serhii.net
In the middle of the desert you can say anything you want
-
Day 1959 (13 May 2024)
Inkscape bullet points
- Not supported out of the box:
- https://alpha.inkscape.org/vectors/www.inkscapeforum.com/viewtopic0f39.html?t=9647:
-
I usually clone a circle and distribute it evenly next to the text object
<C-u-2022>adds a bullet point symbol
-
-
Day 1951 (05 May 2024)
Hack for quarto roughnotation and speaker view
Quarto’s roughnotation works either in speaker view or in the presentation, separately from each other.
Very brittle, but:
- jitsi share my presentation window, “show me what I’m sharing” and then right click picture-in-picture
- drag that picture over the presentation in speaker view :)
.. yeah.
-
Day 1946 (30 Apr 2024)
Inkscape poster video notes
So I learned that poster videos are a thing, 10 years ago I’d have used Prezi but not now
And TIL inkscape has neat keybindings for zooming.
So.
-
View -> Zoom has a list as well
- I should have looked at it earlier — it has neat things e.g. X-ray etc.:

- I should have looked at it earlier — it has neat things e.g. X-ray etc.:
-
3zooms in to the selected element -
1-6 are all zooming things (from the docu):
-
-
3-Layout-extraction-1 is a 6min description I have not watched but could be nice.
Inkscape not exporting to PDF after crash
A particularly complex file after a crash became cursed: two boxes would export to PNG fine, but not to PDF.


After closing and opening these two boxes became just as in the PDF export.
Solution: delete the problematic elements from the PDF and recreate them.
-
Day 1940 (24 Apr 2024)
Presentations with Quarto and Reveal.js
Basics
-
Oh it has another page with a clean reference! Quarto – Revealjs Options
-
Default presentation size is 1050x700
Presenting
slide-number: true hash-type: numberHide slide:
## Slide Title {visibility="hidden"}Slides themselves
Title slide
If you exclude title and author from frontmatter, no title slide will be created and you can create your own
Asides
Asides exist:
:::{.aside}Format
-
Many bits from Quarto – Markdown Basics etc. apply for presentations as well!
-
Comments are HTML comments.
- Other options exist but it’s still the best one. How to comment out some contents in .qmd files? · quarto-dev/quarto-cli · Discussion #3330
-
[this is a div]{.to-which .i-can add="stuff"} -
For slides w/o titles you can still do this
# {background-image="https://upload.wikimedia.org/wikipedia/commons/2/2b/Ouroboros-Abake.svg" background-position="center" background-size="contain" .center}
Centering stuff
- TODO
- Vertical/Horizontal
- Vertically and horizontally centered content in slides (revealjs) · quarto-dev/quarto-cli · Discussion #2951
- css - Vertical Align of images in Quarto Presentations - Stack Overflow
Complex layouts are possible with layouts:
::: {layout="1],[-1,1,1,1,-1"} {.nostretch width="500px" fig-align="center"} {.nostretch width="200px"} {.nostretch width="200px"} {.nostretch width="200px"} :::
Classes
## {.classname} ::: {.classname} div with class=classname ::: ::: {} div with no class — we still need the {} for it to be a div ::: ::: {.one-div} :::: {.inside-another} But the number of : doesn't matter as long as it's >3 — they aren't even matching by count, it's just divs inside divs inside divs, the number of : is just for readability :::: :::Plugins
Attribution
quarto-ext/attribution: Display attribution text sideways along the right edge of Revealjs slides.
