serhii.net
In the middle of the desert you can say anything you want
-
Day 1722 (19 Sep 2023)
seaborn label bars in histogram plot
The ’new’ function in matplotlib for this is matplotlib.pyplot.bar_label — Matplotlib 3.8.0 documentation (ty Revisions to Display count on top of seaborn barplot [duplicate] - Stack Overflow):
ax = sns.histplot(df.langs_parsed) #ax.set_xlabel("Language(s)") #ax.set_ylabel("# of files") for i in ax.axes.containers: ax.bar_label( i, )The second link has infos about barplot, catplot, and countplot too!
If the text goes over the limit and the light-gray background of seaborn’s theme or something, increase the limit as:
ylim = ax.axes.get_ylim()[1] new_ylim = ylim + 300 ax.axes.set_ylim(0, new_ylim) # you can also set padding of the labels in px and Text (https://matplotlib.org/stable/api/text_api.html#matplotlib.text.Text) properties: for ax in g.axes.containers: g.bar_label(ax, padding=-10,fontsize=5)Disabling scientific notation / setting format
EDIT 2023-10-06: To disable scientific notation, one can use the
fmt=argument (seebar_labeldocu) where one can pass a format, including as f-string:for i in ax.axes.containers: ans = ax.bar_label( i, fmt="{:,.2f}", )There’s also a parameter that decides at which point to start to use sci. notation, I think I closed the tab with the link though+
-
Day 1717 (14 Sep 2023)
German NLP resources
It includes a really cool list of corpora!
And at the end has a list of other such pages for other languages etc.
Also: deutschland · PyPI: “A python package that gives you easy access to the most valuable datasets of Germany.”
-
Day 1714 (11 Sep 2023)
Latex print or not the entire bibliography from a file
The LREC Author’s Kit prints all things in the .bib file and it uses
\nocite{*}for that.The Internet from 2009 agreess that’s the way to go : Biblatex - Printing all entries in .bib file (cited and not)
Removing this line removes the printout.
Lastly, the link above shows printing separate bibliographies; the LREC Author’s kit does something different for the same:
\subsection{Language Resource References} Language resource references should be listed in alphabetical order at the end of the paper. \nocite{*} \section{Bibliographical References}\label{sec:reference} \bibliographystyle{lrec-coling2024-natbib} \bibliography{lrec-coling2024-example} \section{Language Resource References} \label{lr:ref} \bibliographystylelanguageresource{lrec-coling2024-natbib} \bibliographylanguageresource{languageresource}
-
Day 1711 (08 Sep 2023)
Latex page-breaks
TL;DR
\newpage~\newpage~\newpage~\newpagefor 3 empty pages\newpagedoesn’t always work for well me in, esp. not in the IEEE and LREC templates. Either only one column is cleared, or there are issues with images/tables/… positions.\clearpageworks for me in all cases I’ve tried.EDIT: but only one page, not multiple! For multiple empty pages one after the other this1 does the trick:
\newpage ~\newpageChatGPT thinks it works because
~being a non-breaking space makes LaTex try to add both empty pages on the same page, leading to two empty pages. Somehow allowing a newline between new pages makes it interpret both pages as the same command, since it’s already a new page.
-
Day 1639 (28 Jun 2023)
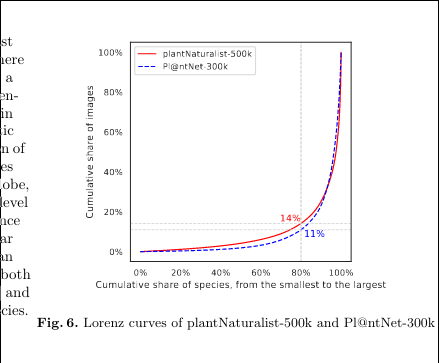
Everything I know about saving plots in matplotlib, seaborn, plotly, as PNG and vector PDF/EPS etc.
Seaborn saving with correct border
When saving seaborn images there was weirdness going on, with borders either cutting labels or benig too big.
Solution:
# bad: cut corners ax.figure.savefig("inat_pnet_lorenz.png") # good: no cut corners and OK bounding box ax.figure.savefig("inat_pnet_lorenz.png", bbox_inches="tight")Save as PDF/EPS for better picture quality in papers
EDIT 2023-12-14
Paper reviewer suggested exporting in PDF, which led me to graphics - Good quality images in pdflatex - TeX - LaTeX Stack Exchange:
Both gnuplot and matplotlib can export to vector graphics; file formats for vector graphics are e.g. eps or pdf or svg (there are many more). As you are using pdfLaTeX, you should choose pdf as output format, because it will be easy to include in your document using the graphicx package and the \includegraphics{} command.
Awesome! So I can save to PDF and then include using the usual code (edit - eps works as well). Wow!
Plotly
Static image export in Python:
fig.write_image("images/fig1.png")PDF works as-is as well, EPS needs the poppler library but then works the same way
For excessive margins in the output PDFs:]
fig.update_layout( margin=dict(l=20, r=20, t=20, b=20), )Overleaf antialiasing blurry when viewing
When including a PDF plot, I get this sometimes:

This is a problem only when viewing the PDF inside qutebrowser/Overleaf, in a normal PDF viewer it’s fine!
-
Day 1633 (22 Jun 2023)
Vaex iterate through groups
Didn’t find this in the documentation, but:
gg = ds.groupby(by=["species"]) lg = next(gg.groups) # lg is the group name tuple (in this case of one string) group_df = gg.get_group(lg)
-
Day 1632 (21 Jun 2023)
Zotero web version for better tabs + split view
Web zotero
Looking for a way to have vertical/tree tabs, I found a mention of the zotero web version being really good.
Then you can have multiple papers open (with all annotations etc.) in different browser tabs that can be easily navigated using whatever standard thing one uses.
You can read annotations but not edit them. Quite useful nonetheless!
Split view
PDF reader feature request: open the same pdf twice in split screen - Zotero Forums: View -> Split Horizontally/Vertically!
It’s especially nice for looking at citations in parallel to the text.
Overleaf bits
Shortcuts
vim!
EDIT 2023-12-05 Overleaf has Vim bindings! Enable-able in the project menu. There are unofficially supported ways to even make custom bindings through TamperMonkey
Shortcuts
Kurz und gut
- Ctrl+Enter compiles the project
- Bold/italic work as expected,
<C-b/i>. Same for copypaste etc. - Advanced reference search: is cool.
- Comments:
<C-/>for adding%-style LaTex comments.<C-S-c>for adding Overleaf comments
Bible
Overleaf Keyboard Shortcuts - Overleaf, Online LaTeX Editor helpfully links to a PDF, screenshots here:
It seems to have cool multi-cursor functionality that might be worth learning sometime.
Templates
Overleaf has a lot of templates: Templates - Journals, CVs, Presentations, Reports and More - Overleaf, Online LaTeX Editor
If your conference’s is missing but it sends you a .zip, you can literally import it as-is in Overleaf, without even unpacking. Then you can “copy” it to somewhere else and start writing your paper.
Bits and pieces
- Renaming the main file to sth like
0paper.texmakes it appear on top, easier to find.
-
Day 1618 (07 Jun 2023)
You can add underscores to numbers in Python
TIL that for readability,
x = 100000000can be written asx = 100_000_000etc.! Works for all kinds of numbers - ints, floats, hex etc.!1