serhii.net
In the middle of the desert you can say anything you want
-
Day 1316 (09 Aug 2022)
Pycharm pytest logging settings
Pytest logging in pycharm
In Pycharm running config, there are options to watch individual log files which is nice.
But the main bit - all my logging issues etc. were the fault of Pycharm’s Settings for pytest that added automatically a
-qflag. Removed that checkmark and now I get standard pytest output that I can modify!And now
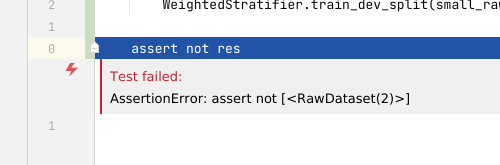
caplog1 works:def test_split_ds(caplog): caplog.set_level(logging.DEBUG, logger="anhaltai_bbk.data.train_dev_splitter.splitter") caplog.set_level(logging.DEBUG) # ...Dropping into debugger on uncaught exception + pytest plugin
So, previously I thought about this here: 220214-1756 python run pdb on exception
Anyway, solution was on pytest level, installing this package was the only thing needed: pytest-pycharm · PyPI
Installed it at the same time as this pycharm plugin, might’ve been either of the two:
pytest imp - IntelliJ IDEA & PyCharm Plugin | Marketplace / theY4Kman/pycharm-pytest-imp: PyCharm pytest improvements plugin
Anyway now life’s good:
Creating representative test sets
Thinking out loud and lab notebook style to help me solve a problem, in this installment - creating representative train/test splits.
Problem
Goal: create a test set that looks like the train set, having about the same distribution of labels.
In my case - classic NER, my training instances are documents whose tokens can be a number of different labels, non-overlapping, and I need to create a test split that’s similar to the train one. Again, splitting happens per-document.
Added complexity - in no case I want tags of a type ending up only in train or only in test. Say, I have 100 docs and 2 ORGANIZATIONs inside them - my 20% test split should have at least one ORGANIZATION.
Which is why random selection doesn’t cut it - I’d end up doing Bogosort more often than not, because I have A LOT of such types.
Simply ignoring them and adding them manually might be a way. Or intuitively - starting with them first as they are the hardest and most likely to fail
Implementation details
My training instance is a document that can have say 1 PEOPLE, 3 ORGANIZATIONS, 0 PLACES.
For each dataset/split/document, I have a dictionary counting how many instances of each entity does it have, then changed it to a ratio “out of the total number of labels”.
{ "O": 0.75, "B-ORGANIZATION": 0.125, "I-ORGANIZATION": 0, "B-NAME": 0, "I-NAME": 0, }I need to create a test dataset with the distribution of these labels as close as the train dataset. In both, say, 3 out of 4 labels should be
"O".So - “which documents do I pick so that when their labels are summed up I get a specific distribution”, or close to it. So “pick the numbers from this list that sum up close to X”, except multidimensional.
Initial algo was “iterate by each training instance and put it in the pile it’ll improve the most”.
Started implementing something to do this in
HuggingFace Datasets , and quickly realized that “add his one training instance to this HFDataset” is not trivial to do, and iterating through examples and adding them to separate datasets is harder than expected.“Reading the literature”
Generally we’re in the area of concepts like Subset sum problem / Optimization problem / Combinatorial optimization
Scikit-learn
More usefully, specifically RE datasets, How to Create a Representative Test Set | by Dimitris Poulopoulos | Towards Data Science mentioned sklearn.model_selection.StratifiedKFold.
Which led me to sklearn’s “model selection” functions that have a lot of functions doing what I need! Or almost
API Reference — scikit-learn 1.1.2 documentation
And the User Guide specifically deals with them: 3.1. Cross-validation: evaluating estimator performance — scikit-learn 1.1.2 documentation
Anyway - StratifiedKFold as implemented is “one training instance has one label”, which doesn’t work in my case.
My training instance is a document that has 1 PEOPLE, 3 ORGANIZATIONS, 0 PLACES.
