serhii.net
In the middle of the desert you can say anything you want
-
Day 2209 (17 Jan 2025)
Splitting files
E.g. to upload it somewhere where it’s hard to upload large files
See also: 250117-1104 Unzip in alpine is broken
# split split -b 2G myfile.zip part_ # back cat part_* > myfile.zip
Rancher k8s control pods execution nodes
spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: NotIn values: - node_to_avoid(
operator: Infor the list of the allowed nodes)kubectl get pods -o wideshows the nodes
-
Day 2208 (16 Jan 2025)
YOLO trainings bits
Related: 250115-1238 Adding wandb to a CLI yolo run
-
Reference are surprisingly hard to find on the website: results - Ultralytics YOLO Docs
-
yolo detect train model=yolo11s.pt data=/data/data/data.yaml project=/data/project/ epochs=500 imgsz=640 device=0,1 name=yolo11s-aug-500epochs-full -
YOLOv11 sets default batch_size 16, one can set
-1for it to automatically pick one that’s 60% of GPU, or0.8to automatically pick one that’s 80% of GPU -
To decrease verbosity in predictions,
verbose=Falsetomodel.predict()(and `.track()) works1. -
Changing
imgsz=to something lower may not necessarily make it faster, if a model was trained with a certain size it may predict faster at that size (e.g. OSCF/TrapperAI-v02.2024 predicts at 40+ iterations per second when resized to 640 and ~31 when left to its default 1024pd)- Resizing (if provided a single int, not a tuple) works by making the larger side of the image equal to the given one, if padding is needed grey is used(?)
-
Half-life precision (if supported by GPU) is really cool!
half=Truemakes stuff faster (no idea about prediction quality yet)- And batch size obviously
-
vid_stridepredicts every Nth video frame, was almost going to write that myself
All-in-all I like ultralytics/YOLO
-
-
Day 2207 (15 Jan 2025)
Git removing untracked broken files
TL;DR:
git clean -d -f .If a broken clone / switch leaves stray broken files:
error: The following untracked working tree files would be overwritten by checkout:, that fixes it.1
Kubernetes rancher magic pod yaml config to avoid shared memory crashes
I had exotic not enough shared memory crashes, ty GC for giving me these lines I do not yet understand but that seem to work, later I’ll dig into why (TODO)
apiVersion: v1 kind: Pod metadata: name: CHANGEME namespace: CHANGEME-ns spec: restartPolicy: Never containers: - name: sh-temp-yolo-container-3 image: ultralytics/ultralytics:latest command: ["/bin/sh", "-c"] args: - "yolo detect train model=yolo11s.pt data=/data/data/data.yaml project=/data/project/ epochs=30 imgsz=640 device=0,1" resources: requests: nvidia.com/gpu: "2" # GPUs for each training run ephemeral-storage: "12Gi" limits: nvidia.com/gpu: "2" # same as requests nvidia.com/gpu ephemeral-storage: "14Gi" volumeMounts: # Mount the persistent volume - name: data mountPath: /data - name: shared-memory mountPath: /dev/shm volumes: - name: shared-memory emptyDir: medium: Memory - name: data persistentVolumeClaim: claimName: sh-temp-yolo-pvcBoth
requestsANDlimits, as well as mount shared memory involumeMounts+volumes.
Adding wandb to a CLI yolo run
Assuming you’re doing a YOLO run w/
yolo detect train model=yolo11s.pt data=/data/data/data.yaml project=/data/project/ epochs=500 imgsz=640 device=0,1 name=yolo11s-aug-500epochs-fullnamethere becomes training run name in wandb + directory name in /data/projct- (project on wandb will be `-data-project-)
- To enable wandb:
pip install wandb yolo settings wandb=True wandb loginOr if you’re inside an ultralytics:latest Docker container,
apt install -y bash screen bash pip install wandb yolo settings wandb=True wandb login screen yolo detect train model=yolo11s.pt data=/data/data/data.yaml project=/data/project/ epochs=500 imgsz=640 device=0,1 name=yolo11s-aug-500epochs-fullAlso useful:
# get a model file wandb artifact get /proje:ject/run_alxxxpy7_model:v0 --root target_director/
-
Day 2203 (11 Jan 2025)
Python nested list comprehensions syntax
Nested list comprehensions are a horrible idea because they are hard to parse, and I never understood them, BUT.1
python - How do I make a flat list out of a list of lists? - Stack Overflow has a discussion in the accepted answer about the suggested syntax to flatten lists, and I get it now.
