serhii.net
In the middle of the desert you can say anything you want
-
Day 2238 (15 Feb 2025)
Git change name or email in commit history
This is brilliant: Git, rewrite previous commit usernames and emails - Stack Overflow
TL;DR
git config --global alias.change-commits '!'"f() { VAR=\$1; OLD=\$2; NEW=\$3; shift 3; git filter-branch --env-filter \"if \\\"\$\`echo \$VAR\`\\\" = '\$OLD' ; then export \$VAR='\$NEW'; fi\" \$@; }; f"Then
git change-commits GIT_AUTHOR_NAME "old name" "new name" # last 10 commits git change-commits GIT_AUTHOR_EMAIL "old@email.com" "new@email.com" HEAD~10..HEADDepending on why I need this, I may need also
GIT_COMMITTER_[NAME/EMAIL]For multiple times, I created an
change-commit-fthat forces overwiriting the backup:git config --global alias.change-commits-f '!'"f() { VAR=\$1; OLD=\$2; NEW=\$3; shift 3; git filter-branch -f --env-filter \"if \\\"\$\`echo \$VAR\`\\\" = '\$OLD' ; then export \$VAR='\$NEW'; fi\" \$@; }; f"
A quick tldr from other answer, may be better but untested:
git config alias.change-commits '!'"f() { VAR=\$1; OLD=\$2; NEW=\$3; shift 3; git filter-branch --env-filter \"if \\\"\$\`echo \$VAR\`\\\" = '\$OLD' ; then export \$VAR='\$NEW'; fi\" \$@; }; f " git change-commits GIT_AUTHOR_NAME "<Old Name>" "<New Name>" -f git change-commits GIT_AUTHOR_EMAIL <old@email.com> <new@email.com> -f git change-commits GIT_COMMITTER_NAME "<Old Name>" "<New Name>" -f git change-commits GIT_COMMITTER_EMAIL <old@email.com> <new@email.com> -f(Previously: 220408-1822 Gitlab ‘you cannot push commits for ..’ error)
-
Day 2236 (13 Feb 2025)
Automated A-B testing
Lines of code that beat A/B testing (2012) | Hacker News / 20 lines of code that will beat A/B testing every time
TL;DR: A/B testing that automatically increases how often “good” versions are shown
-
Day 2223 (31 Jan 2025)
Annotating PDFs with INCEpTION notes
First impressions
-
- Docker works:
docker run -it --name inception -p8080:8080 ghcr.io/inception-project/inception:35.1$ docker run -it --name inception -v /srv/inception:/export -p8080:8080 ghcr.io/inception-project/inception:35.1- data will be in
/srv/inception
- data will be in
