serhii.net
In the middle of the desert you can say anything you want
-
Day 1569 (19 Apr 2023)
Gitlab container registries etc.
Gitlab makes stuff really easy to use by providing copy-pasteable commands!
The container registry, when empty, shows that you basically need to build and push a Docker image to the registry to make it not-empty. I guess you just enable it and you’re set.
-
Day 1540 (20 Mar 2023)
Latex adding Inputs and Outputs to an algorithmsx environment
algorithm2e - How to add input and output before algorithm procedure - TeX - LaTeX Stack Exchange:
... \hspace*{\algorithmicindent} \textbf{Input} \\ \hspace*{\algorithmicindent} \textbf{Output} \begin{algorithmic}[1]also:
% rename `for all` into `for each` \renewcommand{\algorithmicforall}{\textbf{for each}} % remove leading triangle-thing-symbol from comments \algrenewcommand{\algorithmiccomment}[1]{\hfill#1}
-
Day 1539 (19 Mar 2023)
M paper bits
- Q2 papers:
- Halicek et al. Tumor detection of the thyroid and salivary glands using hyperspectral imaging and deep learning. Biomed Opt Express. 2020 Feb 18;11(3):1383-1400. doi: 10.1364/BOE.381257. PMID: 32206417; PMCID: PMC7075628.
- Tumor detection of the thyroid and salivary glands using hyperspectral imaging and deep learning
- 2.2.1 diff normalization method:

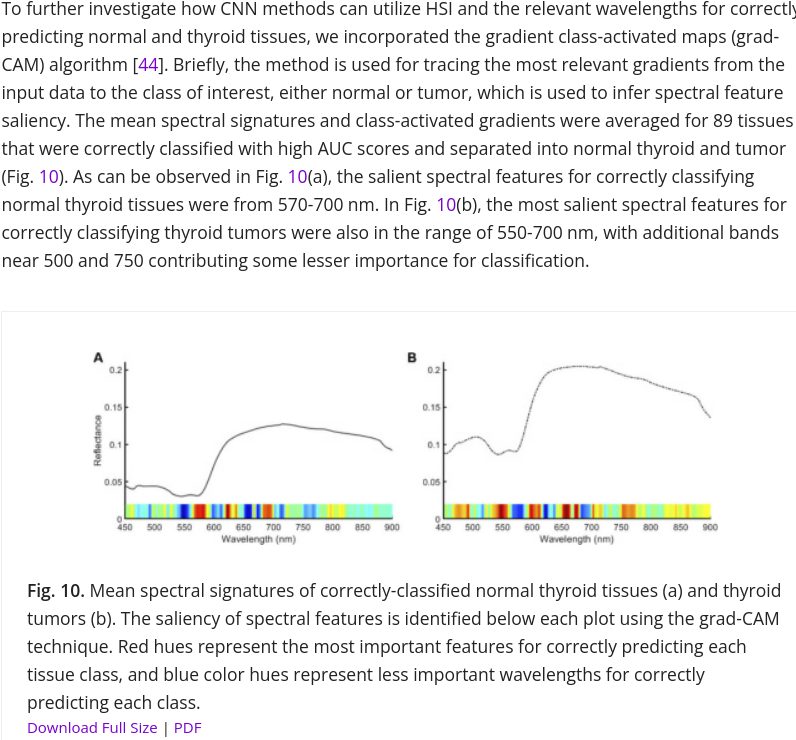
- Милая картинка спектров больных и не-больных
- 2.5 uses Inception-v4 CNN, но его тоже немного видоизменили
- Metrics: AUC but also sensitivity/specificity
- Results 3.1 тоже использует метод для нахождения самых крутых wavelengths!
-
- Suggested inclusion:
- Lines 64-66, before/after:
- Convolutional neuronal networks (CNN) were used to classify ex vivo and in vivo head and neck tumors, colorectal cancer, esophagogastric cancer and brain tumors [25, 26, 27].
- Convolutional neuronal networks (CNN) were used to classify ex vivo and in vivo head and neck tumors, colorectal cancer, esophagogastric cancer, and brain, thyroid, and salivary tumors [25, 26, 27, XXXX].
- 453:
- There are several wavelengths that are significant for both architectures: 585, 605, 610, 670, 750, 875, 975 nm. In future work it would be interesting to research why these exact wavelengths have such a strong influence.
- There are several wavelengths that are significant for both architectures: 585, 605, 610, 670, 750, 875, 975 nm. They are similar but not identical to the salient features for thyroid tumor calculated using the grad-CAM algorithm1. In future work it would be interesting to calculate the salient features using the grad-CAM algorithm and other approaches, and research why these exact wavelengths have such a strong influence.
