serhii.net
In the middle of the desert you can say anything you want
-
Day 2203 (11 Jan 2025)
Python nested list comprehensions syntax
Nested list comprehensions are a horrible idea because they are hard to parse, and I never understood them, BUT.1
python - How do I make a flat list out of a list of lists? - Stack Overflow has a discussion in the accepted answer about the suggested syntax to flatten lists, and I get it now.
flat_list = [ x for xs in xss for x in xs ] # equivalent to flat_list = [] for xs in xss: for x in xs: flat_list.append(x)So,
[x for xs in xss for x in xs]Comments:
I found the syntax hard to understand until I realized you can think of it exactly like nested for loops. for sublist in l: for item in sublist: yield item
[leaf for tree in forest for leaf in tree]I kept looking here every time I wanted to flatten a list, but this gif is what drove it home: i.sstatic.net/0GoV5.gif
GIF IN QUESTION, after which it clicked for me:
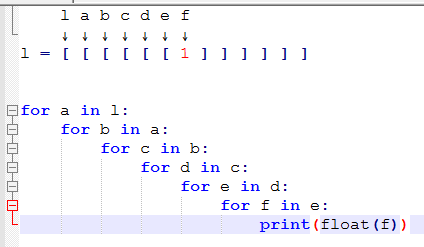
The first element is the one that gets returned!
for tree in forest: for leaf in tree: return leaf
[leaf (for tree in forest, for leaf in tree)]
[leaf (for tree in forest for leaf in tree)]
[leaf for tree in forest for leaf in tree]Found Understanding nested list comprehension syntax in Python — /var/ which expands on this, quoting PEP
It is proposed to allow conditional construction of list literals using for and if clauses. They would nest in the same way for loops and if statements nest now.
It then shows:
for x in non_flat: if len(x) > 2 for y in x: y # equivaent to >>> [ y for x in non_flat if len(x) > 2 for y in x ]MIND. BLOWN.
I’m not sure “this requires you to understand Python syntax” is an argument against using a given technique in Python This is about
itertools.chain(*list, which is the way to go imo. But still,*is python syntax, otherwise there are more or less readable ways to do thigs and nested comprehensions are rarely worth it
-
From comment to another answer in that same question that shames me: ↩︎
Poor-man's dark mode bits
- Qutebrowser:
:set colors.webpage.darkmode.enabled trueReally neat actually! ALSO:colors.webpage.preferred_color_scheme: darktells websites my preference - Nvim:
:colorscheme zaibatsu - Redshift:
redshift -r -P -O 4000 -b 0.3 - If I’m doing all that, I probably want to mute my speakers as well
Obsidian export HTML
For one-off HTML exports, found the plugin KosmosisDire/obsidian-webpage-export: Export html from single files, canvas pages, or whole vaults. Direct access to the exported HTML files allows you to publish your digital garden anywhere. Focuses on flexibility, features, and style parity.
It exports both the vault and individual pages, and adds things like toc on the left and toggles and optionally file browsing. Much better than the other pandoc-based export plugin that I could not get to work reliably for exporting good-looking HTML
-
-
Day 2201 (09 Jan 2025)
Git refuses to parse long paths on encrypted linux home
TL;DR clone to unencrypted directory
error: unable to create file datasets/processed/GitHub-Mensch-Animal_Finetuned/data/val/labels/1713256557366,hintergrund-meister-lampe-geht-das-licht-aus-vom-rueckgang-der-arten-tierische-und-pflanzliche-neubuerger-108~v-16x9@2dM-ad6791ade5eb8b5c935dd377130b903c4b5781d8.txt: File name too long
error: cannot stat ‘datasets/processed/GitHub-Mensch-Animal_Finetuned/data/val/images/1713256557366,hintergrund-meister-lampe-geht-das-licht-aus-vom-rueckgang-der-arten-tierische-und-pflanzliche-neubuerger-108~v-16x9@2dM-ad6791ade5eb8b5c935dd377130b903c4b5781d8.jpg’: File name too long
The usual solution1 is to set
longpaths = truein git config or during clone (git clone -c core.longpaths=true <repo-url>)Didn’t solve this for me.
BUT apparently my encrypted
$HOMEhas something to do with this, because filenames can get longer (?) in this case and go over the limit?.. git checkout-index: unable to create file (File name too long) - Stack OverflowAnd one solution is to clone to
/tmpor whatever is not encrypted by encryptfs.(And in my case I could rename these files in a commit in /tmp and after that it worked, as long as I don’t check out the revisions with the long filenames)
-
Day 2183 (22 Dec 2024)
Centerline tracing
- Goal: centerline trace pngs
- Inscape
- Script, extension, now part of Inkscape: inkscape-centerline-trace/centerline-trace.py at master · fablabnbg/inkscape-centerline-trace
- Inkscape as a purely command line tool : r/Inkscape reddit on using the CLI and running the extension standalone and how it doesn’t really work
- Can’t get it to work using CLI either, there’s just
bitmap-tracethat has no centerline option
- Not inkscape
Autotrace is awesome!