- Docker works:
-
Creating a project automatically fills it with sample data:
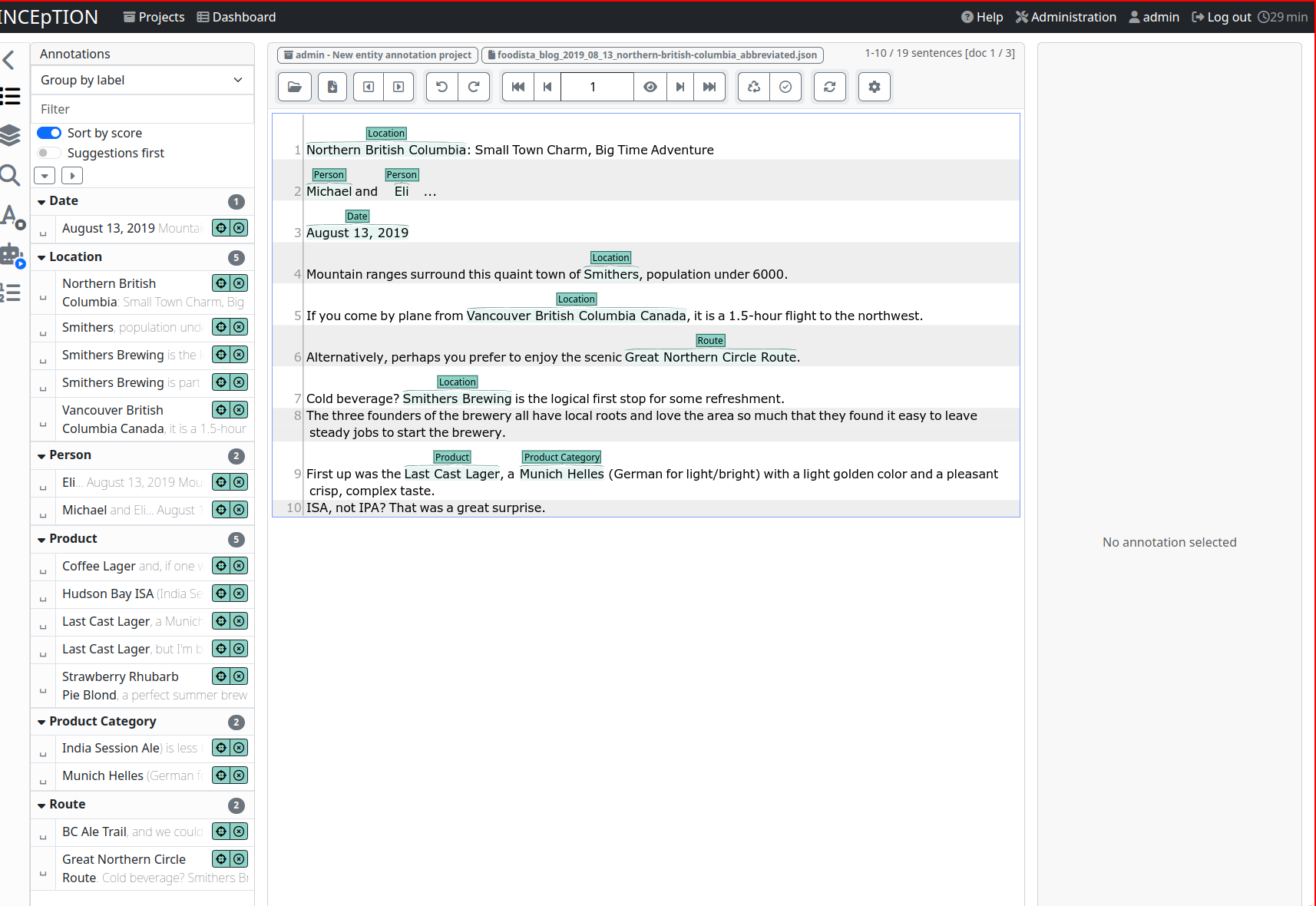
-
Tagsets
- Export format is:
{ "name" : "BBK", "description" : null, "language" : null, "tags" : [ { "tag_name" : "aaa_human_processed", "tag_description" : null }, { "tag_name" : "block", "tag_description" : null } ], "create_tag" : false }- Import format: I can get it do do only txt, one tag per line, first line is name of tagset
-
A layer has to be linked to a feature (string) which then can be linked to a tagset: (INCEpTION User Guide)
- then you can add keybindings manually
- and the “editor type” for the tag list is neat, “Radio group” works nicely for tagsets it doesn’t consider small
-
annotations get saved automatically
-
in the viewer, you can set
dynamicfor annotations differing based on color
Import/Export
- Admin->Export can
- export the entire projects
- project + separately a copy of the anntations
- To import a project: admin->projects, where you can create a new project, you can also import. You import the .zip without extraction
Features
- Supports overlapping annos
- Supports annos across page boundaries
- Doesn’t support gaps in annos!
Resources
- Not-official but really nice tutorial: 12. INCEpTION — New Languages for NLP
-
-
Day 2220 (28 Jan 2025)
Using uv as shebang line and adding requirements
Using uv as your shebang line – Rob Allen (HN comments) and more detailed article on this: Lazy self-installing Python scripts with uv
But especially Defining Python dependencies at the top of the file – Rob Allen and the PEP 723 – Inline script metadata | peps.python.org
You can add
uvto the shebang line as#!/usr/bin/env -S uv run --scriptAnd you can set requirements by adding this under the shebang line:
# /// script # requires-python = ">=3.11" # dependencies = [ # "flickrapi", # ] # ///Then you can
uv run sync-flickr-dates.pyFull package:
#!/usr/bin/env -S uv run --script # /// script # requires-python = ">=3.11" # dependencies = [ # "flickrapi", # ] # /// import flickrapi print("\nI am running")❯ chmod +x test.py ❯ ./test.py Installed 11 packages in 134ms I am running!Neat!
