serhii.net
In the middle of the desert you can say anything you want
-
Day 2305 (24 Apr 2025)
Ignoring stuff in flake8 pylint black etc.
-
Selecting and Ignoring Violations — flake8 7.2.0 documentation
-
mypy
-
ty: https://docs.astral.sh/ty/suppression/
a = 10 + "test" # ty: ignore[unsupported-operator]# type: ignore[arg-type, ty:missing-argument]both ty+mypy same line Ignoring files:
# type: ignore # flake8: noqa # pylint: skip-file
vscode and cursor IDE settings
[]
Autosave and format
"files.autoSave": "onFocusChange", "[python]": { "editor.formatOnSave": true, // "editor.defaultFormatter": "charliermarsh.ruff", "editor.defaultFormatter": "ms-python.black-formatter", // reformat everything w/ ruff "editor.codeActionsOnSave": { "source.fixAll": "explicit", "source.organizeImports": "explicit" }, },Misc
"editor.rulers": [ 78, 88 ], "editor.lineNumbers": "relative", "editor.formatOnPaste": true, "editor.formatOnSave": true, // non-python stuff like settings.json"debug.allowBreakpointsEverywhere": true, "debug.inlineValues": "on",Vim
<S-j>/<S-k>to switch tabs"vim.normalModeKeyBindingsNonRecursive": [ { "before": [ "J" ], "after": [], "commands": [ "workbench.action.nextEditor" ] }, { "before": [ "K" ], "after": [], "commands": [ "workbench.action.previousEditor" ] } ], //"editor.fontFamily": "'Droid Sans Mono', 'monospace', monospace", "editor.fontFamily": "Fira Code", "editor.fontLigatures": true,<C-P>to show comman palette a la Obsidian"vim.normalModeKeyBindingsNonRecursive": [ { "before": [ "<C-p>" ], "commands": [ "workbench.action.showCommands" ] } [...] "vim.visualModeKeyBindingsNonRecursive": [ { "before": [ "<C-p>" ], "commands": [ "workbench.action.showCommands" ] } ], "vim.insertModeKeyBindings": [ { "before": [ "<C-p>" ], "commands": [ "workbench.action.showCommands" ] } ],Etc
w- “Cursor Dark High Contrast” is a really nice high-constrast theme!
"editor.fontWeight": "bold",
-
-
Day 2296 (15 Apr 2025)
Evaluating NLG
Papers
-
[2303.16634] G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment 1
- Excellent
- Main pitch:
- “Auto CoT evaluation”: make the LLM generate a chain-of-thoughts based on provided criteria
- get the LLM evaluate texts based on that CoT as form-filling task
- weight by the probabilities of the votes as given by the LLM
1*chance-of-1+2*chance-of-2
- Compares own evaluators to multiple others
-
[2302.04166] GPTScore: Evaluate as You Desire2
- basics:
- task: e.g. summarize
- aspect: e.g. relevance
- eval protocol: how likely it is that this text was generated given this task and this aspect?
- main pitch:
- LLM-estimated likelihood of text based on task+aspect+result.