format: revealjs: ... revealjs-plugins: - attribution --- ## attribution {.nostretch width="600px" fig-align="center"} ::: {.attribution} Photo courtesy of [@ingtotheforest](https://unsplash.com/@ingtotheforest) :::Roughnotation
Rto run.Sample presentation: RoughNotation; its source: quarto-roughnotation/example.qmd at main · EmilHvitfeldt/quarto-roughnotation
--- title: Simple roughnotation setup filters: - roughnotation ---- [type]{.rn rn-type=circle} - [animate]{.rn rn-animate=false} - [animationDuration]{.rn rn-animationDuration=20000} - [color]{.rn rn-color=blue} - [strokeWidth]{.rn rn-strokeWidth=3} - [multiline multiline multiline multiline multiline multiline multiline multiline multiline multiline]{.rn rn-multiline=true} - [iterations]{.rn rn-iterations=1} - [rtl]{.rn rn-rtl=false} also {.rn rn-type=underline}Key bits:
And this will be [circled]{.rn rn-type=circle rn-color=orange} and [underlined]{.rn rn-type=underline rn-color=orange rn-animate=false} and [boxed]{.rn rn-type=box rn-color=blue rn-animate=false} and [crossed]{.rn rn-type=crossed-off rn-color=blue rn-animate=false} and [crossed again]{.rn rn-type=strike-through rn-color=blue rn-animate=false}
rn-index=2for order so that the animations happpen one after the otherWorks for entire divs as well: RoughNotation
Problems with RN
It highlights the wrong places for me if the presentation is too narrow, both on mobile and desktop browsers; zooming out helps but too much breaks it again. EDIT: a known issue mentioned in the last slide of the sample presentation, they also suggest zooming.
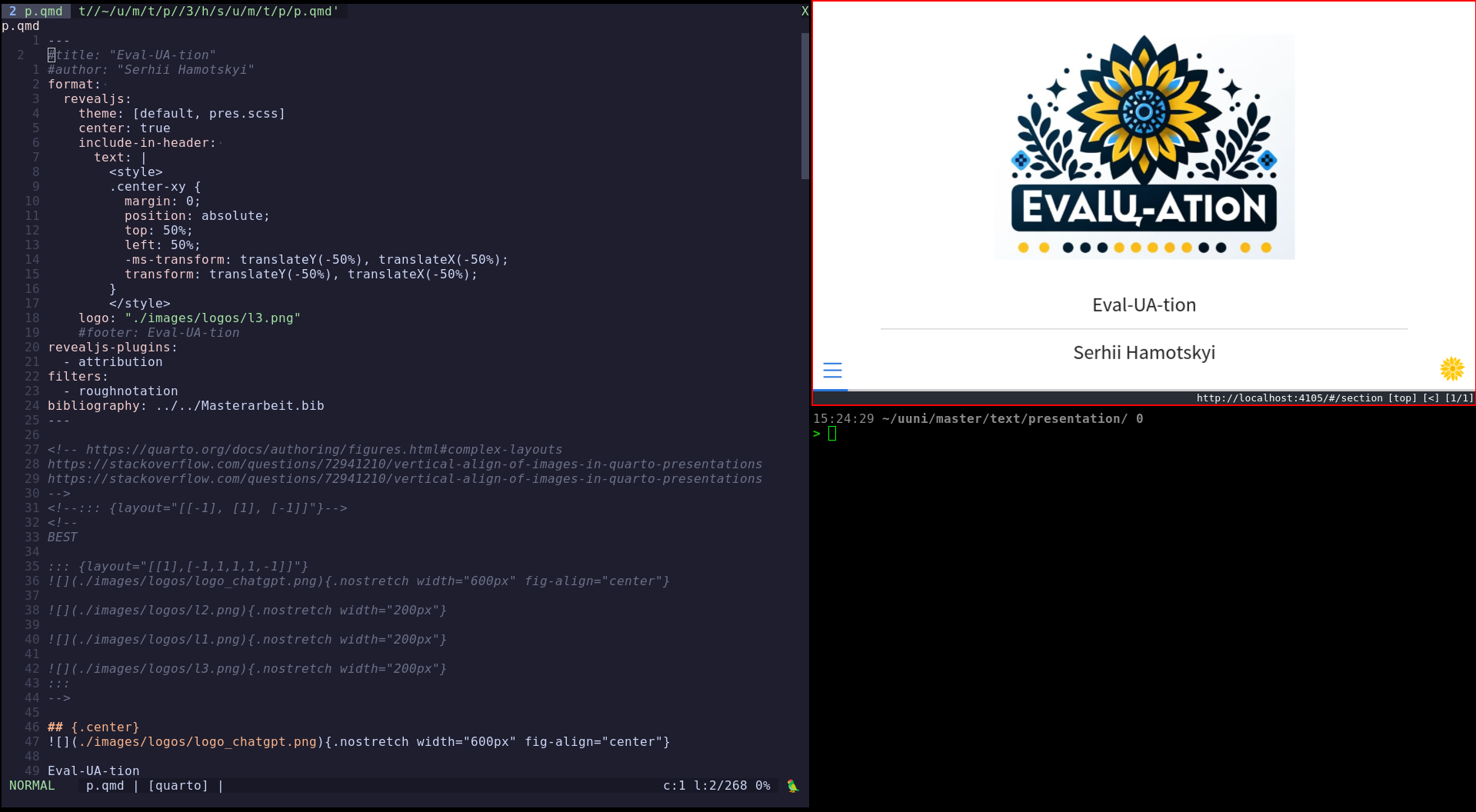
EDIT: No one said I have to use half a screen for previewing, this is a nice layout that solves multiple problems:
Themes
Default theme: quarto-cli/src/resources/formats/revealjs/quarto.scss at main · quarto-dev/quarto-cli
