serhii.net
In the middle of the desert you can say anything you want
-
Day 2646 (31 Mar 2026)
Translating pattern with LLMs
I know enough German to judge but not enough to write grammatically myself, and this is a pattern I don’t want to forget.

This is SO MUCH BETTER than anything else I’ve used for this! For very short snippets it’s golden
-
Day 2645 (30 Mar 2026)
LaTeX paper checklist
For the main file, see: 240116-1701 LaTeX best practices
Camera-ready checklist
- Enable reviewing mode in Overleaf
- Change package options
[review/final]etc. - Authors emails, names, order correct?
- Acknowledgements present and uncommented?
- Anonimity: uncensor names+URIs
- Are acknowledgements, references, appendices a) allowed, b) part of page limit?
- COMPRESSION: reconsider all hacks if you got more space for the camera-ready version
\setlength{\itemsep}{0pt} \setlength{\parskip}{0pt}and friends\setlength{\belowcaptionskip}{0}\setlength{\abovecaptionskip}{10pt}1 <- default values\looseness-1- Any paragraphs to un-merge for readability?
- Go through pre-flight checklist below
- Manually check ALL review-mode changes at the end!
Pre-flight checklist
- Ask LLMs to proofread! THEN do the steps below.
- Acknowledgements, references, appendices: a) allowed, b) count towards page limit?
- In which order?
- Anonymity: acknowledgements, again!
- Search for
TODOs in the text! - Consistency:
- When to use single/double quotes (quotes), when emphasis (foreign languages?)
- terminology?
- (including in captions and inside figures (labels, titles!))
- Table headers’ variables and names are easy to forget to update!
- Tables
- Did any footnote markers get deleted when pasting new data in tables?
- Adding
\bottomruleshelps if distance between table and caption too small
- Titles
- Title Case where needed (paper title + sections)
- Break the paper title in some pretty way
\mboxto avoid breaks,\-within word to mark break words
- Citations+references
- before periods and footnotes
- always w/ NBSP
- Double-check each reference, including inside table/figure captions!
- citep=cite, citet if subject, citealp in parentheses
- Don’t forget multiple citations
exist [1,3]!
- Commands/macros
- Search for
\TODOand any custom commands/macros you created - Check the spacing after any custom macros
- Search for
- Typography bits
- 231206-1501 Hyphens vs dashes vs en-dash em-dash minus etc
- Smart Quotes: Either `x’ and ``x’’ or
\enquote{}everywhere - Large Numbers: Write large numbers as 54{,}000.99
~is\textasciitilde: check any estimate numbers (~50%)!%is\%; check all percentages!\is\textbackslash- underscores, subscripts, superscripts are dangerous
- Avoid footnotes after numbers
- does minted caption use the same font as the rest?
-,--,---are the safest — look and remove pasted UTF8 ones
- NBSP (search and manually check each!)
- Citations,
\references (Figure~\ref{fig:somefig}) - TODO
- Citations,
- Look at logs!
Things that went wrong content-wise in the past
- Read through all analysis and tables, make sure the data makes sense, the analysis/results match the numbers in the tables, the plots and the tables match to each other.
- Make sure whatever you used to generate plots and tables used the exact same data!
-
Day 2643 (27 Mar 2026)
Tiny PRF demo program
I wrote this debugging some metrics, bad code but I don’t want it to die. Shows formulas for Precision/Recall/F-Score based on number of TP TN FP FN.
Depends only on rich, runnable w/ uv through 250128-2149 Using uv as shebang line.