- For summary:
{Task_Specification} {Aspect_Definition} Text: {Text} Tl;dr: {Summ}
- aspects:
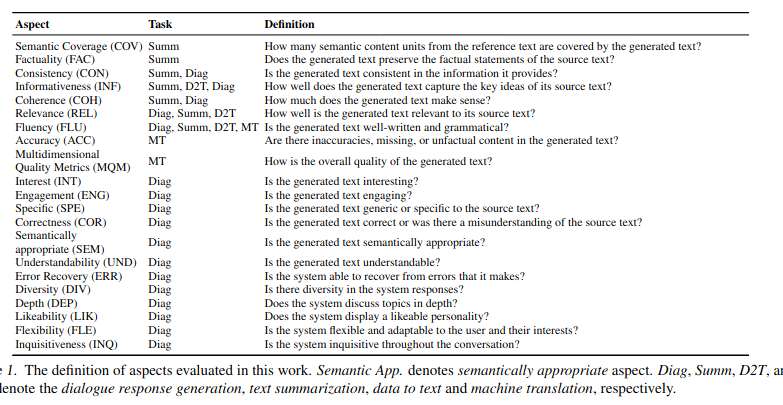
- basics:
-
UniEval [2210.07197] Towards a Unified Multi-Dimensional Evaluator for Text Generation3
- one trained evaluator to rule them all, based on boolean Q/A
- “is this a coherent summary?” -> chances for yes/no -> profit
-
LLM Comparative Assessment: Zero-shot NLG Evaluation through Pairwise Comparisons using Large Language Models4
Approaches
Main goal: coherence with human judgement
Kinds
Reference-free
- LLM-estimate the probability is a generated text
- assumption being that better texts have better probability
- downsides: unreliable / low human correspondence according to 1
- Ask an LLM how coherent / grammatical /
criterium_namethe output is from 0 to 5- downsides: LLMs will often pick
3but G-Eval works around that
- downsides: LLMs will often pick
Reference-based
- BLEU/ROUGE and friends (n-gram based)
- low correlation with human metrics
- (semantic) Similarity between two texts based on embeddings (BERTScore/MoverScore)
- GPTScore2: higher probability to texts better fitting the framing
- FACTUAL CONSISTENCY of generated summaries: FactCC, QAGS5
Framings (for GPT/LLM-based metrics)
- Form-filling (G-Eval)
- Conditional generation (=probability): GPTScore
Pairwise comparisons
- Pairwise comparisons4
How to evaluate evaluations
Meta-evaluators
- Meta-evaluators are a thing! (= datasets based on human ratings)
- Correlation with human metrics
Stats
- Many papers use various statistical bits to compare them.
- G-Eval (p. 6)
- Spearman, Kendall-Tau correlations
- Krippendorf’s Alpha
On a specific task
Task formulation
- Input:
- Advert for a car.
Car has 4 wheels
- Target profile of possible client
family with 10 kids 5 dogs living in the Australian bush
- Advert for a car.
- Output:
- Advert targeted for that profile:
ROBUST car with 4 EXTRA LARGE WHEELS made of AUSTRALIAN METAL able to hold 12 KIDS and AT LEAST 8 DOGS
- Advert targeted for that profile:
Concrete approaches
- Factual correctness / hallucinations
- Framed as summarization evaluation: FactCC, QAGS5
- GPTScore, G-Eval based on yet-to-be-determined-criteria
- Coherence, consistency, fluency, engagement, etc. — the criteria used by meta-evaluators?
- GPTScore aspects
- TODO: ask the car company what do they care about except factual correctness and grammar
- information density-ish? Use an LLM to get key-value pairs of the main info in the advert (
number_of_wheels: 4), formulate questions based on each, and score better the adverts that contain answers to more questions!- Inspired by QAGS
TODO
- LLM-as-a-judge and comparative assestment
- think about human eval + meta-eval
- think about what we want from the car company
- metrics they care about
-
G-Eval: <_(@liuGEvalNLGEvaluation2023) “G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment” (2023) / Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, Chenguang Zhu: z / http://arxiv.org/abs/2303.16634 / 10.48550/arXiv.2303.16634 _> ↩︎ ↩︎ ↩︎ ↩︎
-
<_(@fuGPTScoreEvaluateYou2023) “GPTScore: Evaluate as You Desire” (2023) / Jinlan Fu, See-Kiong Ng, Zhengbao Jiang, Pengfei Liu: z / http://arxiv.org/abs/2302.04166 /
10.48550/arXiv.2302.04166_> ↩︎ ↩︎ -