Other places
Dataset Splitting Best Practices in Python - KDnuggets
Brainstorming
Main problem: I have multiple labels/
ys to optimize for and can’t directly use anything that splits based on a single Y.Can I hack something like sklearn.model_selection.StratifiedGroupKFold for this?
Can I read about how they do it and see if I can generalize it? (Open source FTW!) scikit-learn/_split.py at 17df37aee774720212c27dbc34e6f1feef0e2482 · scikit-learn/scikit-learn
Can I look at the functions they use to hack something together?
… why can’t I use the initial apporach of adding and then measuring?
Where can I do this in the pipeline? In the beginning on document level, or maybe I can drop the requirement of doing it per-document and do it at the very end on split tokenized training instances? Which is easier?
Can I do a random sample and then add what’s missing?
Will going back to numbers and “in this train set I need 2 ORGANIZATIONS” help me reason about it differently than the current “20% of labels should be ORGANIZATION”?
Looking at vanilla StratifiedKFold
scikit-learn/_split.py at 17df37aee774720212c27dbc34e6f1feef0e2482 · scikit-learn/scikit-learn
They sort the labels and that way get +/- the number of items needed. Neat but quite hard for me to adapt to my use case.
OK, NEXT
Can I think of this as something like a sort with multiple keys?..
Can I use the rarity of a type as something like a class weight? Ha, that might work. Assign weights in such a way that each type is 100 and
This feels relevant. Stratified sampling - Wikipedia
Can I chunk them in small pieces and accumulate them based on the pieces, might be faster than by using examples?
THIS looked like something REALLY close to what I need, multiple category names for each example, but ended up being the usual stratified option I think:
This suggests to multiply the criteria and get a lot of bins - not what I need but I keep moving
Can I stratify by multiple characteristics at once?
I think “stratification of multilabel data” is close to what I need
Found some papers, yes this is the correct term I think
scikit-multilearn
YES! scikit-multilearn: Multi-Label Classification in Python — Multi-Label Classification for Python
scikit-multilearn: Multi-Label Classification in Python — Multi-Label Classification for Python
scikit-multilearn: Multi-Label Classification in Python — Multi-Label Classification for Python:
In multi-label classification one can assign more than one label/class out of the available n_labels to a given object.
This is really interesting, still not EXACTLY what I need but a whole new avenue of stuff to look at
scikit-multilearn: Multi-Label Classification in Python — Multi-Label Classification for Python
The idea behind this stratification method is to assign label combinations to folds based on how much a given combination is desired by a given fold, as more and more assignments are made, some folds are filled and positive evidence is directed into other folds, in the end negative evidence is distributed based on a folds desirability of size.
Yep back to the first method!
They link this lecture explaining the algo: On the Stratification of Multi-Label Data - VideoLectures.NET
That video was basically what I needed
Less the video than the slides, didn’t watch the video and hope I won’t have to - the slides make it clear enough.
Yes, reframing that as “number of instances of this class that are still needed by this fold” was a better option. And here binary matrices nicely expand to weighted stratification if I have multiple examples of a class in a document. And my initial intuition of starting with the least-represented class first was correct
Basic algorithm:
- Get class with smallest number of instances in the dataset
- Get all training examples with that class and distribute them first
- Go to next class
Not sure if I can use the source of the implementation: scikit-multilearn: Multi-Label Classification in Python — Multi-Label Classification for Python
I don’t have a good intuition of what they mean by “order”, for now “try to keep labels that hang out together in the same fold”? Can I hack it to
I still have the issue I tried to avoid with needing to add examples to a fold/
Dataset, but that’s not the problem here.Generally - is this better than my initial approach?
What happens if I don’t modify my initial approach, just the order in which I give it the training examples?
Can I find any other source code for these things? Ones easier to adapt?
Anyway
I’ll implement the algo myself based on the presentation and video according to my understanding.
The main result of this session was finding more related terminology and a good explanation of the algo I’ll be implementing, with my changes.