- Если хотим, можем еще добавить про “было бы интересно еще сделать three-bands RGB multiplex images которые вон в той работе были лучше чем hyperspectral для отдельных классов рака”
- Lines 64-66, before/after:
- Fabelo et al. Surgical Aid Visualization System for Glioblastoma Tumor Identification based on Deep Learning and In-Vivo Hyperspectral Images of Human Patients. Proc SPIE Int Soc Opt Eng. 2019 Feb;10951:1095110. doi: 10.1117/12.2512569. Epub 2019 Mar 8. PMID: 31447494; PMCID: PMC6708415.
- Surgical Aid Visualization System for Glioblastoma Tumor Identification based on Deep Learning and In-Vivo Hyperspectral Images of Human Patients - PMC
- Brain cancer
- CNN but not Inception, но у них ОК результаты и с DNN
- Они отдельно имеют класс для hypervascularized, то есть вены и кровяка, и работают с ними отдельно. Отсылаются на работу на касательную тему как раз на colorectal cancer.
- Figure 6:
- в их программе хирург лично вручную определяет thresholds для классов! Т.к. не с чем сравнить для каждого нового пациента (как понимаю то же отсутствие тест датасета условно). То, что ты типа автоматизировала:
Finally, since the computation of the optimal operating point cannot be performed during the surgical procedures due to the absence of a golden standard of the undergoing patient, a surgical aid visualization system was developed to this end (Figure 6). In this system, the operating surgeon is able to determine the optimal result on the density map by manually adjusting the threshold values of the tumor, normal and hypervascularized classes. These threshold values establish the minimum probability where the pixel must correspond to a certain class in the classification map generated by the 1D-DNN
- в их программе хирург лично вручную определяет thresholds для классов! Т.к. не с чем сравнить для каждого нового пациента (как понимаю то же отсутствие тест датасета условно). То, что ты типа автоматизировала:
- SUGGESTED CHANGES:
- Добавить отсылку на него в самый конец 64-66, тоже пример brain cancer
- 168:
- The need in thresholding raises the question about choosing an optimal threshold that maximizes the evaluation metrics.
- The need in thresholding raises the question about choosing an optimal threshold. Different methods for choosing thresholds exist, and in some cases one can even be manually selected for each individual case[XXX]. For our case, we needed a threshold that maximizes the evaluation metrics, and therefore needed an automatic approach.
- Rajendran et al. Hyperspectral Image Classification Model Using Squeeze and Excitation Network with Deep Learning. Comput Intell Neurosci. 2022 Aug 4;2022:9430779. doi: 10.1155/2022/9430779. PMID: 35965752; PMCID: PMC9371828.
- Hyperspectral Image Classification Model Using Squeeze and Excitation Network with Deep Learning
- Техническая low-level про разные методы и сети. Суть - придумать как использовать deep learning для сложной HSI data structure и как extract features оттуда. Якобы работает лучше чем Inception and friends:
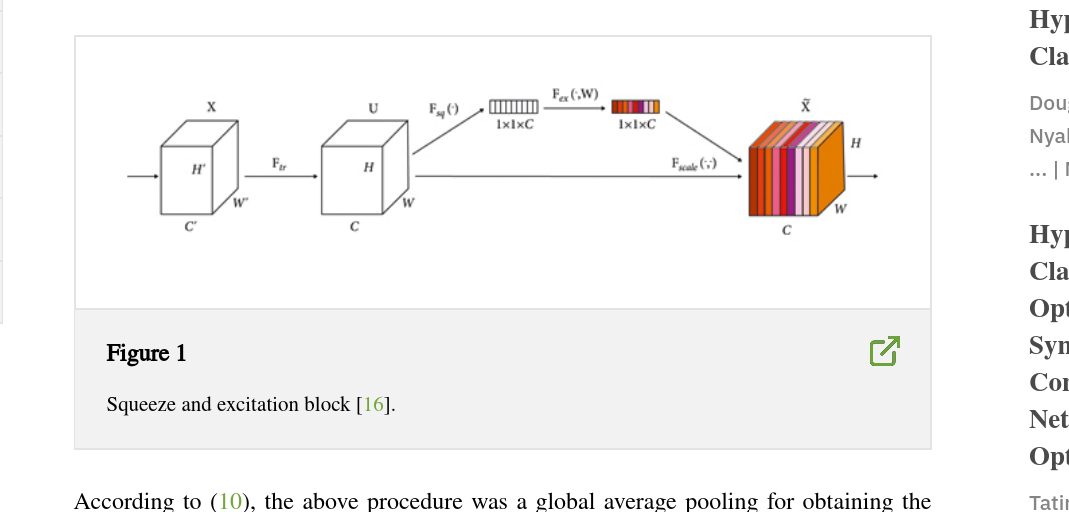
- Основное: squeeze-and-excitation-blocks которые акцентируют key features!
