тебе, свечка, спасибо тебе, столик.
Спасибо тебе, здание 5B.
Спасибо тебе, Мерзебург, спасибо за все.
-
Day 385 (20 Jan 2020)
Day 385
Hammock driven development (video); towatch
Hammock Driven Development - Rich Hickey - YouTube looks like an interesting video. Also it’s transcripted! talk-transcripts/HammockDrivenDev.md at master · matthiasn/talk-transcripts Rich Hickey – Hammock Driven Development – melreams.com is a post about the same.
Intellij idea bookmarks!
Ctrl+Shift+3 to toggle bookmark 3, and Ctrl+3 to jump to it
Tensorflow
Building a data pipeline for
tf.Dataset.
-
Day 381 (16 Jan 2020)
Day 379
Semantic highlighting
This is actually really nice as idea, and as usual someone on the internet thought about this more than I did: Making Semantic Highlighting Useful - Brian Will - Medium
I somehow really like the idea of having color giving me actual semantic information about the thing I’m reading, and there are a lot of potentially cool stuffs that can be done, such as datatypes etc. It’s very connected to my old idea of creating a writing system that uses color to better and more concisely mark different letters, like the apparently defunct Dotsies but even more interesting.
Zsh autosuggestions (fish-like)
This is interesting: zsh-users/zsh-autosuggestions: Fish-like autosuggestions for zsh
Less noisy autocomplete than the default, should look similar to this:
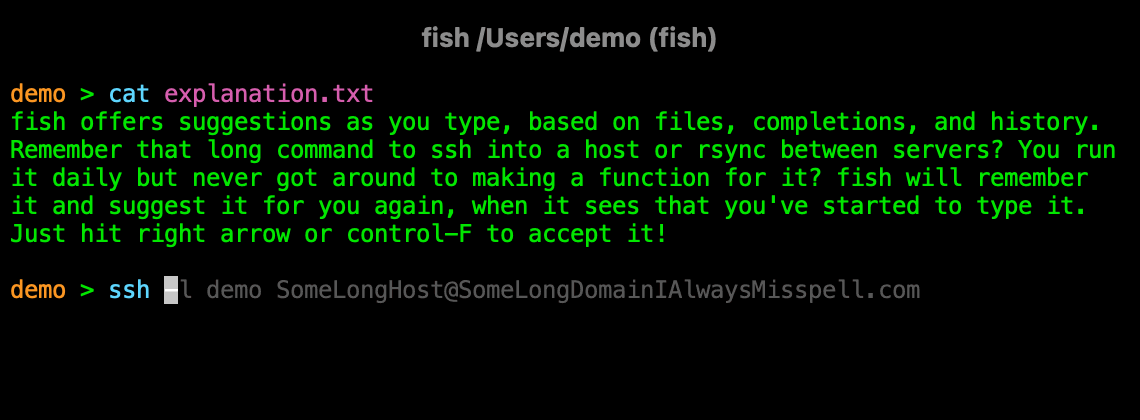
As a side note I like the
cat explanation.txtpart for screenshots.
-
Day 380 (15 Jan 2020)
Day 378
Adding numbers in Bash
integer arithmetic - How can I add numbers in a bash script - Stack Overflow
num=$((num1 + num2)) num=$(($num1 + $num2)).. which is what I used in the updated
create.shscript.FILE=_posts/$(date +%Y-%m-%d)-day$((365+$(date +%j))).markdownTensorflow
- TODO - why can’t
tf.convert_to_tensor()convert stuff to other types (int64->float32) and I have to usetf.cast()afterwards? tf.in_train_phase()– both x and y have to be the same shape- In a custom layer,
compute_mask()can return a singleNoneeven if there are multiple output layers!
German
Erfahrungsmäßig
- TODO - why can’t
-
Day 378 (13 Jan 2020)
Day 013
German random
The Ctrl key in Germany is “Strg”, pronounced “Steuerung”
English random
refuse - Dictionary Definition : Vocabulary.com Refuse as a verb is re-FYOOZ, as a noun it’s REF-yoss.
-
Day 363 (29 Dec 2019)
Day 363
German
- Schmierpapier: scratch paper
- verwursten: to make into wurst.
Random
-
Day 354 (20 Dec 2019)
Day 354
Tensorflow eager execution
Makes everything slower by about 2-4 times.