Centering everything
/*-- scss:defaults --*/ $presentation-slide-text-align: center !default;format: revealjs: theme: [default, my_scss_file.scss]BUT for some things it’s ugly, like lists. Then:
.notcenter { text-align: left; }## UA-CBT ### Outline ::: {.notcenter} - English example - Morphology - Agreement :::Smaller
{.smaller}works on full slides only, this works for divs too:.newsmaller { font-size: calc(#{$presentation-font-size-root} * #{$presentation-font-smaller}); }Increasing slide number size
.reveal .slide-number { font-size: 30px !important; }Cool links from elsewhere
Both linked by the excellent and thorough Beautiful Reports and Presentations with Quarto
References / citations
Quarto – Citations & Footnotes
.biblatex file exported from Zotero and optonally a CSL style (citation-style-language/styles: Official repository for Citation Style Language (CSL) citation styles.)
bibliography: ../../Masterarbeit.bib csl: ./diabetologia.csl --- # etc. In diabetologia this gives the usual [1] thingies. [@key] [see @key]Then autocomplete in vim-quarto (!)
Dynamism and animations
Incremental lists are
{.incremental}, or the entire presentation can berevealjs: incremental: truewith
{.nonincremental}parts.Otherwise Fragments1 exist with more control.
r-stack allows to make images overlapping: Quarto – Advanced Reveal
Simple template for slides with everything
## Title {.smaller} ::: {.notcenter} Descr. :::: {.incremental} - some - list :::: ::: <!-- footnotes here if needed [^leaderboard]: <https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard> --> ::: {.notes} sp. notes. ::: ::: footer Chapter - Section :::Bits
CSS inside slides
The excellent page of quarto presentation tricks Meghan Hall has this:
Text with [red words]{style="color:#cc0000"}.No special CSS classes needed!