<_(@zhongUnifiedMultiDimensionalEvaluator2022) “Towards a Unified Multi-Dimensional Evaluator for Text Generation” (2022) / Ming Zhong, Yang Liu, Da Yin, Yuning Mao, Yizhu Jiao, Pengfei Liu, Chenguang Zhu, Heng Ji, Jiawei Han: z / http://arxiv.org/abs/2210.07197 /
10.48550/arXiv.2210.07197_> ↩︎ -
<_(@liusieLLMComparativeAssessment2024) “LLM Comparative Assessment: Zero-shot NLG Evaluation through Pairwise Comparisons using Large Language Models” (2024) / Adian Liusie, Potsawee Manakul, Mark J. F. Gales: z / http://arxiv.org/abs/2307.07889 /
10.48550/arXiv.2307.07889_> ↩︎ ↩︎ -
<_(@wangAskingAnsweringQuestions2020) “Asking and Answering Questions to Evaluate the Factual Consistency of Summaries” (2020) / Alex Wang, Kyunghyun Cho, Mike Lewis: z / http://arxiv.org/abs/2004.04228 / 10.48550/arXiv.2004.04228 _> ↩︎ ↩︎ ↩︎
-
<_(@fabbriSummEvalReevaluatingSummarization2021) “SummEval: Re-evaluating Summarization Evaluation” (2021) / Alexander R. Fabbri, Wojciech Kryściński, Bryan McCann, Caiming Xiong, Richard Socher, Dragomir Radev: z / https://direct.mit.edu/tacl/article/doi/10.1162/tacl_a_00373/100686/SummEval-Re-evaluating-Summarization-Evaluation / 10.1162/tacl_a_00373 _> ↩︎
-
<_(@gopalakrishnanTopicalChatKnowledgeGroundedOpenDomain2023) “Topical-Chat: Towards Knowledge-Grounded Open-Domain Conversations” (2023) / Karthik Gopalakrishnan, Behnam Hedayatnia, Qinlang Chen, Anna Gottardi, Sanjeev Kwatra, Anu Venkatesh, Raefer Gabriel, Dilek Hakkani-Tur: z / http://arxiv.org/abs/2308.11995 / 10.48550/arXiv.2308.11995 _> ↩︎
-
-
Day 2295 (14 Apr 2025)
Latex referencing figure without caption
Tried to use
subfigfor two figures side by side, but couldn’t\autorefit.
I had a caption for the individual subfigs but not for the large figure itself. As soon as I added the caption it worked.\begin{figure}% \centering \subfloat[\centering caption subfig 1]{{\includegraphics[width=0.4\linewidth]{images/fig2.png}}}% \qquad \subfloat[\centering caption subfig 2]{{\includegraphics[width=0.4\linewidth]{images/fig4.png} }}% \caption{Without } \label{fig:twosamples}% \end{figure} \autoref{fig:twosamples}
-
Day 2270 (19 Mar 2025)
Pydantic validation blues
Pydantic’s
FilePathis like Path except that the file has to exist and be a file.BUT
FilePathwhen validating expects a string as input, not a Path! (in other words:FilePath(Path)doesn’t seem to work)So when I create a Validator that converts
strintoPath1:@field_validator("filename", mode="before") @classmethod def parse_filename(cls, value: str | Path) -> Path: return Path(value)I get a wonderful
> doc = UCFDocument.model_validate_json(json_string) E pydantic_core._pydantic_core.ValidationError: 1 validation error for UCFDocument E filename E Input is not a valid path for <class 'pathlib.Path'> [type=path_type, input_value=PosixPath('/home/sh/w/cor...n/doc.pdf_data/doc.pdf'), input_type=PosixPath] tests/ucf/test_data_structures.py:179: ValidationErrorAgain, the error is a
PosixPathnot being a Path, though it is one:E Input is not a valid path for <class 'pathlib.Path'> [type=path_type, input_value=PosixPath('/home/sh/w/cor...n/doc.pdf_data/doc.pdf'), input_type=PosixPath] # explicitly expecting a PosixPath creates an even better E Input is not a valid path for <class 'pathlib.PosixPath'> [type=path_type, input_value=PosixPath('/home/sh/w/cor...n/doc.pdf_data/doc.pdf'), input_type=PosixPath]Not intuitive at all.