I’m surprised I haven’t found anything NER-specific about creating representative test sets based on the distribution of multiple labels in the test instances. Might become a blog post or something sometime.jj
-
Day 1315 (08 Aug 2022)
Huggingface datasets set_transform
Previously: 220601-1707 Huggingface HF Custom NER with BERT
So you have the various mapping functions, but there’s a
set_transformwhich executes a transform whengetitem()is called.
-
Day 1310 (03 Aug 2022)
Slurm pyxis using a docker
If I sent you a link to this you probably want the TL;DR at the bottom
Context
Previously: 220712-2208 Slurm creating modifiable persistent container
Problem: I have a docker image in a private docker registry that needs user/pass.
I need to use it in
slurm’spyxis.The default
srun --container-image ..syntax has no obvious place for a Docker registry user/pass.Trying to use an image from a private registry does this:
$ srun --mem=16384 -c2 --gres=gpu:v100:2 --container-image comp/myimage:latest slurmstepd: error: pyxis: child 2505947 failed with error code: 1 slurmstepd: error: pyxis: failed to import docker image slurmstepd: error: pyxis: printing contents of log file ... slurmstepd: error: pyxis: [INFO] Querying registry for permission grant slurmstepd: error: pyxis: [INFO] Authenticating with user: <anonymous> slurmstepd: error: pyxis: [INFO] Authentication succeeded slurmstepd: error: pyxis: [INFO] Fetching image manifest list slurmstepd: error: pyxis: [INFO] Fetching image manifest slurmstepd: error: pyxis: [ERROR] URL https://registry-1.docker.io/[...] returned error code: 401 UnauthorizedSlurm’s pyxis1 uses
enroot2 to do the container magic that includes interfacing with Docker.enrootis installed on the box, Docker isn’t, I have no root access.Option/attempt 1: Using enroot config to pass a credentials file
I need to pass through
srunconfigs to enroot, so it can access the docker registry.To pass credentials to it, create a credentials file in
$ENROOT_CONFIG_PATH/.credentials:# DockerHub machine auth.docker.io login <login> password <password>That env var is not set in the base system, set it to
/home/me/enroot/and put the file there - same (no) result.After googling, found this really detailed thread about the way
pyxishandles environment variables: enroot/import.md at master · NVIDIA/enroot Especially this specific comment: pyxis doesn’t use environment variables defined in enroot .env files · Issue #46 · NVIDIA/pyxisSo basically,
enrootandpyxisare behaving in opposite ways:- if a ‘dynamic’ env var is defined in
enrootconf files,enrootpasses it to the container, but notpyxis - if it’s not defined in
enrootconf files,enrootdoesn’t pass it to the container, butpyxisdoes.
I don’t have write access to the enroot config files, but the
$ENROOT_CONFIG_PATHisn’t set there, I should be able to change it. No effect though.Giving up for now, though that would’ve been the most beautiful solution.
Attempt 2: Get the image separately through
enrootI could use pure
enrootto get the docker image, then pass the file tosrun.Run “Docker” Containers with NVIDIA Enroot
To use a oath authentication and a token you would need to sign-up/sign-in and create a token (which you can save for reuse) and then do the container import as,
enroot import 'docker://$oauthtoken@nvcr.io#nvidia/tensorflow:21.04-tf1-py3'Awesome, let’s create a token and try:
… okay, what’s the address of the docker hub? The
hub.docker.comone that’s default and ergo not used anywhere, but I need to pass it explicitly?..Anyway let’s try to get bitnami/minideb from a public repo to pin the syntax down.