flat_list = [ x for xs in xss for x in xs ] # equivalent to flat_list = [] for xs in xss: for x in xs: flat_list.append(x)So,
[x for xs in xss for x in xs]Comments:
I found the syntax hard to understand until I realized you can think of it exactly like nested for loops. for sublist in l: for item in sublist: yield item
[leaf for tree in forest for leaf in tree]I kept looking here every time I wanted to flatten a list, but this gif is what drove it home: i.sstatic.net/0GoV5.gif
GIF IN QUESTION, after which it clicked for me:
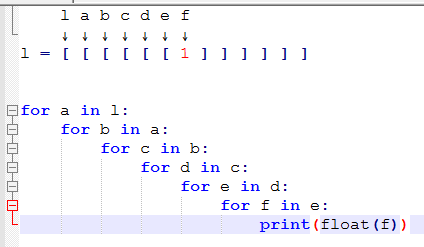
The first element is the one that gets returned!
for tree in forest: for leaf in tree: return leaf
[leaf (for tree in forest, for leaf in tree)]
[leaf (for tree in forest for leaf in tree)]
[leaf for tree in forest for leaf in tree]Found Understanding nested list comprehension syntax in Python — /var/ which expands on this, quoting PEP
It is proposed to allow conditional construction of list literals using for and if clauses. They would nest in the same way for loops and if statements nest now.
It then shows:
for x in non_flat: if len(x) > 2 for y in x: y # equivaent to >>> [ y for x in non_flat if len(x) > 2 for y in x ]MIND. BLOWN.
I’m not sure “this requires you to understand Python syntax” is an argument against using a given technique in Python This is about
itertools.chain(*list, which is the way to go imo. But still,*is python syntax, otherwise there are more or less readable ways to do thigs and nested comprehensions are rarely worth it
-
From comment to another answer in that same question that shames me: ↩︎
Poor-man's dark mode bits
- Qutebrowser:
:set colors.webpage.darkmode.enabled trueReally neat actually! ALSO:colors.webpage.preferred_color_scheme: darktells websites my preference - Nvim:
:colorscheme zaibatsu - Redshift:
redshift -r -P -O 4000 -b 0.3 - If I’m doing all that, I probably want to mute my speakers as well
Obsidian export HTML
For one-off HTML exports, found the plugin KosmosisDire/obsidian-webpage-export: Export html from single files, canvas pages, or whole vaults. Direct access to the exported HTML files allows you to publish your digital garden anywhere. Focuses on flexibility, features, and style parity.
It exports both the vault and individual pages, and adds things like toc on the left and toggles and optionally file browsing. Much better than the other pandoc-based export plugin that I could not get to work reliably for exporting good-looking HTML
-
-
Day 2201 (09 Jan 2025)
Git refuses to parse long paths on encrypted linux home
TL;DR clone to unencrypted directory
error: unable to create file datasets/processed/GitHub-Mensch-Animal_Finetuned/data/val/labels/1713256557366,hintergrund-meister-lampe-geht-das-licht-aus-vom-rueckgang-der-arten-tierische-und-pflanzliche-neubuerger-108~v-16x9@2dM-ad6791ade5eb8b5c935dd377130b903c4b5781d8.txt: File name too long
error: cannot stat ‘datasets/processed/GitHub-Mensch-Animal_Finetuned/data/val/images/1713256557366,hintergrund-meister-lampe-geht-das-licht-aus-vom-rueckgang-der-arten-tierische-und-pflanzliche-neubuerger-108~v-16x9@2dM-ad6791ade5eb8b5c935dd377130b903c4b5781d8.jpg’: File name too long
The usual solution1 is to set
longpaths = truein git config or during clone (git clone -c core.longpaths=true <repo-url>)Didn’t solve this for me.
BUT apparently my encrypted
$HOMEhas something to do with this, because filenames can get longer (?) in this case and go over the limit?.. git checkout-index: unable to create file (File name too long) - Stack OverflowAnd one solution is to clone to
/tmpor whatever is not encrypted by encryptfs.(And in my case I could rename these files in a commit in /tmp and after that it worked, as long as I don’t check out the revisions with the long filenames)
{kind=link}