Solution is to give FilePath strings and only strings, or drop
FilePathto begin with.├── pydantic v2.10.6 │ ├── annotated-types v0.7.0 │ ├── pydantic-core v2.27.2 │ │ └── typing-extensions v4.12.2
-
(don’t ask why I needed this, this is a minimal reproducible example only) ↩︎
CVAT for image labeling
CVAT is a really neat labelling platform, online + free on-premise w/ Docker.
(Github: cvat-ai/cvat: Annotate better with CVAT, the industry-leading data engine for machine learning. Used and trusted by teams at any scale, for data of any scale.)I like it more than label studio for images, has more functions, but is also “heavier” / bulkier.
Love how it supports even 600mb 4-channel TIFF satellite images and is quite fast at that.
Bits:
- Enable auto-save every N minutes
<C-a>for snipping polygons to existing polygon ponits- “Backup project” to re-import later, “Export project” to get e.g. YOLO annotations
-
-
Day 2268 (17 Mar 2025)
Current LLM evaluation landscape
The Open LLM Leaderboard is dead1, as good time as any to look for new eval stuff!
-
HF universe
- The Open LLM Leaderboard people are actually OpenEvals (OpenEvals), and they created other cool stuffs
- huggingface/lighteval: Lighteval is your all-in-one toolkit for evaluating LLMs across multiple backends eval suite
- I like their documentation for new task / new model
- huggingface/evaluation-guidebook: Sharing both practical insights and theoretical knowledge about LLM evaluation that we gathered while managing the Open LLM Leaderboard and designing lighteval!
- the contents are awesome, w/ examples, model-as-a-judge, etc.
- huggingface/lighteval: Lighteval is your all-in-one toolkit for evaluating LLMs across multiple backends eval suite
- evaluate-metric (Evaluate Metric) recommended by them as a guide to existing metrics
- The Open LLM Leaderboard people are actually OpenEvals (OpenEvals), and they created other cool stuffs
-
Harnesses
- Evalverse: Unified and Accessible Library for Large Language Model Evaluation meta-thing that can run different harnesses based on the target. Github repo archived? UpstageAI/evalverse: The Universe of Evaluation. All about the evaluation for LLMs.
- open-compass/opencompass: OpenCompass is an LLM evaluation platform, supporting a wide range of models (Llama3, Mistral, InternLM2,GPT-4,LLaMa2, Qwen,GLM, Claude, etc) over 100+ datasets.
- don’t really like their documentation on adding datasets/models
- The venerable stanford-crfm/helm: Holistic Evaluation of Language Models (HELM)
- openai/evals: Evals is a framework for evaluating LLMs and LLM systems, and an open-source registry of benchmarks.
-
Resources / articles:
- How to evaluate by Meta: Validation | How-to guides
- HF eval guidebook: huggingface/evaluation-guidebook
-
-
Day 2264 (13 Mar 2025)
Installing SSDs into M.2 slots and drive stuff
- M.2 slots have keys: How do I install an M.2 SSD on my computer? - Transcend Information, Inc.
- B+M means both B and M slots are acceptable for the B+M module
CLI:
sudo lshw -C disktells you all disks h
-
Day 2262 (11 Mar 2025)
Python fsspec copying files
In fsspec
fs.copy()doesn’t really work from local to remote, also existing or not-existing directories etc.Their documentation has a whole page on this: Copying files and directories — fsspec 2024.10.0.post13+gdbed2ec.d20241115 documentation
-
Day 2251 (28 Feb 2025)
Gitlab cli runner `glab`
GitLab CLI -
glab| GitLab Docs: CLI thingy to interact with gitlab.It’s really neat and has a cool CLI interface, either you set things through flags or you get a neat menu to choose from!
Smart enough to parse current directory!
Pipelines:
glab ci statusfor a curses interfaceglab ci status -lis a live view as they run