hub.docker.comreturned 404s, trial and error led me todocker.io:[INFO] Querying registry for permission grant [INFO] Permission granted [INFO] Fetching image manifest list [ERROR] Could not process JSON input curl: (23) Failed writing body (1011 != 4220)registry-1.docker.ioactually asked me for a password!enroot import 'docker://$token@registry-1.docker.io#bitnami/minideb:latest' [INFO] Querying registry for permission grant [INFO] Authenticating with user: $token Enter host password for user '$token': [ERROR] URL https://auth.docker.io/token returned error code: 401 UnauthorizedWithout providing the token the image gets downloaded! Then I found
index.docker.io3 that seems to be the correct one.Okay, let’s get my private one
me@slurm-box:/slurm/me$ ENROOT_CONFIG_PATH=/home/me/enroot enroot import 'docker://index.docker.io#comp/myimage:latest'401 error unauthorized, still ignoring my
.credentialsor env variable pointing to it.Docker username only:
enroot import 'docker://mydockerusername@index.docker.io#comp/myimage:latest'Asks me for a password and then imports correctly! And creates a file called
myimage.sqshin the current dir.Woohoo, working way to get docker images from private registry!
$ enroot start myimage.sqsh enroot-nsenter: failed to create user namespace: Operation not permittedOkay, so I’m not allowed to start them with
enroot- not that I had any reason to.srun --mem=16384 -c4 --gres=gpu:v100:2 --container-image ./Docker/myimage.sqsh --container-mounts=/slurm/$(id -u -n)/data:/data --container-workdir /data --pty bashDrops me inside a shell in the container - it works!
Next step - using the Docker token.
Docker seems to see it as password replacement, this conflicts with official docus:
# Import Tensorflow 19.01 from NVIDIA GPU Cloud $ enroot import --output tensorflow.sqsh 'docker://$oauthtoken@nvcr.io#nvidia/tensorflow:19.01-py3'On further googling - that’s a thing specific for
nvcr.io, Docker Hub uses Docker stuff and I use that token as password replacement, period. Okay.Had issues with mounting stuff as
/databy default, but that specific bit is used in the docker image too - used something else.The Dockerfile also has an
ENTRYPOINTandsbinwants something to execute,truecan be passed. Couldn’t get this to work, notruemeanssbinrefuses to start, passingtruemakes it ignore the entrypoint altogether.--[no-]container-entrypointfrom docu didn’t help - leaving for later.Final line:
srun --mem=16384 -c4 --gres=gpu:v100:2 --container-image ./Docker/myimage.sqsh --container-mounts=/slurm/$(id -u -n)/data:/SLURMdata --container-writable python3 -m trainer_module -i /data/ -o /SLURMdata/Checkpoints/ --config-file /SLURMdata/config.yamlThis:
- makes the image writable, so huggingface and friends can download stuff
- makes
/slurm/me/dataavailable as/SLURMdatainside the image; - passes a config file to it that I have inside
/data/config.yamlto the trainer (that accesses it as/SLURMdata/config.yaml) - runs the training on a dataset inside the directory that the Dockerfile puts inside
/datain the image itself (the one that conflicted with mine earlier), - puts training results in a directory inside
/SLURMdatawhich means it’s available to me aftersbinis done in my/slurm/me/datadirectory.
TODO / for later
- Try again to find a way to use a
.credentialsfile, one command less to run then - How to run my docker image’s
ENTRYPOINT
(More) resources
- Enroot
importtutorial/help: enroot/import.md at master · NVIDIA/enroot - Really detailed about pure-enroot Docker bits, superset of the prev. link: Run “Docker” Containers with NVIDIA Enroot
pyxishas more detailed usage guides! Especially this one: Usage · NVIDIA/pyxis Wiki- Extremely detailed/useful discussion about pyxis/enroot environment variables:pyxis doesn’t use environment variables defined in enroot .env files · Issue #46 · NVIDIA/pyxis
- Slurm with Docker and examples of doing Jupyter Notebook: Containers - NHR@KIT User Documentation
- Docker best practices, esp.
ENTRYPOINT: Best practices for writing Dockerfiles | Docker Documentation
TL;DR
Two ways I found, passing credentials for the docker registry didn’t work, separately downloading the image and then running it did. Read the entire post if you want details on most of this.
