serhii.net
In the middle of the desert you can say anything you want
-
Day 2038 (31 Jul 2024)
You can enter svg code as html and animate graphviz like this
SO.
One can literally generate a plot w/ graphviz, export as svg, open and edit in inkscape, save as optimized svg, paste into quarto, and manually add the correct
class="fragment" data-fragment-index=4bits to the relevant groups.Insert with the usual {=html} thing.
Damn.
-
Day 2037 (30 Jul 2024)
leaderline.js in a neat library to draw arrows between HTML elements
almost works with quarto, except that line.position needs to be called on slide change — ergo likely won’t work in pdf export mode.
-
Day 2033 (26 Jul 2024)
Animating plots in quarto
maurosilber/pyfragments: Animated figures for Quarto installs as-is
IT WORKS FOR PDF MODE TOO! And uses fragments
# | fig-width: 15 # | fig-height: 10 # | output: asis import matplotlib.pyplot as plt from pyfragments import AnimatedFigure with AnimatedFigure() as ani: # Data for plotting train_loss = [1.0, 0.6, 0.3, 0.2, 0.1] val_loss = [1.2, 0.8, 0.5, 0.4, 0.6] iterations = [1, 2, 3, 4, 5] plt.xlim(0, 6) plt.ylim(0, 1.5) # Labels and legend plt.xlabel('Trainingsiterationen', fontsize=14) plt.ylabel('Loss', fontsize=14) plt.legend(loc='upper right', fontsize=12) # Plot for x in range(len(train_loss)+1): with ani.fragment(): plt.plot(iterations[:x], train_loss[:x], 'bo-', label='Training', linewidth=2) plt.plot(iterations[:x], val_loss[:x], 'go-', label='Validation', linewidth=2) # Add a dashed vertical line in the middle mid_iteration = (iterations[0] + iterations[-1]) / 2 with ani.fragment(): plt.axvline(x=mid_iteration, color='r', linestyle='--', linewidth=1.5)
-
Day 2031 (24 Jul 2024)
Quarto sizes of graphviz etc figures
I couldn’t make a graph large enough to fill the screen, increasing fig-width didn’t help.
Solution: increase both fig-width and fig-height!
{dot} //| fig-width: 12 //| fig-height: 9 digraph G { rankdir=LR; ..Execution Options – Quarto has figure options that lists the default sizes of figures based on output formats. Couldn’t find them because was looking in figures/graphviz etc. pages, not execution. …
For reveal slides, it’s 9 x 5.
Apparently it didn’t want to increase the 5 till I explicitly told it to, then width started increasing as well.
Both superscripts and subscripts
… are hard and you have to use a table.