- SUGGESTED CHANGES:
- 77-79
- Several approaches to improve artificial networks were considered, such as testing different pre-processing steps (e.g. normalization) [26] and architectures (e.g. CNN) [28].
- Several approaches to improve artificial networks were considered, such as testing different pre-processing steps (e.g. normalization) [26] and architectures (e.g. CNN [28], also in combination with squeeze-and-excitation networks[XXX]).
- 453 добавить в конец:
- Lastly, squeeze-and-excitation blocks[XXX] apply varying weight ratios to emphasize such target key features and eliminate unnecessary data, and methods based on this approach could, too, provide additional context on the topic.
- 77-79
- Hong et al. Monitoring the vertical distribution of HABs using hyperspectral imagery and deep learning models. Sci Total Environ. 2021 Nov 10;794:148592. doi: 10.1016/j.scitotenv.2021.148592. Epub 2021 Jun 19. PMID: 34217087.
- Monitoring the vertical distribution of HABs using hyperspectral imagery and deep learning models - ScienceDirect - but no full text
- Водоросли
- Inception-v3, Resnet etc., у них ResNet-18 работает лучше всего и дают еще примеры где это так
-
- Тоже использует Grad-CAM с первой статьи для key features!
- SUGGESTED CHANGES:
- 416, добавить в конец:
Additionally, Inception-based networks don’t perform better in all HSI applications, and this seems to be dataset-dependent. For example ResNet-18 had a higher accuracy than Inception-v3 in the case of HSI-based harmful algae blooms detection[XXX].RS != ResNet, haha.- OPTIONALLY еще примеры с той работы, например про не-HSI болезни помидоров2
- 416, добавить в конец:
- Halicek et al. Tumor detection of the thyroid and salivary glands using hyperspectral imaging and deep learning. Biomed Opt Express. 2020 Feb 18;11(3):1383-1400. doi: 10.1364/BOE.381257. PMID: 32206417; PMCID: PMC7075628.
- R1 l. 79 “post-processing is an important step”: expand on already existing post-processing techniques
- Relevant article: https://www.mdpi.com/2072-4292/14/20/5199
-
In this paper, we explore the effects of degraded inputs in hyperspectral image classification including the five typical degradation problems of low spatial resolution, Gaussian noise, stripe noise, fog, and shadow. Seven representative classification methods are chosen from different categories of classification methods and applied to analyze the specific influences of image degradation problems.
-
- Doesn’t have salt-and-pepper-noise as type of degratations in PREprocessing, for post-processing lists really nice ways to sort out the unclear border things.
In postprocessing methods, the raw classification map is often calculated from a pixelwise HSI classification approach and then optimized according to the spatial dependency [26]. References [27,28] used the Markov random fields (MRF) regularizer to adjust the classification results obtained by the MLR method in dynamic and random subspaces, respectively. In order to optimize the edges of classification results, Kang et al. [29] utilized guidance images on the preliminary class-belonging probability map for edge-preserving. This group of strategies can better describe the boundary of classification objects, remove outliers, and refine classification results
- CHANGES on line 77-80 (includes changes from the third paper above!):
-
Several approaches to improve artificial networks were considered, such as testing different pre-processing steps (e.g. normalization) [26] and architectures (e.g. CNN) [28]. Recent studies showed that post-processing is an important step in ML pipelines [29].
-
Several approaches to improve artificial networks were considered, from testing different architectures (e.g. CNN [28], also in combination with squeeze-and-excitation networks[XXX]), to testing different pre-processing (e.g. normalization)[26] or post-processing steps.[29].
In particular, postprocessing is often used to optimize a raw pixelwise classification map, using various methods, e.g. using guidance images for edge-preserving, as part of a group of strategies used to better define the boundaries of classification objects, remove outliers, refine classification results. In particular, Edge Preserving Filtering (EPF)3 has been shown to improve the classification accuracy significantly in a very short time. Another approach is the use of a Markov Random Field (MRF)4, where the class of each pixel is determined based on the probability of the pixel itself, the adjacent pixels, and the solution of a minimization problem.
-
- Relevant article: https://www.mdpi.com/2072-4292/14/20/5199
-
- R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra, “Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization,” Proc IEEE Int Conf Comput Vis, 618–626 (2017).