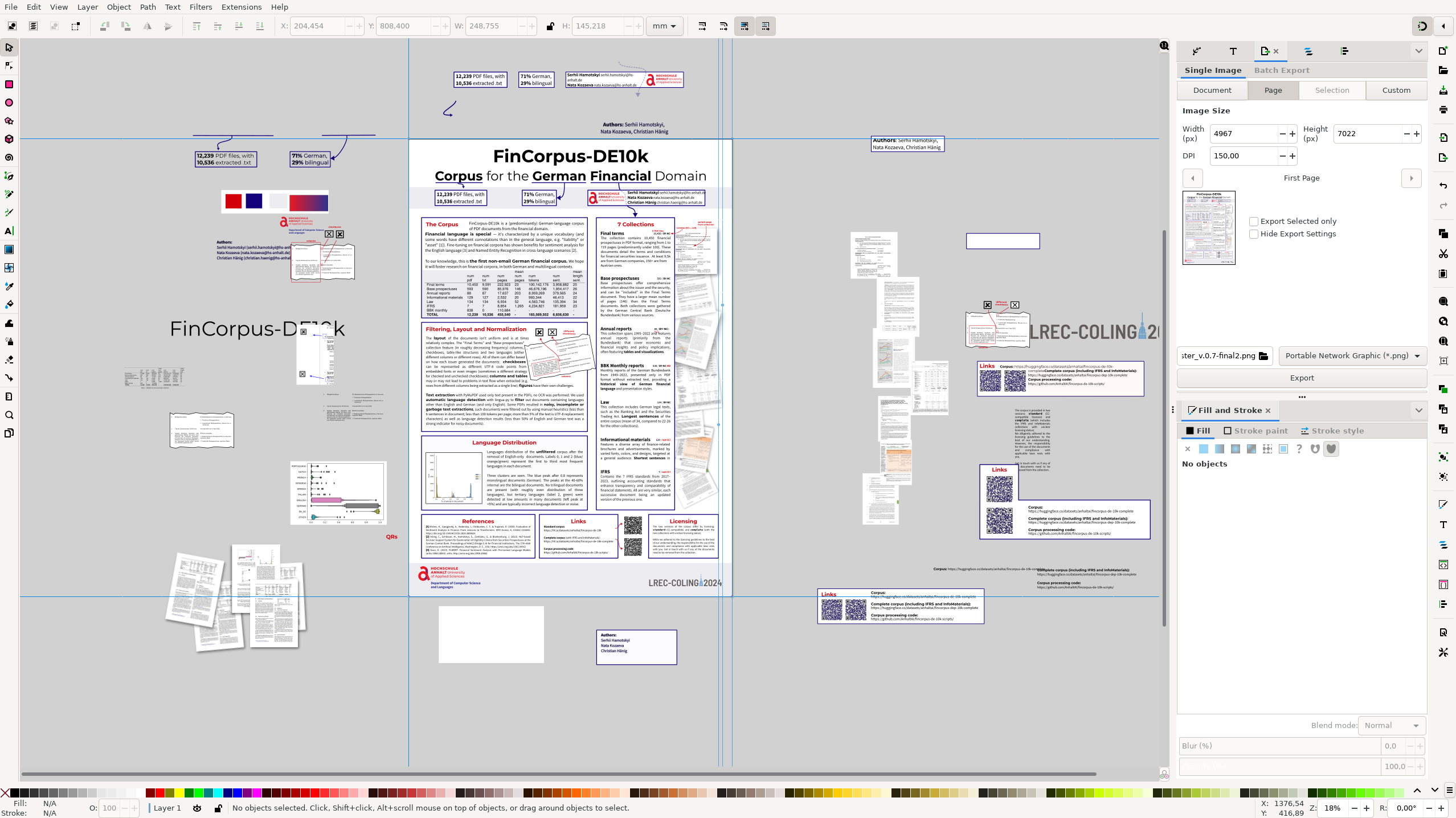
More inkscape bits learned doing posters
Context: 240423-1912 Better Posters notes
Grids
- Two — once in document properties, and there seems to be a tool for this as well.
- units are important — doing math in mm and then creating a grid in px/pc/pt/… may create not-obvious errors
- Snapping to an invisible grid still works — neat for a sub-grid that would create too much garbage but is needed (e.g. margins in a column)
Selecting
- You can select items by color/stroke/type/… in Edit -> Select…
- E.g. select all texts, all blue rectangles etc.