digraph Neural_Network { rankdir=LR; ranksep=1.3; node [shape=circle, style=filled, fontcolor=white, fontsize=25, fillcolor="blue", color="black"]; subgraph cluster_0 { node [fillcolor="#2c3e50", style="filled"]; x1 [label=< <TABLE border="0" cellborder="0" cellspacing="0"> <TR><TD rowspan="2" style="...">X</TD><TD style="...">1</TD></TR> <TR> <TD style="...">1</TD></TR> </TABLE>>]; x2 [label=< <TABLE border="0" cellborder="0" cellspacing="0"> <TR><TD rowspan="2" style="...">X</TD><TD style="...">1</TD></TR> <TR> <TD style="...">2</TD></TR> </TABLE>>]; } sum [label=<∑<FONT color="yellow" point-size="10">(⎰)</FONT>>, fillcolor="#27ae60", width=0.8, height=0.8, fixedsize=true]; y [label=<y<sup>1</sup>>]; edge [style=solid, color="#2c3e50"]; x2 -> sum; x1 -> sum; edge [style=solid, color="#27ae60"]; sum -> y; {rank=same; x1; x2;} }
-
Day 2029 (22 Jul 2024)
Notes on annotating nii 3d files
Misc
- Papers
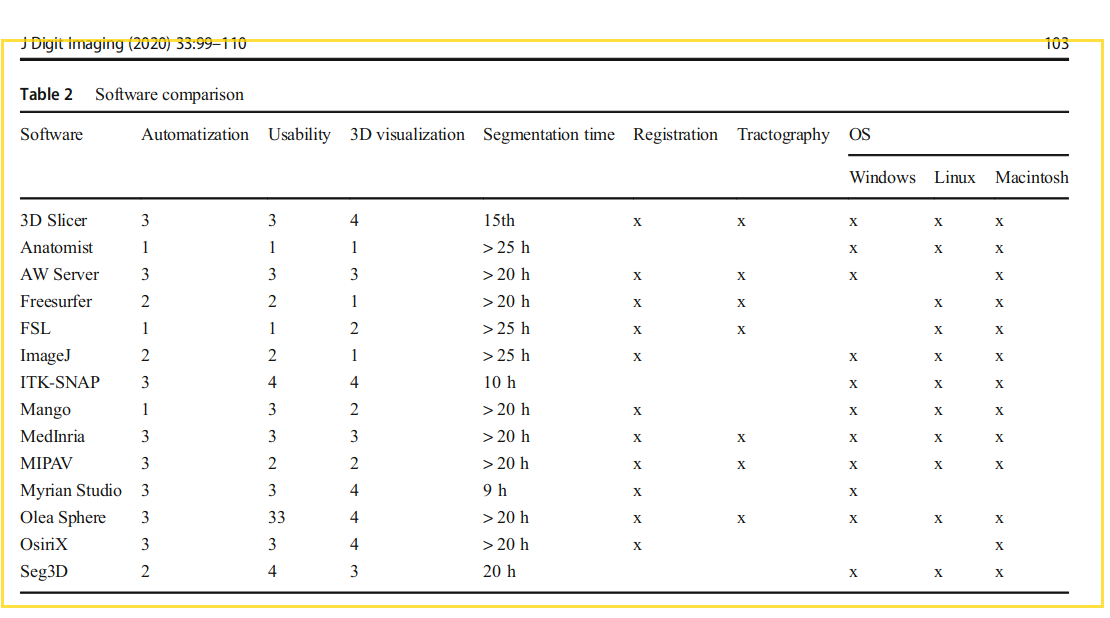
- Comparison of Three 3D Segmentation Software Tools for Hip Surgical Planning - PMC: compares 3d slicer, Syngo, and Materialize1
-
- Comprehensive Review of 3D Segmentation Software Tools for MRI Usable for Pelvic Surgery Planning - PMC2: 12 software tools
- really nice criteria, incl. extensibility etc.
-
-
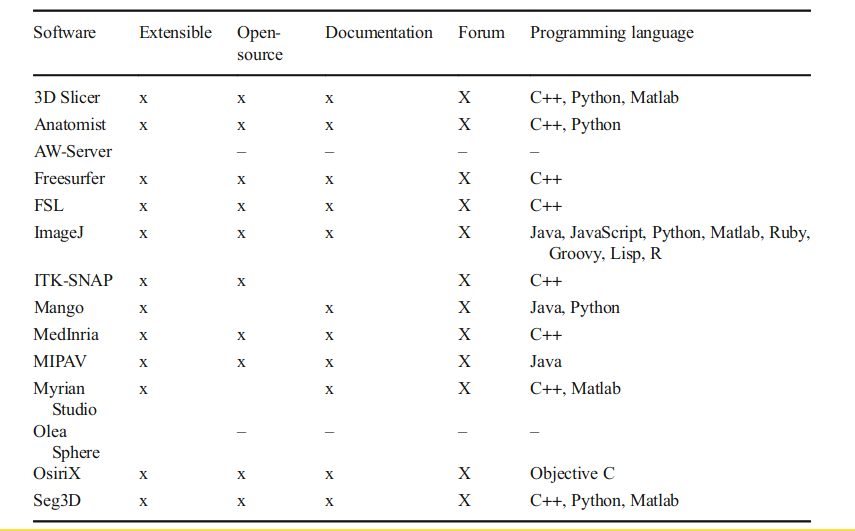
- TL;DR: ITK-SNAP most usable, Myrian Studio second but windows-only, 3d Slicer third but neat because easily extendable. Seg3d as also mentioned as aving very good usability
- Comparison of Three 3D Segmentation Software Tools for Hip Surgical Planning - PMC: compares 3d slicer, Syngo, and Materialize1
- Misc
- https://github.com/neurolabusc/niivue-images sample nii images for evaluating nii viewers/editors
+ 3d Slicer
- Main file: 240715-1653 Notes on 3d-slicer, 240718-1530 First python 3d slicer interactions
- License:
- About 3D Slicer — 3D Slicer documentation
- custom license: BSD-style, broadly open source
- no GPL/copyleft code allowed because it’d make it harder to mix slicer w/ private intellectual property
- commercial use OK
- 3d slicer based products — only some are listed, because one can use it and not disclose it and it’s fine
- Language: python
- extensible in python as well
- has many cool extensions: @KitwareMedical/slicer-extensions-webapp
- includes MONAILabel active learning extension plugin
- a whole category for developer tools! @KitwareMedical/slicer-extensions-webapp
- Extension Wizard — 3D Slicer documentation
- https://extensions.slicer.org/catalog/Shape Analysis/32952/linux has extensions about stats
- ai-assisted-annotation-client/slicer-plugin/README.md at master · NVIDIA/ai-assisted-annotation-client
- Very active community and frequent updates
- Downsides
- J:
- too specific for medical images
- presets hard to customize (I agree!)