-
Day 2214 (22 Jan 2025)
Cherry-pick range of commits in git
git - How to cherry-pick multiple commits - Stack Overflow:
For one commit you just pase its hash.
For multiple you list them, in any order.
For a range, you dooldest-latestbut add~,^or~1to the oldest to include it. Quoting directly from the SO answer:# A. INCLUDING the beginning_commit git cherry-pick beginning_commit~..ending_commit # OR (same as above) git cherry-pick beginning_commit~1..ending_commit # OR (same as above) git cherry-pick beginning_commit^..ending_commit # B. NOT including the beginning_commit git cherry-pick beginning_commit..ending_commit
-
Day 2213 (21 Jan 2025)
Kubernetes copying files with rsync and kubectl without ssh access
So, given that
kubectl cpwas never reliable ever for me, leading to many notes here, incl. 250115-1052 Rancher much better way to copy data to PVCs with various hacks and issues like 250117-1127 Splitting files, 250117-1104 Unzip in alpine is broken issues etc. etc. etc.For many/large files, I’d have used
rsync, for which ssh access is theoretically needed. Not quite!rsync files to a kubernetes pod - Server Fault
ksync.sh(EDIT Updated by ChatGPT to support files with spaces):if [ -z "$KRSYNC_STARTED" ]; then export KRSYNC_STARTED=true exec rsync --blocking-io --rsh "$0" "$@" fi # Running as --rsh namespace='' pod=$1 shift # If user uses pod@namespace, rsync passes args as: {us} -l pod namespace ... if [ "X$pod" = "X-l" ]; then pod=$1 shift namespace="-n $1" shift fi # Execute kubectl with proper quoting exec kubectl $namespace exec -i "$pod" -- "$@"Usage is same as rsync basically :
./ksync.sh -av --info=progress2 --stats /local/dir/to/copy/ PODNAME@NAMESPACE:/target/dir/(Or just
--progressfor per-file instead of total progress).Rsync needs to be installed on server for this to work.
For flaky connections (TODO document better):
-hvvrPt --timeout1andwhile ! rsync ..; do sleep 5; done1
pipx inject library into app environment
TL;DR
pipx inject target_app package_to_inject- pipx is awesome, and can install apps in their own virtualenv
- If you try e.g.
pipx psutilit refuses, it’s a library, not an app- and tells you to use pip
- If I want
psutilfor the MemoryGraph widget in (pipx install-ed) qtile, that doesn’t help - What does:
pipx inject qtile psutil
❯ pipx inject qtile psutil injected package psutil into venv qtile done! ✨ 🌟 ✨
-
Day 2212 (20 Jan 2025)
argparse add arbitrary kwargs at the end
If no real config thingy is required/wanted, then this works (stolen from Parsing Dictionary-Like Key-Value Pairs Using Argparse in Python | Sumit’s Space)1:
def parse_args(): class ParseKwargs(argparse.Action): def __call__(self, parser, namespace, values, option_string=None): setattr(namespace, self.dest, dict()) for value in values: key, value = value.split("=") getattr(namespace, self.dest)[key] = value parser.add_argument("--no-pics", action="store_true", help="Predict only on videos") # ... parser.add_argument( "-k", "--kwargs", nargs="*", action=ParseKwargs, help="Additional inference params, e.g.: batch=128, conf=0.2.", )
-
interesting mix of topics on that website ↩︎
-
-
Day 2211 (19 Jan 2025)
arch linux low battery notification
#!/bin/bash BATTINFO=$(acpi -b) LIM="00:15:00" if grep Discharging) && $(echo $BATTINFO | cut -f 5 -d " ") < $LIM ; then # DISPLAY=:0.0 /usr/bin/notify-send "low battery" "$BATTINFO" dunstify "low battery" "$BATTINFO" fiFor this, install and run on startup
dunst, then cron job for the above.
-
Day 2209 (17 Jan 2025)
Unzip in alpine is broken
TL;DR alpine’s
unzipis busyboxes, and fails for me with/data/inference_data # unzip rd1.zip Archive: rd1.zip unzip: short readapk add unzipinstalls the same real one I have on all other computers, and then it works.