Resizing boxes
You can disable scaling the stroke size together with the box in the upper-right toolbar! (The same one where locking aspect ratios is)
Text
- You can draw a rectangle and then add text to it — use the text tool to draw this rectangle.
- Text -> Flow into frames can do what it says on the label:

- If it looks weird or different from other text but font and size and the rest match, the text likely has a stroke.
Tracking invisible items
For things into which text “flows” etc. — if you have a white background making them white works for keeping them selectable when needed. (And removing the background makes them visible).
Smile for the screenshot
Damn I love doing random vector stuff.
-
Day 1939 (23 Apr 2024)
Better Posters notes
The book by Better Posters’s author is freaking awesome. Short summary follows, not copypasting too much because copyright, but the book is 12/10.
Chapter 1: short form
TL;DR how to do a poster if you read only one chapter
- Three columns, margins around them and between them at 50mm
- so 8 inches/200mm for the margins toatl
-
take the width of your paper, subtract 8 inches (200 mm) for the margins,
and divide by three to find your column width. If your poster is 48 inches (1,220 mm), your columns will be 13⅓ inches (340 mm) wide. Yes, it’s an awkward number, but computers don’t care.
Short note to self
- A0 is 841 x 1189mm1
- My arm is around 70cm
- Later the recommendation is 6 columns because flexibility
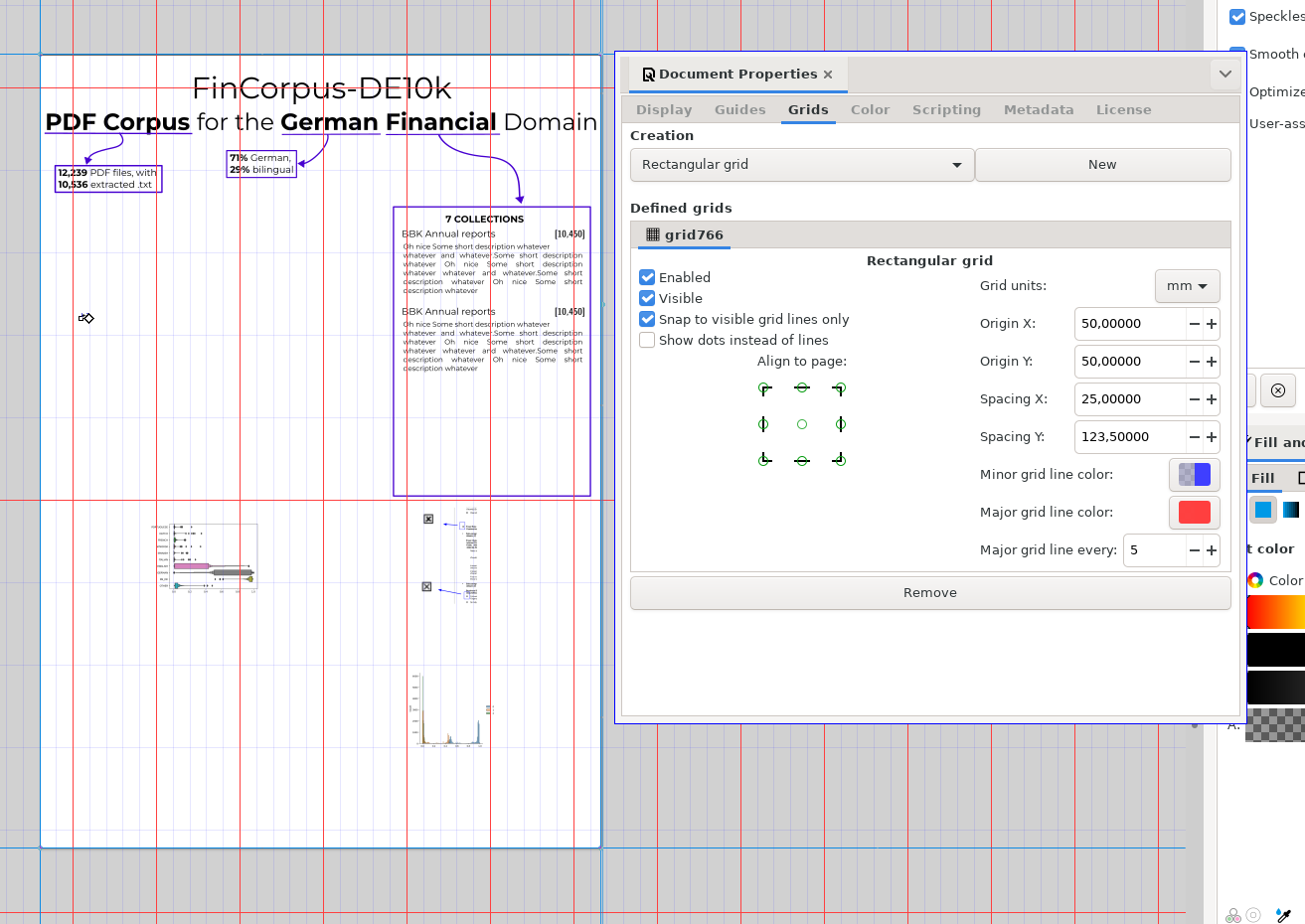
- So now it’s margins 50mm top/down/l/r w/ columns like this
> cc (1189-100)/6 181.5 > cc (841-100)/6 123.5After playing around, this is good enough I guess! (Ignore Y grid)
After ignoring even more advice:
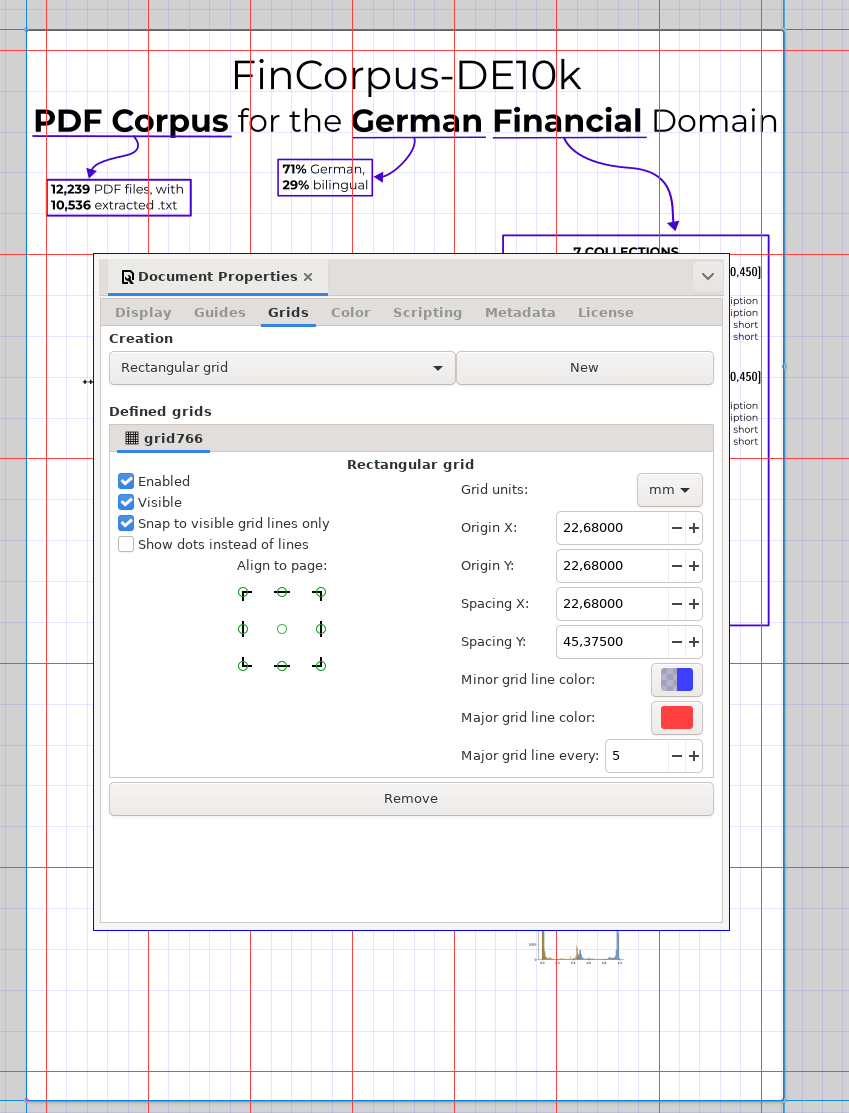 (EDIT: oh damn it’s 7, not 6!)