Usage:
uv run prftset.py tp tn fp fn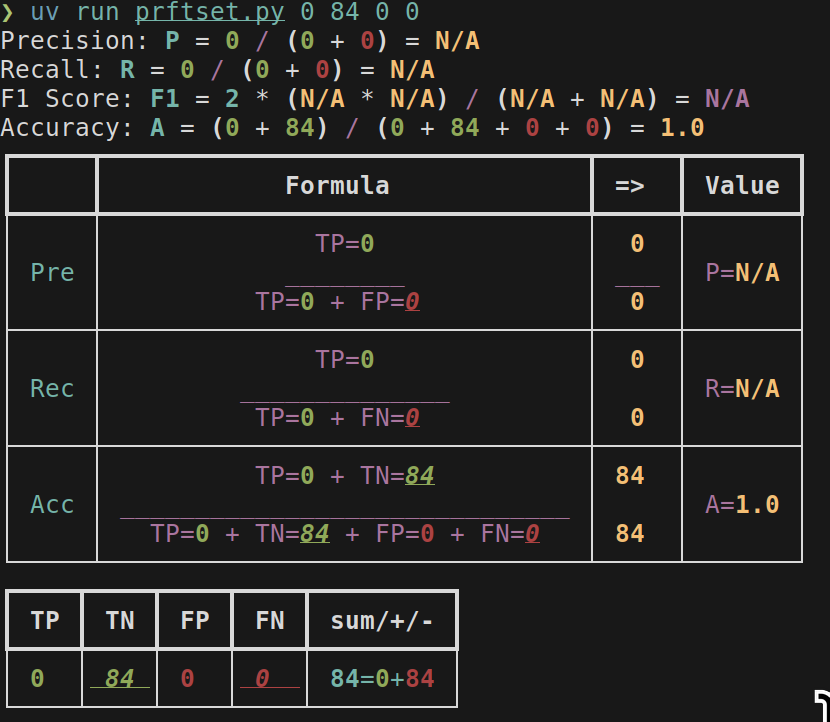
# /// script # dependencies = [ # "rich", # "pdbpp", # ви цього варті # ] # /// from rich import print from rich.layout import Layout from rich.table import Table import argparse def get_scores(tp, tn, fp, fn) -> dict[str, int | float | str | None]: """Calculate precision, recall, and F1 score from true positives, true negatives, false positives, and false negatives.""" precision = tp / (tp + fp) if (tp + fp) > 0 else None recall = tp / (tp + fn) if (tp + fn) > 0 else None f1_score = ( 2 * (precision * recall) / (precision + recall) if precision is not None and recall is not None and (precision + recall) > 0 else None ) accuracy = (tp + tn) / (tp + tn + fp + fn) if (tp + tn + fp + fn) > 0 else None f_precision = float(f"{precision:.3f}") if precision is not None else "N/A" f_recall = float(f"{recall:.3f}") if recall is not None else "N/A" f_f1_score = float(f"{f1_score:.3f}") if f1_score is not None else "N/A" total_ds = tp + tn + fp + fn res = { "TP": tp, "TN": tn, "FP": fp, "FN": fn, "total": total_ds, "P ": f_precision, "R ": f_recall, "F ": f_f1_score, "A ": float(f"{accuracy:.3f}") if accuracy is not None else "N/A", # "A ": accuracy, } return res def use_table(tp, tn, fp, fn, precision, recall, accuracy): total = tp + tn + fp + fn total_positive = tp + fn total_negative = tn + fp table_tn = Table() table_tn.add_column("TP", justify="center", style="green") table_tn.add_column("TN", justify="center", style="green underline italic") table_tn.add_column("FP", justify="center", style="red") table_tn.add_column("FN", justify="center", style="red underline italic") table_tn.add_column("sum/+/-", justify="right", style="cyan") table_tn.add_row( f"[bold green]{str(tp)}[/bold green]", f"[bold green]{str(tn)}[/bold green]", f"[bold red]{str(fp)}[/bold red]", f"[bold red]{str(fn)}[/bold red]", f"[bold cyan]{str(total)}[/bold cyan]=" + f"[bold green]{str(total_positive)}[/bold green]+" + f"[bold red]{str(total_negative)}[/bold red]", ) table = Table() table.add_column("", justify="right", style="cyan", no_wrap=True) table.add_column("Formula", justify="center", style="magenta") table.add_column("=>", justify="center", style="magenta") table.add_column("Value", justify="center", style="magenta") table.add_row( "", f"TP=[bold green]{str(tp)}[/bold green]", f"[bold yellow]{str(tp)}[/bold yellow]", "", ) table.add_row( "Pre", "_" * (len(str(tp)) + len(str(fp)) + 6), "___", f"P=[bold yellow]{precision}[/bold yellow]", ) table.add_row( "", f"TP=[bold green]{str(tp)}[/bold green] + FP=[bold red underline italic]{str(fp)}[/bold red underline italic]", f"[bold yellow]{str((tp + fp))}[/bold yellow]", "", ) table.add_section() table.add_row( "", f"TP=[bold green]{str(tp)}[/bold green]", f"[bold yellow]{str(tp)}[/bold yellow]", "", ) table.add_row("Rec", "______________", "", f"R=[bold yellow]{recall}[/bold yellow]") table.add_row( "", f"TP=[bold green]{str(tp)}[/bold green] + FN=[bold red underline italic]{str(fn)}[/bold red underline italic]", f"[bold yellow]{str((tp + fn))}[/bold yellow]", "", ) table.add_section() # Accuracy table.add_row( "", f"TP=[bold green]{str(tp)}[/bold green] + TN=[bold green underline italic]{str(tn)}[/bold green underline italic]", f"[bold yellow]{str((tp + tn))}[/bold yellow]", "", ) table.add_row( "Acc", "______________________________", "", f"A=[bold yellow]{accuracy}[/bold yellow]", ) table.add_row( "", f"TP=[bold green]{str(tp)}[/bold green] + TN=[bold green underline italic]{str(tn)}[/bold green underline italic] + FP=[bold red]{str(fp)}[/bold red] + FN=[bold red underline italic]{str(fn)}[/bold red underline italic]", f"[bold yellow]{str((tp + tn + fp + fn))}[/bold yellow]", "", ) print(table) print(table_tn) def pretty_scores(scores: dict[str, int | float | str | None], draw=True): tp, tn, fp, fn = scores["TP"], scores["TN"], scores["FP"], scores["FN"] precision, recall, f1_score = scores["P "], scores["R "], scores["F "] accuracy = scores["A "] # print( f"| TP: {scores['TP']}, TN: {scores['TN']}, FP: {scores['FP']}, FN: {scores['FN']} | ") # print( # f"| Precision: {scores['P ']}, Recall: {scores['R ']}, F1 Score: {scores['F ']} |" # ) print( f"Precision: [bold cyan]P[/bold cyan] = [bold green]{tp}[/bold green] / ([bold green]{tp}[/bold green] + [bold red]{fp}[/bold red]) = [bold yellow]{precision}[/bold yellow]" ) print( f"Recall: [bold cyan]R[/bold cyan] = [bold green]{tp}[/bold green] / ([bold green]{tp}[/bold green] + [bold red]{fn}[/bold red]) = [bold yellow]{recall}[/bold yellow]" ) print( f"F1 Score: [bold cyan]F1[/bold cyan] = 2 * ([bold yellow]{precision}[/bold yellow] * [bold yellow]{recall}[/bold yellow]) / ([bold yellow]{precision}[/bold yellow] + [bold yellow]{recall}[/bold yellow]) = [bold magenta]{f1_score}[/bold magenta]" ) print( f"Accuracy: [bold cyan]A[/bold cyan] = ([bold green]{tp}[/bold green] + [bold green]{tn}[/bold green]) / ([bold green]{tp}[/bold green] + [bold green]{tn}[/bold green] + [bold red]{fp}[/bold red] + [bold red]{fn}[/bold red]) = [bold yellow]{scores['A ']}[/bold yellow]" ) # use_layout(tp, tn, fp, fn, precision, recall) use_table(tp, tn, fp, fn, precision, recall, accuracy) def main(): args = parse_args() # Example usage # tp = 100 # tn = 50 # fp = 10 # fn = 5 tp = args.tp tn = args.tn fp = args.fp fn = args.fn scores = get_scores(tp, tn, fp, fn) pretty_scores(scores) def parse_args(): parser = argparse.ArgumentParser( description="Calculate precision, recall, and F1 score." ) # use positional arguments for tp, tn, fp, fn parser.add_argument("tp", type=int, help="True Positives", default=0) parser.add_argument("tn", type=int, help="True Negatives", default=0) parser.add_argument("fp", type=int, help="False Positives", default=0) parser.add_argument("fn", type=int, help="False Negatives", default=0) # parser.add_argument("--tp", type=int, required=True, help="True Positives") # parser.add_argument("--tn", type=int, required=True, help="True Negatives") # parser.add_argument("--fp", type=int, required=True, help="False Positives") # parser.add_argument("--fn", type=int, required=True, help="False Negatives") return parser.parse_args() if __name__ == "__main__": main()
-