- bad documentation (I think fixed now)
- but: “Best of the free ones”
- J:
- Ha: https://github.com/NVIDIA/ai-assisted-annotation-client/blob/master/slicer-plugin/README.md
+ Syngo
- syngo.via OpenApps – Siemens Healthineers Deutschland
- Paid.
- Best according to 1
- No easy way to test.
MeVisLab
- https://www.mevislab.de/
- Commercial and non-commercial version available
- Documentation:
- SDK for scripting exists
- python QT bindings available
- and generally feels expandable w/ python, shows python errors in the main screen for example, which is a good sign
- Official video tutorials exist, incl. for application development: MeVisLab - YouTube
- Download: a single .bin file that has to be run
- I don’t really like the website but the program itself feels nice!
- Nice pipeline visualization:
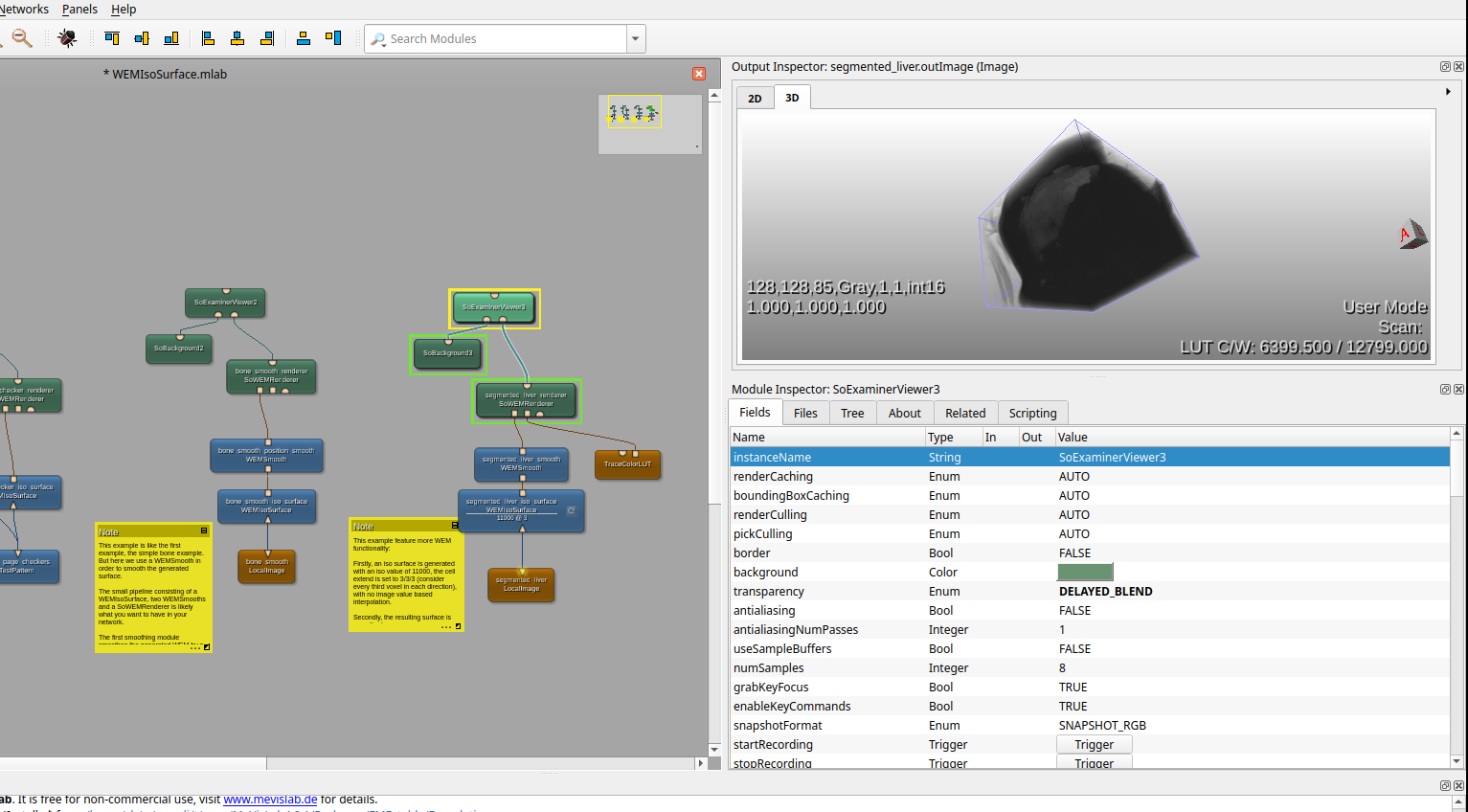 and adding blocks — much less chaotic than 3d slicer (at first glance)
and adding blocks — much less chaotic than 3d slicer (at first glance) - overall good impression
- python scripting has a nice reference etc.
ITK-SNAP
- TODO
- Winner of 2 due to its usability, does segmentation only but does it well
- available on AUR
- tutorial: TutorialSectionVolumes
- I really like it as first impression
- Has a distributed segmentation service already implemented!
- ITK-SNAP Distributed Segmentation Services
-

- ASHS Documentation - Overview sample of such a service
- (can’t test it because pyqt6 present but not found)
- has volumes and statistics, maybe expandable
- BUT can’t find easy ways to add plugins
+ 3D Seg
- Open Source, segmentation-first
- for linux has to be compiled from source
- last meaningful commits from ~3 years ago: Commits · SCIInstitute/Seg3D, last release 2021 as well