-
Applied Sciences | Free Full-Text | Comparison of Convolutional Neural Network Architectures for Classification of Tomato Plant Diseases ↩︎
-
29 / Kang, X.; Li, S.; Benediktsson, J.A. Spectral–Spatial Hyperspectral Image Classification with Edge-Preserving Filtering. IEEE Trans. Geosci. Remote Sens. 2014, 52, 2666–2677. [Google Scholar] [CrossRef] ↩︎
-
86 / Tarabalka, Y.; Fauvel, M.; Chanussot, J.; Benediktsson, J.A. SVM- and MRF-Based Method for Accurate Classification of Hyperspectral Images. IEEE Geosci. Remote Sens. Lett. 2010, 7, 736–740. [Google Scholar] [CrossRef][Green Version] ↩︎
- Q2 papers:
-
Day 1538 (18 Mar 2023)
Detecting letters with Fourier transforms
TIL from my wife in the context of checkbox detection! letters detection fourier transform – Google Suche
- Introduction to the Fourier Transform for Image Processing
-
- crowoy/Letter-Recognition: Fourier Feature Analysis - Classifying letters [S,T,V] based on features in the Fourier Space
TL;DR you can use fourier transforms on letters, that then lead to differentiable results! Bright lines perpendicular to lines in the original letter etc.
My link wiki's rebirth into Hugo, final write-up
Good-bye old personal wiki, AKA Fiamma. Here are some screenshots which will soon become old and nostalgic:
I’ve also archived it, hopefully won’t turn out to be a bad idea down the line (but that ship has sailed long ago…):
- archive.is: Fiamma (PKM and links wiki) - Fiamma
- web.archive.org: Fiamma (PKM and links wiki) - Fiamma
Will be using the Links blog from now on: https://serhii.net/links
- Introduction to the Fourier Transform for Image Processing
-
Day 1537 (17 Mar 2023)
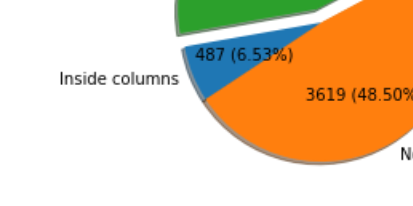
matplotlib labeling pie-charts
python - How to have actual values in matplotlib Pie Chart displayed - Stack Overflow:
def absolute_value(val): a = numpy.round(val/100.*sizes.sum(), 0) return a plt.pie(sizes, labels=labels, colors=colors, autopct=absolute_value, shadow=True)Can be also used to add more complex stuff inside the wedges (apparently the term for parts of the ‘pie’).
I did this:
def absolute_value(val): a = int(np.round(val/100.*np.array(sizes).sum(), 0)) res = f"{a} ({val:.2f}%)" return resfor this:
Notes after writing a paper
Based on feedback on a paper I wrote:
- Finally learn stop using “it’s” instead of “its” for everything and learn possessives and suff
- Don’t use “won’t”, “isn’t” and similar short forms when writing a scientific paper. “Will not”, “is not” etc.
- ‘“Numbered”’ lists with “a), b), c)” exist and can be used along my usual bullet-point-style ones
-
Day 1533 (13 Mar 2023)
micro is a simple single-file CLI text editor
Stumbled upon zyedidia/micro: A modern and intuitive terminal-based text editor. Simple text editor that wants to be the successor of nano, CLI-based. The static .tar.gz contains an executable that can be directly run. Played with it for 30 seconds and it’s really neat**.
(Need something like vim for someone who doesn’t like vim, but wants to edit files on servers in an easy way in case nano isn’t installed and no sudo rights.)
json diff with jq, also: side-by-side output
Websites
There are online resources:
- JSON Diff - Online JSON Compare Diff Finder
- JSON Diff - The semantic JSON compare tool is a bit prettier All similar to each other. I don’t find them intuitive, don’t like copypasting, and privacy/NDAs are important.
CLI
SO thread1 version:
diff <(jq --sort-keys . A.json) <(jq --sort-keys . B.json)Wrapped it into a function in my
.zshrc:jdiff() { diff <(jq --sort-keys . "$1") <(jq --sort-keys . "$2") }Side-by-side output
vimdiffis a thing and does this by default!Otherwise2 diff has the parameters
-y, and--suppress-common-linesis useful.This led to
jdiff’s brotherjdiffy:jdiffy() { diff -y --suppress-common-lines <(jq --sort-keys . "$1") <(jq --sort-keys . "$2") }Other
git diff --no-indexallows to use git diff without the thing needing to be inside a repo. Used it heavily previously for some of its fancier functions. Say hi togdiff:gdiff() { git diff --no-index "$1" "$2" }
xlsxgrep for grepping inside xls files
This is neat: xlsxgrep · PyPI
Supports many grep options.