Day 2605 (17 Feb 2026)
Killing Kubernetes pods without breaking stuff Rancher
- To force-kill pods w/o breaking k8s:
kubectl delete pod <> --now
Ty KM (https://github.com/kkmarv) for the following, quoting verbatim:
The expected behaviour of
kubectl deleteheavily depends on its arguments. There are 4 possible but wrongly documented options. I’ve tried to compile different sources into this list:kubectl delete pod <>will first send a SIGTERM, then a SIGKILL after X seconds (depends on the gracePeriods set by your pod)kubectl delete pod <> --grace-period=X(X>0) will first send a SIGTERM, then a SIGKILL after X secskubectl delete pod <> --nowis equivalent tokubectl delete pod <> --grace-period=1
There’s also
--force
Where things are possible to go wrong. It immediately deletes the pod from etcd, which will NOT kill the pod. It will too wait for the grace period before sending a SIGKILL. But even then it is not guaranteed that resources will be freed. There is even a warning inkubectl delete --helpabout this. Only use this when there is no other way to kill a pod.The force flag also allows to specify
--grace-period=0which will simply default to the grace period defined by the pod, effectively doing nothing since this is also the default behaviour.
- To force-kill pods w/o breaking k8s:
-
Day 2602 (14 Feb 2026)
Passing complex CLI params to Pydantic settings
Settings Management - Pydantic Validation is nice but doesn’t cover everything.
Passing
Nonethrough CLI- Settings Management - Pydantic Validation
Noneby default b/ccli_avoid_jsonis the default,[]
it will default to “null” if
cli_avoid_jsonisFalse, and “None” ifcli_avoid_jsonisTrue.Fun fact, works inside complex nested JSON flags as well.
Passing complex JSON-like fields incl. tuples
# Assume this class MySettingsClass(BaseSettings): I_am_a_list_of_tuples: list[tuple[str, str, str | None]] = Field( default=FILE_PAIRS, validation_alias=AliasChoices("fp", "file_pairs") ) FILE_PAIRS = [ ( "infer_doc_simplecriteria/pred_doc_simplecriteria.json", "merge_gold_simplecriteria/gold_simplecriteria.json", ), ( "file2-1", "file2-2", ), ]# Passing as a list of lists parses as a tuple # if done wrong the tuple is parsed as a list of strings uv run thing --I-am-a-list-of-tuples \ '"merge_gold_simplecriteria/gold_simplecriteria.json", "infer_doc_simplecriteria/pred_doc_simplecriteria.json"'
-
Day 2600 (12 Feb 2026)
Pydantic dumping model in json mode with serializable objects
TL;DR
pydanticmodel.model_dump(mode=>"json")Serialization - Pydantic Validation
To dump a Pydantic model to a jsonable dict (that later might be part of another dict that will be dumped to disc through
json.dump[s](..)):settings.model_dump() >>> {'ds_pred_path': PosixPath('/home/sh/whatever')} # json.dump... json.dumps(settings.model_dump()) >>> TypeError: Object of type PosixPath is not JSON serializable json.dumps(settings.model_dump(mode="json")) # works!
-
Day 2593 (05 Feb 2026)
JQ notes
Shorthand object contsuction
I kept googling for the syntax but could never find it again.