- tried to build it, as ./build, failed because can’t find svn for
- Has detailed-ish developer documentation as videos! https://www.sci.utah.edu/cibc-software/seg3d.html
- Couldn’t build locally sadly, error in the middle of it
- Giving up
Myrian
- commercial, but non-commercial exists, and can be extended with plugins
NeuroMorph
- NeuroMorph ‐ EPFL
- Blender-based!
-
NeuroMorph is a set of tools designed to import, analyze, and visualize mesh models in Blender. It has been developed specifically for the morphological analysis of 3D objects derived from serial electron microscopy images of brain tissue, but much of its functionality can be applied to any 3D mesh.
ilastic
- ilastik - ilastik
- integrat-able with fiji: ilastik/ilastik4ij: ImageJ plugins to run ilastik workflows and with everything else
- BioImage.IO integration as well, btw another model zoo
Fiji
- Fiji: ImageJ, with “Batteries Included”
- Legendary
- infinite plugins, very well known, downloadable as executable
- not too easy to use in my subjective opinion, menus inside menus, but…
Kitware glance
https://kitware.github.io/glance/doc/index.html
Biaflows
- https://biaflows-sandbox.neubias.org/#/
- fully-online and can run models
- I don’t like the 3d viewer and I think it’s segmentation only, no easy way to generate/show stats
-
Comparison of Three 3D Segmentation Software Tools for Hip Surgical Planning - PMC: compares 3d slicer, Singo, and Materialize ↩︎ ↩︎
-
Comprehensive Review of 3D Segmentation Software Tools for MRI Usable for Pelvic Surgery Planning - PMC ↩︎ ↩︎
Git config commentchar for commits starting with hash
Commit messages starting with
#14 whateverare awkward as#is the default comment in git rebase and friends.git config core.commentchar ";"fixes that for me.