(EDIT: oh damn it’s 7, not 6!)Bits
- To look for typos, changing the font and column size helps! p. 49
Narrative
- Narrative
- AND, BUT, THEREFORE (ABT) p.59
- We scanned the salmon AND saw brain activity BUT this is impossible THEREFORE we should …
- Find a narrative and keep it in mind when doing the poster; get other people to do their narrative and see if it’s at least close to yours
- AND, BUT, THEREFORE (ABT) p.59
Visual thinking (p.64 Chapter 7)
Quoting directly because it’s freaking awesome.
- “Dan Roam argues that there are six basic ways to show something, and you can recognize which you need by the kind of question you hear (Roam 2013)”:
- If you hear a name – a “who or what” – you need a portrait. This is not necessarily a realistic or detailed portrait like a painting or a posed photo. A stick and ball chemical structure is a “portrait” of a molecule. A smiling emoji can be a portrait.
- • If you hear a number – a “how many” – you need a chart or graph. A bar graph is a simple example.
- • If you hear a location or a list – a “where” – you need a map. Again, this need not be a literal cartographic map. Anytime you talk about something “above,” “below,” “closer,” or “overlapping,” you have the potential to create a map. Examples include concept maps, pedigrees and phylogenies, org charts and Venn diagrams.
- • If you hear a history – a “when” – you need a timeline. “Time” is one of the most common variables shown graphically (Tufte 2001).
- • If you hear a sequence or process – a “how” – you need a flowchart.
- • If you hear some complex combinations – a “why” – you need a multi-variable plot, like a scatterplot.
-
Design is making things look similar (consistency, grids, fonts) and different (h2 vs the text, etc.)
-
Main rules:
- repetition, alignment, contrast, proximity
-
p.85 100-300 dpi is the sweet spot for posters
-
108 when deciding how much to narrow/widen a line graph, aim for a max slope of about 45 degrees
-
153 a font family is designed so that different fonts look OK together — DAMN.
Grids
The most important takeaway.
- 165 “layouts that never work”
[--][ ]two wides one tall[-] [-----]swedish flag
- Numerate the order if it’s not obvious
- Vary the place of the break so it’s not squares (right?down?) but obviously rows or columns:
Bad:
[ ][ ] [ ][ ]Good:
[ ][ ] [ ][ ]Text
- p.191 has a list of cliches to replace, e.g. “make use of” -> “use” and “the use of” -> (Omit)
- all-caps headers are worse because you can’t see the shape of the words — which is important from far away.
- serif or no serif doesn’t really matter from a design perspective.
Before you print
221 checklist and ratings
Practical bits
- Get a document tube! (And write your name on it!)
- How to do conferences shoes to stand in for hours, tacks, PDF to print it if sth happens etc.
Not from Better Posters
Random gray or whatever color stripes can live up a white background
See also
-
Day 1935 (19 Apr 2024)
Zathura is awesome
Have been using it casually but now I wanted a quick way to follow internal links in my Thesis and go back.