// long: '{user: .user, title: .titles}' // shorthand when key name matches original key name (user==.user) '{user, title}' // mix '{user, title_name: .title}'From the man page:
You can use this to select particular fields of an object: if the input is an object with “user”, “title”, “id”, and “content” fields and you just want “user” and “title”, you can write
{user: .user, title: .title}
Because that is so common, there´s a shortcut syntax for it:{user, title}.The long version allows to operate on they keys:
{id: .idx, metadata: .metadata.original_idx}
-
Day 2592 (04 Feb 2026)
Simple test to see if VLLM supports structured output
curl 127.0.0.1:8000/v1/chat/completions -s \ -H "Content-Type: application/json" \ -d '{ "model": "/data_pvc2/cache/models--CohereLabs--c4ai-command-r-08-2024/snapshots/96b61ca90ba9a25548d3d4bf68e1938b13506852/", "messages": [ { "role": "user", "content": "Generate a short analysis in the given JSON schema." } ], "response_format": { "type": "json_schema", "json_schema": { "name": "analysis_schema", "schema": { "type": "object", "properties": { "summary": { "type": "string" }, "importance_score": { "type": "number" }, "key_points": { "type": "array", "items": { "type": "string" } } }, "required": ["summary", "importance_score", "key_points"], "additionalProperties": false }, "strict": true } } }' | jq . > /tmp/outSample otuput:
{ "id": "chatcmpl-9c3932339c7d4e1bace32c24ef6dbada", "object": "chat.completion", "created": 1770201387, "model": "/data_pvc2/cache/models--CohereLabs--c4ai-command-r-08-2024/snapshots/96b61ca90ba9a25548d3d4bf68e1938b13506852/", "choices": [ { "index": 0, "message": { "role": "assistant", "reasoning_content": null, "content": "{\n \"summary\": \"This analysis focuses on the impact of marketing strategies on customer engagement and sales performance for a hypothetical e-commerce company.\",\n \"importance_score\": 0.85,\n \"key_points\": [\n \"Implemented an email marketing campaign with personalized recommendations based on past purchases: Increased open rates by 15% and contributed to a 12% rise in average order value.\",\n \"Launched an influencer marketing program on social media: Achieved a 20% growth in brand awareness and drove a significant rise in website traffic from social platforms.\",\n \"Optimised product listings through enhanced SEO techniques: Boosted organic visibility, resulting in a 25% increase in search-driven purchases.\",\n \"Implemented an automated email nurturing funnel for abandoned carts: Improved cart recovery rate by 10% and increased overall conversions.\",\n \"Analyzed customer reviews for product feedback and sentiment: Used insights to refine product strategies and enhance customer satisfaction.\"\n ]\n}", "tool_calls": [] }, "logprobs": null, "finish_reason": "stop", "stop_reason": null } ], "usage": { "prompt_tokens": 16, "total_tokens": 219, "completion_tokens": 203, "prompt_tokens_details": null }, "prompt_logprobs": null }To pretty-print the
contentit returned:jq -r .choices[0].message.content /tmp/out | jq .Simpler OpenAI-compatible JSON mode test
curl 127.0.0.1:8000/v1/chat/completions -s \ -H "Content-Type: application/json" \ -d '{ "model": "/data_pvc2/cache/models--CohereLabs--c4ai-command-r-08-2024/snapshots/96b61ca90ba9a25548d3d4bf68e1938b13506852/", "messages": [ { "role": "user", "content": "Return a JSON object with keys summary, importance_score (number), key_points (string array)." } ], "response_format": { "type": "json_object" } }'Bonus: literature
- Structured output Considered Harmful(tm)
- Some people STRONGLY disagree
-
Day 2551 (25 Dec 2025)
shredding entire directory recursively
security - How do I recursively shred an entire directory tree? - Unix & Linux Stack Exchange:
find <directory_name> -depth -type f -exec shred -v -n 1 -z -u {} \;
-
Day 2536 (10 Dec 2025)
Indico conference-event-etc. management system
TIL: Indico - Home, allegedly used by ScaDs and CERN, open sourcer
The effortless open-source tool for event organisation, archival and collaboration
Looks really really nice and professional