Getting the image:
enroot import 'docker://mydockerusername@index.docker.io#comp/myimage:latest'Replace
mydockerusernamewith your docker username,compwith companyname andmyimagewith the name of the image.It will ask you for your Docker pass or Personal Access Token.
Will download the image into a
*.sqshfile in the current directory or whatever you pass through the-oparameter.Running the image
srun --mem=16384 -c4 --gres=gpu:v100:2 --container-image ./Docker/myimage.sqsh --container-mounts=/slurm/$(id -u -n)/data:/SLURMdata --container-writable your_command_to_run # or - if you are running the thing I'm running - ... srun --mem=16384 -c4 --gres=gpu:v100:2 --container-image ./Docker/myimage.sqsh --container-mounts=/slurm/$(id -u -n)/data:/SLURMdata --container-writable python3 -m trainer_module -i /data/ -o /SLURMdata/Checkpoints/ --config-file /SLURMdata/config.yamlIn decreasing order of interest/generality:
- pass the downloaded
*.sqshfile to--container-image. - Environment variables get passed as-is in most cases. If you’d do
docker run --env ENV_VAR_NAME, here you’d sayENV_VAR_NAME=whatever srun ...or justexport ...it before running and it should work. --container-writableis needed to make the filesystem writable, huggingface needs that to write cache files--container-mounts- are
/dir_in_your_fs:/dir_inside_docker_image - Make sure the Docker itself doesn’t have anything unexpected located at
/dir_inside_docker_image
- are
- if a ‘dynamic’ env var is defined in
-
Day 1303 (27 Jul 2022)
Huggingface dataset analysis tool
- DataMeasurementsTool - a Hugging Face Space by huggingface
- Introducing the Data Measurements Tool: an Interactive Tool for Looking at Datasets
Really nice, and the blog post introducing it has a lot of general info about datasets that I found very interesting.
-
Day 1302 (26 Jul 2022)
Python typing classmethods return type
From python - How do I type hint a method with the type of the enclosing class? - Stack Overflow:
If you have a classmethod and want to annotate the return value as that same class you’re now defining, you can actually do the logical thing!
from __future__ import annotations class Whatever: # ... @classmethod what(cls) -> Whatever: return cls()
Inter-annotator agreement (IAA) metrics
Kohen’s Kappa
- sklearn.metrics.cohen_kappa_score — scikit-learn 1.1.1 documentation
- Extremely clear explanation: Cohen’s Kappa Statistic - Statistics How To
- Cohen’s Kappa. Understanding Cohen’s Kappa coefficient | by Kurtis Pykes | Towards Data Science
- Important bits:
- It includes the likelihood that a correct guess happens randomly
- Only 2 annotators
- Compares classification on the same items - so as input it gets y_1 and y_2 of the same length with matching annos
Python dataclass libraries, pydantic and dataclass-wizard
It started with writing type hints for a complex dict, which led me to TypedDict, slowly went into “why can’t I just do a dataclass as with the rest”.
Found two libraries:
- pydantic
- Really nice esp. for validation
MyClass(**somedict)- Couldn’t find an easy way to parse nested dataclasses from the same dict
- Dataclass Wizard
- Basically a wrapper to read/save (nested!) dataclasses from dicts / json.
- Does one thing and does it well!
- When dumping, converted my
field_namesto camelcasefieldNames, one can disable that from settings: Extending from Meta — Dataclass Wizard 0.22.1 documentation
-
Day 1301 (25 Jul 2022)
Python for..else syntax
TIL another bit I won’t ever use: 21. for/else — Python Tips 0.1 documentation
This exists:
for a in whatveer: a.whatever() else: print("Whatever is empty!")Found it after having a wrong indentation of an
elsethat put it inside theforloop.
-
Day 1298 (22 Jul 2022)
Python interval libraries
Found at least three:
- portion · PyPI
- Seems to be more about operations
- GitHub - brentp/interlap: fast, pure-python interval overlap testing
- More focused on querying
- intervaltree · PyPI
- Too about querying
- portion · PyPI