For a one-time thing this works as well:
git -c core.commentChar="|" commit --amend(escaping - Escape comment character (#) in git commit message - Stack Overflow)
- Papers
-
Day 2025 (18 Jul 2024)
First python 3d slicer interactions
Why is the number of voxels different from the number of matrices? - Support - 3D Slicer Community
>>> raw = getNode('probe1_0000.nii.gz') >>> slicer.util.arrayFromVolume(raw).shape (180, 180, 500) >>>doesn’t work for segmentations because not a volume.
Image dimensions can be seen from volume information And are identical in both segmentations and original
I found smoothing in view controllerS!
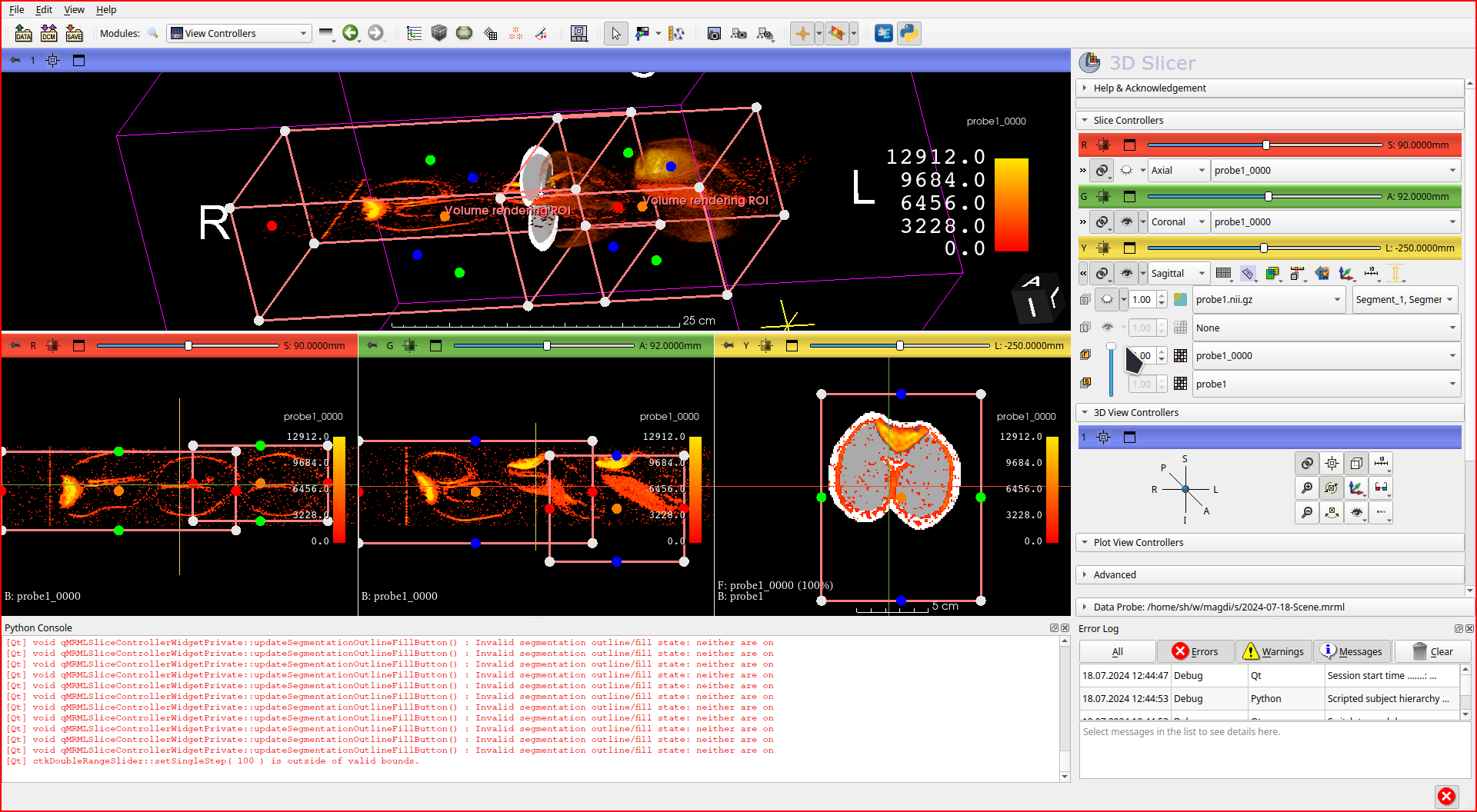
In Slice controllers there’s this arrow button that allows to set basically layers AND SMOOTHING per slice!