Zathura can do this and not just this apparently!
zathura(1) — Arch manual pages
- Tab goes to index mode, where space/enter follow the link in the index
fshows links that can be followed by typing the number and then enter^o, ^i: Move backward and forward through the jump list! Practically ^o is basically “go back”.
It even has a config file, with remapping, design and stuff zathurarc(5) — Arch manual pages
Downsides:
- the numbers shown w/
fare too small, and no way to change them - the follow-on-single-click option is in newer version than what I have access to (I should reinstall my system actually)
Latex footnotes in descriptions don't work
\begin{description} \item[Brown-UK\footnote{\href{https://github.com/brown-uk/corpus}{https://github.com/brown-uk/corpus}}] is an open, balanced ..Nope. It’s like tables — you’ll get the mark but not the actual footnote. Hard to notice.
-
Day 1934 (18 Apr 2024)
Latex centering wide tables
… is hard and nothing worked. If it’s over the margin at least.
After trial and error I got this1.
% \centerline{ \begin{table}[t] % \begin{center} \footnotesize \centering \addtolength{\leftskip} {-2cm} % increase (absolute) value if needed \addtolength{\rightskip}{-2cm} % \begin{adjustbox}{center} % \resizebox{1.0\textwidth}{!}{% Adjust the scale as needed \begin{tabular*}{1.25\textwidth}{lrrrrrrrrr} \hline & LOW & WIS & cats\_bin & cats\_mc & wordalpha & wordlength & UA-CBT & UP-masked & UP-unmasked \\ \hline BASELINE-human & 0.97 & 0.94 & 0.97 & 0.98 & 0.92 & 0.94 & 0.94 & 0.84 & 0.88 \\ BASELINE-random & 0.09 & 0.05 & 0.50 & 0.20 & 0.50 & 0.50 & 0.17 & 0.10 & 0.10 \\ Mistral-7B-Instruct-v0.2 & 0.34 & 0.19 & 0.59 & 0.71 & 0.48 & 0.71 & 0.46 & 0.75 & 0.86 \\ Ms-Inst-Ukr-SFT & 0.31 & 0.16 & 0.66 & 0.55 & 0.48 & 0.66 & 0.42 & 0.82 & 0.87 \\ Ms-Inst-Ukr-Slerp & 0.35 & 0.19 & 0.66 & 0.66 & 0.49 & 0.70 & 0.45 & 0.79 & 0.87 \\ Ms-Inst-Ukr-sherl & 0.37 & 0.19 & 0.69 & 0.76 & 0.50 & 0.75 & 0.55 & 0.88 & 0.92 \\ gpt-3.5-turbo & 0.68 & 0.34 & 0.68 & 0.91 & 0.78 & 0.89 & 0.61 & 0.77 & 0.86 \\ gpt-4-1106-preview & 0.67 & 0.39 & 0.86 & 0.93 & 0.85 & 0.95 & 0.97 & 0.96 & 0.97 \\ \hline \end{tabular*} % } % \end{adjustbox} % \caption[Evaluation scores]{\TODO{Scores of selected models}} \label{tab:eval} % \end{center} \end{table} % }The width
1.25\textwidthhas to be manually chosen otherwise the table lines are too long or short for the text.If it’s too low or too high it causes this (left is low):
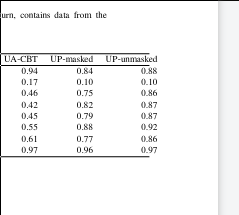

As usual, when doing these things, Overleaf’s draft mode is golden.
For positioning on the page, quoting Overleaf2:
The parameter `h!` passed to the table environment declaration establishes that this table must be placed _here_, and override LATEX defaults. The positioning parameters that can be passed-in include: `h` Will place the table _here_ approximately. `t` Position the table at the _top_ of the page. `b` Position the table at the _bottom_ of the page. `p` Put the table in a special page, for tables only. `!` Override internal LATEX parameters. `H` Place the table at this precise location, pretty much like h!.