This alone works really nicely:
autotrace -centerline AMPERSAND.png -output-file AMPERSAND.svgFish script for batch processing, courtesy of ChatGPT:
#!/usr/bin/fish # Check if autotrace is installed if not type -q autotrace echo "autotrace is not installed. Please install it first." exit 1 end # Loop through each .png file provided as an argument for file in $argv # Check if the file extension is .png if string match -r '\.png$' $file # Set the output filename by replacing .png with .svg set output_file (string replace -r '\.png$' '.svg' $file) # Execute autotrace with centerline option autotrace -centerline $file -output-file $output_file # Confirmation message echo "Processed $file to $output_file" else echo "Skipping $file: not a .png file" end endAnd a more simple one:
#!/usr/bin/fish for file in $argv autotrace -centerline $file -output-file "$file.svg" endOptions
ChatGPT says this:
autotrace -centerline -input-format png -output-format svg -output-file traced_dejavu.svg -dpi 300 -error-threshold 0.5 -corner-threshold 85 -filter-iterations 2 -noise-removal 0.99 -line-threshold 0.5 -corner-surround 3(et 1 is best)
Using inkscape CLI
Using the Command Line - Inkscape Wiki
-
inkscape action-listshows all available actions -
man inkscapeis the latest and best -
inkscape AMPERSAND.png --export-type="svg" --export-area-page --batch-processworks but asks me about import options
inkscape --shell, man page gives examples:file-open:file1.svg; export-type:pdf; export-do; export-type:png; export-do file-open:file2.svg; export-id:rect2; export-id-only; export-filename:rect_only.svg; export-doOK this works for no questions about how to import it:
> file-open:AMPERSAND.png > export-filename:AM.svg > export-do
-
Day 2181 (20 Dec 2024)
Trivial HTML and JS audio player
One control, play/pause.
const buttons = document.querySelectorAll('.play-pause-btn'); buttons.forEach(button => { const audio = document.getElementById(button.dataset.audio); button.addEventListener('click', () => { if (audio.paused) { // Pause all other audio files document.querySelectorAll('audio').forEach(a => { a.pause(); a.currentTime = 0; // Reset other audio files }); document.querySelectorAll('.play-pause-btn').forEach(btn => { btn.textContent = '▶'; }); // Play the clicked audio audio.play(); button.textContent = '⏸︎'; } else { audio.pause(); button.textContent = '▶'; } }); // Reset button icon when audio ends audio.addEventListener('ended', () => { button.textContent = '▶'; }); });Multiple players:
<div class="player-container"> <button class="play-pause-btn" data-audio="audio1">▶️</button> <audio id="audio1" src="audio1.mp3"></audio> </div> <div class="player-container"> <button class="play-pause-btn" data-audio="audio2">▶️</button> <audio id="audio2" src="audio2.mp3"></audio> </div>.player-container { display: inline; vertical-align: text-bottom; align-items: center; margin-bottom: 20px; } .play-pause-btn { font-size: 32px; background: none; border: none; cursor: pointer; margin-right: 10px; }
Panflute and pandoc for parsing qmd and other files
- Quarto markdown is a superset of pandoc markdown, unrelated article about the latter: Everything pandoc Markdown can do
- Pandoc has a python library: Pandoc (Python Library)
- panflute is a more python way to parse docs and write pandoc filters, and I love it: User guide — panflute 2.3.0 documentation
I missed an ability to recursively look for elements matching a condition in panflute, so:
def _recursively_find_elements( element: Element | list[Element], condition: Callable ) -> list[Element]: """Return panflute element(s) and their descendants that match conditition. """ results = list() def action(el, doc): if condition(el): results.append(el) if not isinstance(element, list): element = [element] for e in element: e.walk(action) return results # sample condition def is_header(e) -> bool: cond = e.tag == "Header" and e.level == 2 # and "data-pos" in e.attributes return condAh, to read:
ddoc = pf.convert_text( markdown, input_format="commonmark_x+raw_html+bracketed_spans+fenced_divs+sourcepos", output_format="panflute", )To output readably:
pf.stringify(el).strip()Pandoc/panflute get line numbers of elements
input_formathas to becommonmark[_x]+sourcepossourceposisn’t too well documented, only w/commonmark- it basically sets
el.attributes['data-pos']a la126:1-127:1 line_noalways matching what I expect
def _parse_data_pos(p: str) -> tuple[tuple[int, int], tuple[int, int]]: """Parse data-pos string to (line, char) for start and end. Example: '126:1-127:1' -> ((126, 1), (127, 1)) Arguments: p: data-pos string as generated by commonmark+sourcepos extension. """ start, end = p.split("-") start_l, start_c = start.split(":") end_l, end_ch = end.split(":") return (int(start_l), int(start_c)), (int(end_l), int(end_ch))
-
Day 2172 (11 Dec 2024)
Fish import env. variables from a .env file
Fish Shell function for sourcing standard .env files :
. (sed 's/^/export /' .env | psub)(And yet another mention of Taskfile that I’ll definitely look into nowG)
-
Day 2128 (28 Oct 2024)
Headless printing of HTML to PDF with selenium and quarto reveal presentations
I want to automatically get the PDF version of quarto/reveal presentations. The usual way would be to open the presentation in export mode
e, then print with no margins through the usual print window.I want to do this automatically as part of a CI/CD pipeliene.
Options
- Generate PDF from revealjs presentation (consistent with PDF Export in revealjs) · quarto-dev/quarto-cli · Discussion #7018
- selenium-print · PyPI / bubblegumsoldier/selenium-print uses selenium+chromium to do this.
- PDF Export | reveal.js
Selenium-print
selenium-print · PyPI / bubblegumsoldier/selenium-print uses selenium+chromium to do this.
As for the printing options available in Chrome, this looks relevant:
selenium-print/seleniumprint/drivers/chrome_pdf_driver.py at main · bubblegumsoldier/selenium-print
pdf = self.driver.execute_cdp_cmd("Page.printToPDF", {"printBackground": True})OK, so it’s all a static option.
Chrome DevTools Protocol - Page domain has the other available options — which is what I need.
The rest of the code feels like a wrapper to this — maybe I can drop the entire library and just use these single bits?
Decttape (?)
{kind=link}