So everything is as expected wrt smoothing — there was none.
Zooming in slices w/ CTRL!
-
Day 2022 (15 Jul 2024)
Notes on 3d-slicer
// ref: 240701-1752 NII MRI annotation tools
- 3D Slicer image computing platform | 3D Slicer
- DICOM seems primary format1 but nifti is supported
- Installing from AUR
-
Importing 2x .nii as directory worked as-is
-
Volumes can do settings per file, incl.:
- annotations threshold starts at 1
-
Volume renderings gives 3d views?
-
Annotations can be imported as annotations/segmentations through add data! Then they are parsed semantically
-
One can segment N slices and it magically creates a 3d shape out of it!
-
Exporting annos as nifti possible through “export” in Segmentation module 2(not Segment Editor!)
- https://www.youtube.com/watch?v=CxwxYtizdhE resampling volumes
-
Formats (NITRC: dcm2nii: MainPage)
- DICOM is the medical lingua franca, scientific apps like nifti. Additionally,
The DICOM standard is very complex, and different vendors have interpreted it differently. Accurate conversion to NIfTI format requires reading the vendor’s private tags.
- DICOM is the medical lingua franca, scientific apps like nifti. Additionally,
-
Save a DICOM Data as a Nifti - Support - 3D Slicer Community ↩︎
-
Day 2019 (12 Jul 2024)
Notes on GraphViz
Basics
Graphviz Online is a really nice viewer
Grouping
- You can set attributes globally or per subgraph
edge [color="white"]makes all child edges white, unless overwritten
Labeling things
I figured out this way to label different ranks by using an invisible pseudo-graph: viewer
This is the chunk:
subgraph labels { edge [fontcolor="black"]; node [style="filled", fontcolor="black", fontsize=10]; node1 [label="Inputs"]; node2 [label="Weights"]; node3 [label="Sum"]; node4 [label="Activation\nfunction"]; node5 [label="Output"]; node1 -> node2 -> node3 -> node4 -> node5; {rank=same; node1;n0;n1; n2; n3;} {rank=same; node3;sum;} }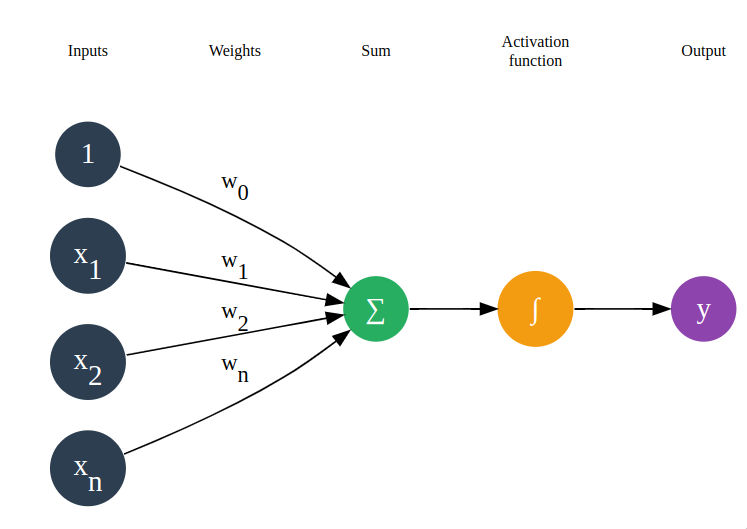
Note using ranks to align inputs/sum to the correct level; also the use of
\nin the label.Adding labels under nodes
xlabel, and use HTML to make it a diff color than the main label. dot - Graphviz: Putting a Caption on a Node In Addition to a Label - Stack Overflow Graphviz: Distinct colors for xlabel and nodelabel - Stack Overflow
Hovercode is the best QR code generator, DDG second
- The very best QR code generator is https://hovercode.com/
- DuckDuckGo can generate simple ones as well:
qr https://www.eff.org/at DuckDuckGo